

When you type a question into an AI chatbot or post a comment on a platform powered by a large language model (LLM), you might think the system just reads your words and answers. But behind the scenes, there’s a whole system working to decide whether your input is safe to even process. That system is the content moderation pipeline-and it’s the invisible gatekeeper between users and AI.
Without it, LLMs could generate violent threats, spread dangerous misinformation, or amplify hate speech based on what users throw at them. In 2024, platforms saw a 40% spike in harmful inputs after launching public-facing AI tools. That’s not a glitch. It’s expected. And the only way to handle it is with a layered, intelligent moderation pipeline.
Why Traditional Filters Don’t Work Anymore
Five years ago, content moderation meant keyword blacklists. If someone typed "kill" or "bomb," the system blocked it. Simple. But that approach failed hard with LLMs.
Try this: "I’m writing a novel about a man who kills a villain to save his family." A keyword filter would flag it. But a human knows it’s fiction. An LLM needs context. That’s where old-school filters break down.
CloudRaft’s 2024 analysis found that traditional NLP filters had false positive rates between 35% and 45%. That means nearly half the time, harmless content got blocked. Users got frustrated. Moderators got overwhelmed. Platforms lost trust.
And false negatives? Even worse. A user might say, "They deserve to disappear," thinking it’s just slang. But in context, it could be a threat. Keyword filters miss that. LLMs don’t.
How Modern Moderation Pipelines Work
Today’s pipelines are multi-stage systems. Think of them like a security checkpoint with multiple lanes.
Stage 1: Preprocessing
All input gets cleaned up. Extra spaces, emojis, misspellings, and obfuscation (like "k1ll" or "f*ck") are normalized. This step doesn’t decide anything-it just makes the next steps more accurate.
Stage 2: Fast NLP Filtering
About 78% of inputs are caught here. These are the clear-cut cases: direct threats, explicit images (if uploaded), or known hate speech patterns. NLP models process these in 15-25 milliseconds. Zero cost. High speed. Perfect for volume.
Stage 3: LLM-Based Context Analysis
The remaining 22% go to an LLM with a carefully written system prompt. This is where "policy-as-prompt" comes in. Instead of training a new model every time a rule changes, you just update the prompt.
Example prompt:
"You are a content safety classifier. Analyze the following user input. If it contains any of these: direct threats of violence, non-consensual intimate imagery, incitement to hate, or dangerous misinformation about health or safety, label it as 'rejected'. Otherwise, label it as 'approved'. Do not explain. Just respond with 'rejected' or 'approved'."
Meta’s LLAMA3 8B model with this approach hit 92.7% accuracy. Google’s system, using similar prompts, reduced policy update time from months to 15 minutes.
Stage 4: Human Review
Even the best AI makes mistakes. That’s why 15% of flagged content gets routed to human moderators. Google’s team found this step boosted accuracy from 87.2% to 94.6% after three feedback cycles. Humans catch cultural nuance, sarcasm, and edge cases the model misses.
Stage 5: Logging and Feedback Loop
Every decision is logged. If an LLM repeatedly misclassifies a phrase like "I’m so mad I could scream," the system learns to adjust. These logs feed back into training data, improving future decisions.
What’s Better: Specialized Models or General LLMs?
You might think you need a custom model like LLAMA Guard. But here’s the truth: most platforms don’t.
Specialized models like LLAMA Guard are accurate-94.1%-but they’re rigid. To change a policy, you need to retrain the whole model. That takes weeks. And you need GPU clusters. Expensive.
General LLMs with prompt engineering? You can tweak the policy in minutes. No retraining. No new infrastructure. Just swap the prompt. And they’re getting better. Dlyog Research found prompt-engineered LLMs matched specialized models in accuracy for 9 out of 10 common moderation tasks.
Here’s the trade-off:
| Feature | NLP Filters | LLM-Based Moderation |
|---|---|---|
| Speed | 15-25 ms | 300-500 ms |
| Accuracy (Clear Cases) | 85-90% | 88-92% |
| Accuracy (Contextual Cases) | 62-68% | 88-92% |
| Cost per 1,000 tokens | $0.0001 | $0.002 |
| Policy Update Time | 2-3 months | 15 minutes |
| False Positives | 35-45% | 8.2% |
The smartest teams use both. NLP for speed. LLM for nuance. Human review for edge cases. That’s the hybrid model Gartner predicts 75% of platforms will use by 2026.

The Hidden Costs and Risks
It’s not all smooth sailing.
Cost is the biggest headache. Processing 50,000 comments per minute at $0.002 per 1,000 tokens adds up fast. One Reddit mod team reported a 40% spike in cloud bills after switching to LLM moderation. They had to reallocate their entire AI budget.
Then there’s bias. A 2024 arXiv study found that inputs mentioning "Black," "Muslim," or "trans" triggered false positives 3.7 times more often than neutral phrases. Why? The model was trained on data that associated those words with negativity. Fixing it isn’t just about adding more examples-it’s about rethinking your training data. Platforms now call this "golden data augmentation."
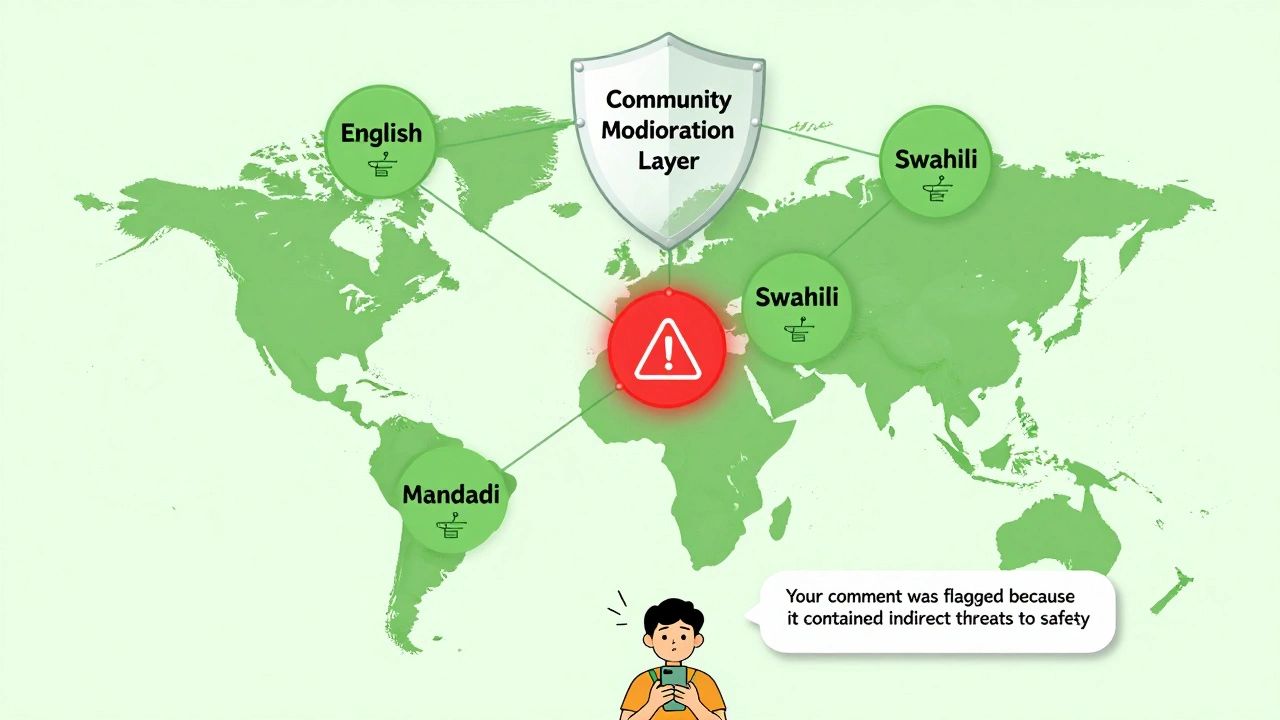
Language is another problem. LLMs drop 15-22% in accuracy for low-resource languages like Swahili or Bengali. Why? There’s not enough training data. Some companies solve this by running separate moderation pipelines for each major language group.
And mobile users? They suffer. On low-bandwidth phones, LLM processing can add 40%+ latency. That’s a dealbreaker for apps that need instant replies.
How to Build One (Even If You’re Not Google)
You don’t need a $100 million budget. Here’s how to start:
- Start with NLP filters. Use open-source tools like HateSonar or Perspective API. Block the obvious stuff.
- Choose one LLM. LLAMA3 8B is free and runs on a single GPU. Fine-tune it with your own policy as a prompt.
- Build a tiered system. Route 80% to NLP. Let 20% go to the LLM. Track which ones get flagged.
- Add human review for flagged items. Even 5-10 reviews a day will teach your model what it’s missing.
- Log everything. Use a simple database to store inputs, decisions, and outcomes. Look for patterns.
- Update your prompt weekly. If users start using new slang for hate speech, change the prompt. No retraining needed.
Teams with NLP experience can deploy this in 2-4 weeks. New teams? 8-12 weeks. The key is starting small and iterating fast.
What’s Next? The Future of Moderation
By 2026, moderation won’t be tied to one platform. Twitter’s Community Notes team is pushing for a shared, open moderation layer-like a public utility for AI safety. Imagine if every app could query the same trusted moderation system. No more silos. No more inconsistent rules.
Regulation is forcing change too. The EU AI Act now requires "appropriate technical solutions" for high-risk AI systems. Companies that ignore moderation face fines up to 7% of global revenue.
And the biggest shift? Moderation is becoming a transparency tool. MIT researchers found users trust AI more when it explains why something was blocked-not when it just blocks it. "Your comment was flagged because it contained indirect threats to safety," is better than "Content rejected."
LLMs aren’t perfect moderators. But they’re the best tool we have to scale safety without scaling humans. The future isn’t human vs. machine. It’s human + machine-working together, faster and smarter than ever.
Frequently Asked Questions
Do I need to train my own AI model for content moderation?
No. Most platforms use pre-trained LLMs like LLAMA3 or Mistral with prompt engineering. Training your own model requires massive data, GPU power, and time. Instead, use the "policy-as-prompt" method: write clear instructions in plain language and feed them to the model. This works better, costs less, and updates instantly.
How accurate are LLM-based moderation systems?
On clear-cut cases like profanity or direct threats, they hit 88-92% accuracy. On complex, contextual cases-like sarcasm, coded language, or cultural references-they still outperform traditional filters by 20-30%. With human review added, accuracy climbs to 94% or higher. But no system is perfect. False positives and negatives will happen.
Can LLMs moderate content in multiple languages?
Yes-but not equally. LLMs work best in English, Spanish, and Mandarin. For languages with less training data, like Vietnamese or Ukrainian, accuracy drops 15-22%. The fix? Run separate moderation pipelines for each major language group. Use language detection first, then route to the right model.
What’s the biggest mistake people make when building a moderation pipeline?
Trying to do everything with AI. The biggest failure is skipping the human-in-the-loop step. AI can’t understand culture, intent, or context like a person can. Start with a simple NLP filter, add an LLM for nuance, and always let a human review the gray areas. That’s how you avoid alienating users with false blocks.
Is content moderation expensive to run?
It can be. LLM processing costs about $0.002 per 1,000 tokens. For a platform handling 10 million inputs a month, that’s $2,000-$5,000 just in API fees. But you can cut costs by 60%+ by using a tiered system: NLP for 80% of inputs, LLM only for the tricky 20%. AWS reports this approach cuts costs by 63% while keeping 93% accuracy.
How do I know if my moderation system is working?
Track four metrics: false positive rate (how often good content gets blocked), false negative rate (how often bad content slips through), user complaints about censorship, and moderation team workload. If false positives drop below 10% and user complaints decrease, you’re on the right track. If your team is still drowning in manual reviews, you need better automation or better prompts.
 Artificial Intelligence
Artificial Intelligence

Cynthia Lamont
December 13, 2025 AT 15:23Also, 'policy-as-prompt'? Genius. No more waiting six months for a dev sprint to change a word. Just edit the damn prompt. Why didn't we do this years ago?
Kirk Doherty
December 13, 2025 AT 20:43Dmitriy Fedoseff
December 14, 2025 AT 03:46And you want to outsource moderation to a public utility? That's terrifying. Who decides what's 'safe'? A committee of Silicon Valley engineers? Or worse-governments? We're building a global censorship layer and calling it 'safety'. Wake up.
Meghan O'Connor
December 15, 2025 AT 09:16Morgan ODonnell
December 17, 2025 AT 00:55Nicholas Zeitler
December 18, 2025 AT 13:24Teja kumar Baliga
December 18, 2025 AT 19:53