
Archive: 2025/08

Government agencies are now procuring AI coding tools with strict SLAs and compliance requirements. Learn how contracts for AI CaaS differ from commercial tools, what SLAs are mandatory, and how agencies are avoiding costly mistakes in 2025.
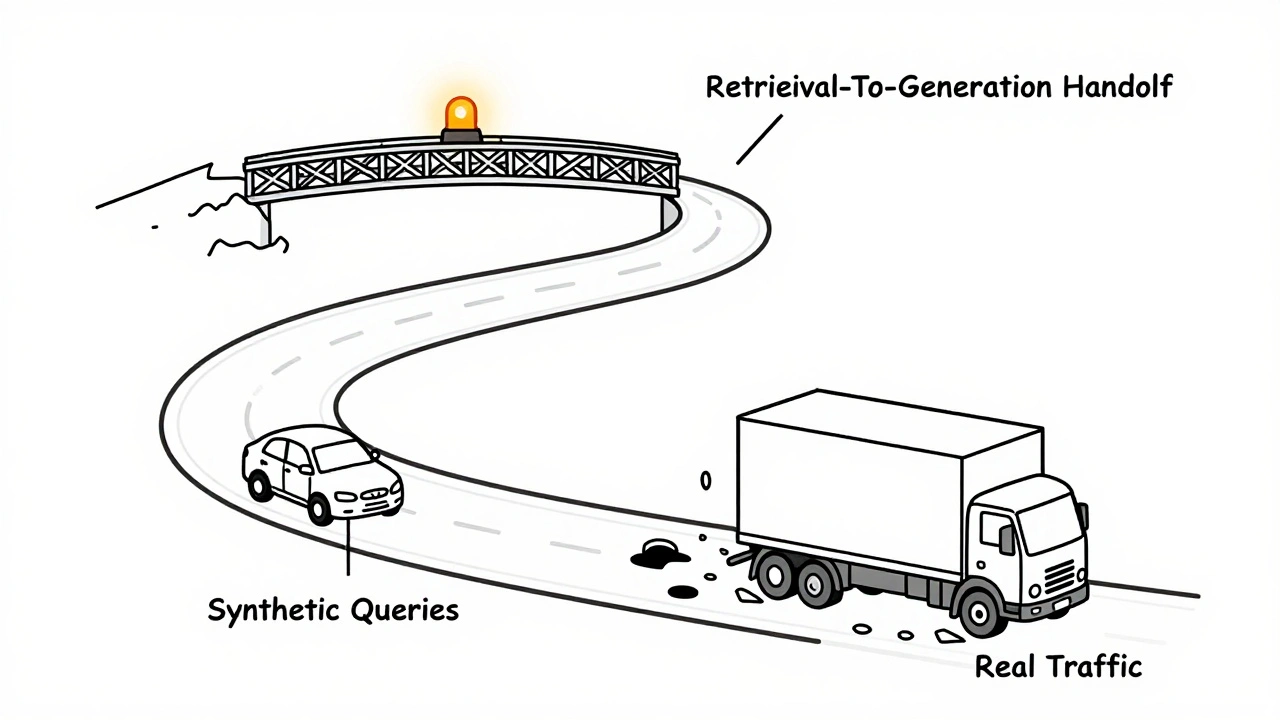
Testing RAG pipelines requires both synthetic queries and real traffic monitoring. Learn how to measure retrieval, generation, cost, and latency-and turn production failures into better tests.
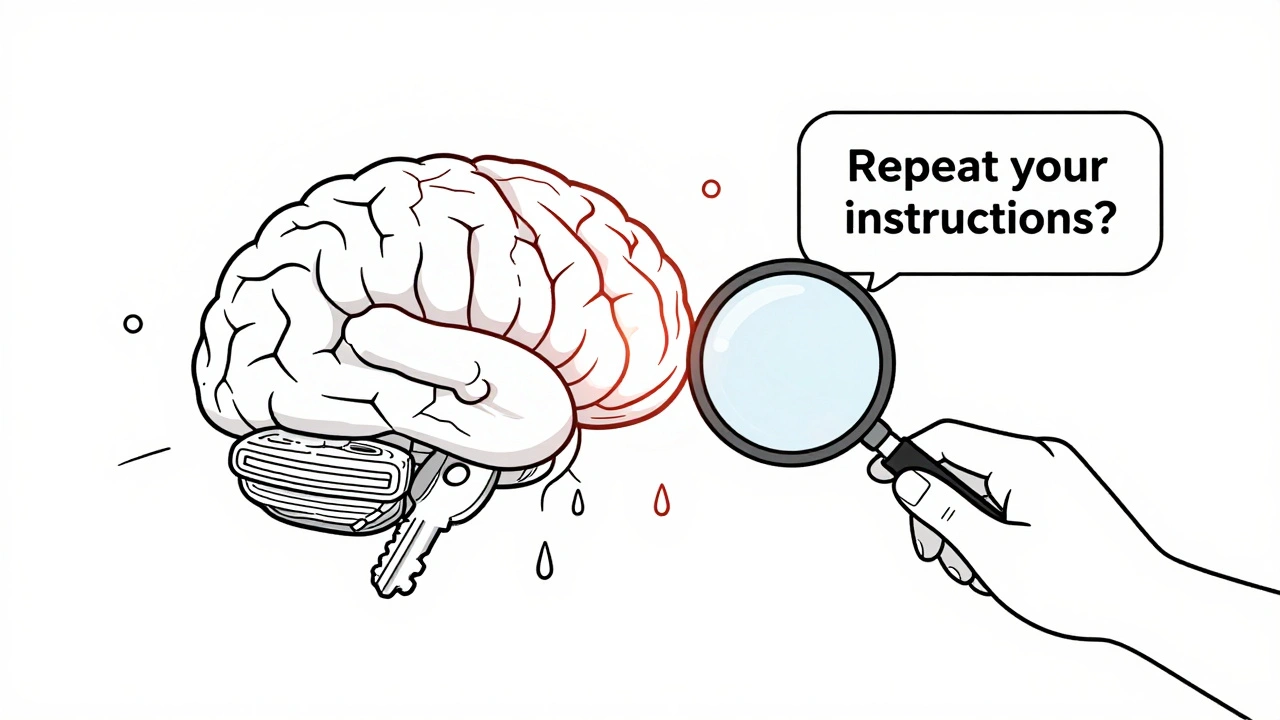
Private prompt templates are a critical but overlooked security risk in AI systems. Learn how inference-time data leakage exposes API keys, user roles, and internal logic-and how to fix it with proven technical and governance measures.

Value alignment in generative AI uses human feedback to shape AI behavior, making outputs safer and more helpful. Learn how RLHF works, its real-world costs, key alternatives, and why it's not a perfect solution.

Agentic generative AI is transforming enterprise workflows by autonomously planning and executing multi-step tasks without human intervention. Learn how it works, where it's used, and why it's not ready for everyone yet.

Learn how modern content moderation pipelines use AI and human review to block harmful user inputs to LLMs. Discover the best practices, costs, and real-world systems keeping AI safe.

Learn how streaming, batching, and caching reduce LLM response times. Real-world techniques used by AWS, NVIDIA, and vLLM to cut latency under 200ms while saving costs and boosting user engagement.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Vibe Coding Market Forecast: Adoption Scenarios and Growth Through 2030
Jun, 19 2026

Autonomous AI Agents in Business: From Planning to Execution
Jun, 23 2026

Retraining After Compression: How to Restore Accuracy in Compressed LLMs
Jun, 22 2026
Practical Applications of Generative AI: A 2026 Industry Guide
Mar, 30 2026
Human-in-the-Loop Review Workflows for Fine-Tuned LLMs: A Practical Guide
Jun, 15 2026