
Switching between OpenAI, Anthropic, and Google Gemini shouldn’t feel like reprogramming your entire app from scratch. Yet too many teams are stuck doing exactly that-because every LLM provider has its own API format, its own way of handling prompts, and its own quirks in how it responds. The result? Vendor lock-in, ballooning costs, and unpredictable behavior when you try to swap models. But there’s a better way. Interoperability patterns exist to abstract these differences away, letting you treat all LLMs like interchangeable parts. You don’t need to rewrite your code every time a new model launches or your budget shifts. You just need the right architecture.
Why Abstract LLM Providers at All?
It’s not just about avoiding vendor lock-in. It’s about survival. In 2025, companies that rely on a single LLM provider are playing Russian roulette with their AI workflows. OpenAI might raise prices overnight. Anthropic might throttle your API keys during peak hours. Google Gemini might change its response format without warning. If your app breaks every time one of those happens, you’re not building AI-you’re building fragile scripts.
Real teams are already feeling this. One startup in Seattle cut its LLM costs by 35% by switching from OpenAI to Anthropic during high-traffic periods-without touching a single line of application code. How? They used LiteLLM. Another healthcare company in Boston reduced manual data entry by 63% using FHIR-GPT, which normalizes clinical notes into standardized medical records across different models. These aren’t edge cases. They’re the new baseline.
The goal isn’t to pick the “best” model. It’s to build systems that can adapt. That means abstracting the provider layer so your app doesn’t care whether it’s talking to GPT-4o, Claude 3.5, or a self-hosted Llama 3.8. The abstraction handles the noise. Your logic handles the value.
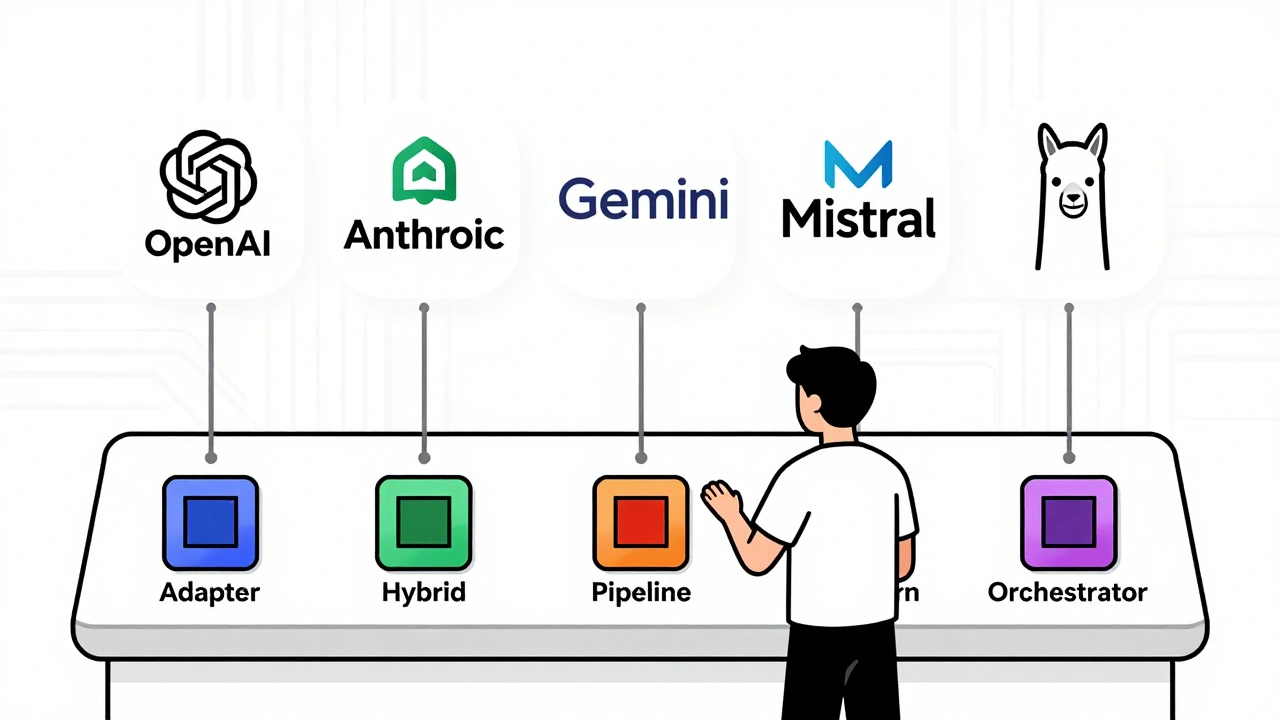
The Five Proven Patterns for LLM Interoperability
Five patterns have emerged as the most effective for scaling LLM integrations without chaos. Each solves a different problem-and most teams use a mix of them.
Adapter Integration is the simplest. Think of it like a power strip that converts European plugs to American outlets. LiteLLM is the most popular implementation. It wraps every major LLM provider-OpenAI, Anthropic, Gemini, Mistral, and over 100 others-into a single, consistent API that looks exactly like OpenAI’s. One line of code change, and you’re swapping models. No retraining. No rewriting prompts. Just switch the model name in your config file and go. Newtuple Technologies found this cuts integration time by 70% compared to custom API wrappers.
Hybrid Architecture combines monolithic LLM calls with microservices. You keep your core inference on a fast, reliable provider like Anthropic, but route auxiliary tasks-like fetching user data, caching responses, or enriching prompts with external documents-to lightweight services. This reduces cost by up to 40% because you’re not paying premium rates for simple tasks. It also improves reliability: if the main LLM goes down, your caching layer can still serve recent responses.
Pipeline Workflow breaks down complex tasks into steps, each handled by the best-suited model. Need to extract data from a PDF? Use a model optimized for document parsing. Need to summarize it? Switch to one with a long context window. Need to answer follow-up questions? Use a model with strong reasoning. LangChain excels here, letting you chain these steps together with prompts, tools, and memory buffers. But it’s complex. You’re not just switching providers-you’re designing an AI workflow engine.
Parallelization and Routing sends the same request to multiple models at once, then picks the best result. This isn’t about speed-it’s about accuracy. One model might be better at math. Another at code. A third at understanding medical jargon. By running them in parallel and using a simple voting or scoring system, you reduce errors. A team at a fintech firm used this to cut hallucination rates in financial reports by 52%. But it triples your API costs. Only use this for mission-critical tasks.
Orchestrator-Worker is for enterprise-scale systems. You have one central controller (the orchestrator) that routes tasks to specialized workers-each running a different model or fine-tuned version. The orchestrator handles authentication, rate limiting, fallbacks, and logging. This is what companies like Mozilla.ai are building with their “any-llm” and “any-agent” fabric. It’s heavy, but it’s the only way to manage hundreds of models across dozens of teams without chaos.
LiteLLM vs LangChain: Which One Do You Actually Need?
Most people start here: “Should I use LiteLLM or LangChain?” The answer depends on how much complexity you’re willing to carry.
LiteLLM is a thin layer. It doesn’t try to do everything. It just normalizes the API. You send a request like:
completion(model="claude-3-5-sonnet", messages=[{"role": "user", "content": "Summarize this"}])And LiteLLM translates that into Anthropic’s format behind the scenes. No learning curve. No new concepts. Just drop it in, change your model name, and go. Developers report getting up and running in 8-12 hours. If your goal is cost savings, avoiding rate limits, or testing models quickly-this is your tool.
LangChain is a framework. It lets you build agents, memory chains, tools, and retrieval systems. You can connect it to databases, web scrapers, calculators, and custom functions. But that power comes at a cost. Setup takes 40+ hours. Documentation is dense. You’ll spend days debugging why your agent isn’t remembering context or why a tool call failed. G2 users give it 4.2/5, but 40% of reviews mention “steep learning curve.” Use LangChain if you’re building a full AI assistant, not just swapping models.
Here’s the truth: 80% of teams don’t need LangChain. They just need to switch models without breaking things. LiteLLM does that. LangChain does that too-but it’s like using a bulldozer to open a door.
The Hidden Problem: Behavioral Inconsistency
Here’s where most teams fail. They think interoperability is just about APIs. It’s not. It’s about behavior.
Newtuple Technologies tested two models-Model A and Model B-with identical code and prompts. Model A successfully extracted complex figures from scattered tables by improvising data joins. Model B, with the same code, failed. Why? Model B followed instructions too strictly. It didn’t infer. It didn’t adapt. It just did what it was told.
This isn’t a bug. It’s a feature of how models are trained. One might be optimized for creativity. Another for precision. One might hallucinate facts. Another might refuse to answer unless it’s 99% sure. If you swap them without testing, your app might go from 95% accuracy to 73%-and you won’t know why until your users complain.
Professor Michael Jordan at UC Berkeley put it bluntly: “Interoperability standards must address behavioral consistency, not just API compatibility.”
That’s why the Model Context Protocol (MCP) from Anthropic matters. It doesn’t just standardize how you call a model. It standardizes how you connect it to tools, data sources, and memory. MCP 1.1, released in October 2024, reduced integration time by 35% because it removed guesswork. Now, if your app expects a tool to return JSON in a certain format, it will-no matter which model you’re using.
But MCP is just one piece. Mozilla.ai’s “any-evaluator” tools, announced in November 2024, aim to solve the rest: consistent performance measurement across models. Until you can measure accuracy, safety, and reliability the same way for every model, swapping them is still risky.
Real-World Implementation: What Works Today
Let’s say you’re building a customer support bot that pulls data from internal docs and answers questions in real time. Here’s what a working setup looks like in 2025:
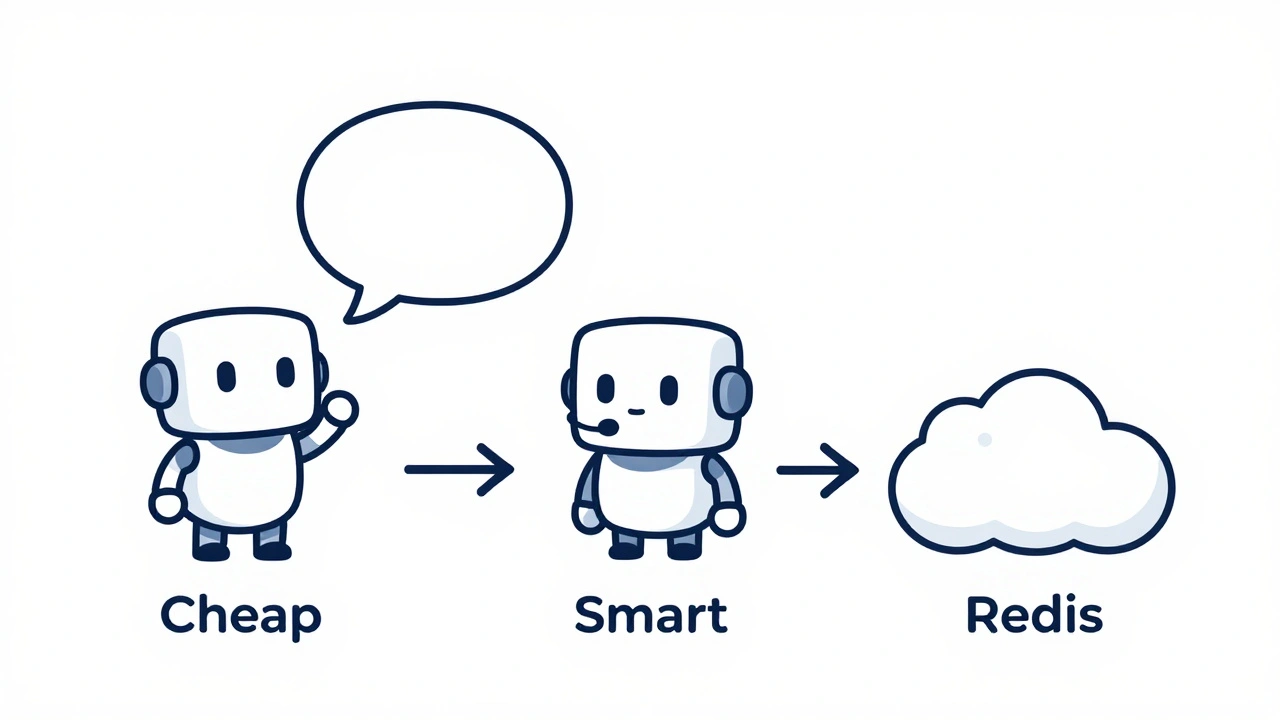
- Use LiteLLM to wrap OpenAI, Anthropic, and Mistral into one endpoint.
- Route simple queries to Mistral (cheaper, faster) and complex ones to Claude 3.5 (better reasoning).
- Cache responses for common questions using Redis to reduce cost and latency.
- Use a simple scoring system: if two models agree on an answer, trust it. If they disagree, flag it for human review.
- Log every request and response, including model used, latency, and confidence score.
This setup costs 30% less than using only OpenAI. It’s 50% more reliable than using one model. And it took a single engineer two weeks to build.
Healthcare is leading the way. FHIR-GPT, a tool built on this model, achieves 92.7% exact match accuracy converting clinical notes into standardized medical records. That’s not just convenient-it’s life-saving. And it works because the team didn’t try to make one model do everything. They used the right tool for each step.
What’s Coming Next
By 2026, Gartner predicts 75% of new enterprise LLM deployments will use multi-provider strategies. Why? Because the EU AI Act now requires documentation of model switching procedures for high-risk applications. Insurance companies, banks, and hospitals can’t afford to be locked in.
Open-source tools like LiteLLM and LangChain will keep improving. ONNX 1.16, released in September 2024, lets you convert models between frameworks 28% faster. That means you can fine-tune a model on your data, then deploy it across providers without retraining.
But the biggest shift won’t be technical. It’ll be cultural. Companies are starting to demand interoperability as a requirement-not a bonus. “Let model providers compete on speed, accuracy, safety and price,” wrote DC Journal in May 2024. “But don’t let them compete on incompatibility.”
That’s the future. You don’t choose a model. You choose a system that lets you choose any model-and switch when you need to.
What’s the easiest way to start abstracting LLM providers?
Start with LiteLLM. Install it with pip, replace your OpenAI calls with LiteLLM’s equivalent, and swap model names in your config. No code rewrite needed. Most teams get it running in under a day.
Can I use these patterns with self-hosted models like Llama 3?
Yes. LiteLLM supports over 100 providers, including local models via OpenAI-compatible APIs like vLLM or Ollama. You just point LiteLLM to your local endpoint, and it treats it like any other provider.
Does abstracting LLM providers slow down responses?
Minimal impact. LiteLLM adds less than 10ms of overhead. Hybrid architectures might add latency if you’re calling external services, but caching and parallel routing can actually speed things up by reducing retries and fallbacks.
What’s the biggest risk when switching LLM providers?
Behavioral differences. A model that’s great at summarizing might fail at code generation. Always test with real-world prompts before going live. Use tools like Mozilla.ai’s upcoming “any-evaluator” to measure consistency across models.
Is this only for big companies?
No. Even solo developers use LiteLLM to avoid OpenAI’s pricing changes. One indie maker in Bellingham reduced his monthly LLM bill from $1,200 to $400 by switching to Mistral during off-hours. Interoperability isn’t enterprise-only-it’s smart.
 Artificial Intelligence
Artificial Intelligence


michael Melanson
December 13, 2025 AT 04:29LiteLLM is the quiet hero of modern LLM ops. I switched our support bot from OpenAI to Mistral last quarter and didn’t touch a single line of application logic. Just updated the model name in the config. Cost dropped 40%. No drama. No panic. Just better margins.
lucia burton
December 13, 2025 AT 15:52Let’s be real-most teams treating LLMs like interchangeable components are still living in a fantasyland. Sure, LiteLLM normalizes the API calls, but the behavioral variance between models is not a bug, it’s a feature of their training regimes. One model hallucinates because it’s optimized for creativity, another refuses to answer because it’s been fine-tuned for compliance. You can’t abstract away the epistemological divergence between models just by wrapping their endpoints. The real challenge isn’t API parity-it’s output consistency across inference paradigms. Until we have a standardized behavioral contract like MCP 1.1 adopted universally, we’re just decorating the same fragile house with different wallpaper.
And don’t get me started on LangChain. People think it’s a framework, but it’s actually a dependency graveyard. I’ve seen teams spend six weeks debugging memory leaks in their agent chains only to realize they didn’t need an agent at all. Sometimes a simple prompt template and a Redis cache is all you need. Stop overengineering. Start underdelivering with reliability.
Denise Young
December 13, 2025 AT 18:34Oh wow, so now we’re pretending that switching LLMs is as easy as swapping out a lightbulb? 🤦♀️
Let me guess-your ‘working setup’ in 2025 includes a scoring system that ‘flags disagreements for human review.’ Translation: you’re paying humans to be the fallback for models that can’t even agree on whether ‘2+2=4’ is a safe answer.
And you call this innovation? This is just vendor roulette with extra steps. You’re not abstracting providers-you’re abstracting responsibility. The real MVP here is the engineer who has to manually audit every third response because ‘Model A said yes, Model B said maybe, and Model C just made up a citation from a journal that doesn’t exist.’
Meanwhile, the EU AI Act is breathing down your neck and you’re still using a ‘scoring system’ like it’s a magic wand. Wake up. Interoperability isn’t about API wrappers. It’s about accountability. And right now, nobody’s accountable for when the AI hallucinates a patient’s diagnosis.
Sam Rittenhouse
December 15, 2025 AT 13:14I’ve been on both sides of this. I used to work at a startup where we were locked into OpenAI because we didn’t know any better. We were bleeding money, our uptime was shaky, and every time they changed something, our whole system broke. Then we found LiteLLM.
It didn’t fix everything. But it gave us breathing room. We started routing low-priority queries to Mistral, kept Claude for medical summaries, and used Redis to cache answers for common questions. It wasn’t perfect. But it was *ours*. We weren’t at the mercy of one company’s pricing or API changes anymore.
And honestly? The biggest win wasn’t the cost savings. It was the peace of mind. When your app doesn’t crash because a model provider had a bad day, you stop treating AI like a black box and start treating it like a tool. That shift-seeing AI as something you can manage, not something that manages you-is what really matters.
To every solo dev, every small team, every overworked engineer reading this: you don’t need to build an AI orchestra. You just need one good conductor. LiteLLM is that conductor.
Peter Reynolds
December 16, 2025 AT 14:15