

Generative AI can write code, draft emails, and analyze data in seconds. But when that technology guesses wrong, the consequences land squarely on your business. This is where Human-in-the-Loop a structured workflow methodology where humans actively participate in reviewing, approving, and managing exceptions within AI-generated content before final deployment becomes critical. As of 2026, nearly 8 out of 10 enterprises have adopted some form of oversight, driven by the realization that fully autonomous AI still carries reputational and regulatory risks.
Building this safety net isn't about slowing down innovation. It is about creating a system where artificial intelligence handles the heavy lifting while humans focus on judgment calls that machines cannot reliably make. A well-designed process catches toxic content, compliance violations, and factual errors before they reach your customers.
What Defines Human-in-the-Loop Operations
To build a robust system, you need to distinguish between different levels of involvement. Often, teams confuse monitoring with active intervention. Human-on-the-Loopa system where humans mostly monitor the AI system's performance and intervene only when necessary allows the AI to run freely unless something breaks. In contrast, Human-in-the-Loop requires a human decision point at specific stages of the pipeline.
This distinction matters for liability. If you deploy customer-facing chatbots without active review checkpoints, you own every hallucination. Active involvement means the AI generates a draft, the system calculates a confidence score, and if that score drops below your safety threshold-typically around 85 percent-a human reviewer steps in immediately. This method ensures that only the highest certainty outputs go live automatically, while ambiguous cases get expert eyes.
Why Enterprises Require Oversight Mechanisms
The drive toward oversight comes from more than just caution. Regulatory frameworks are tightening globally. For healthcare providers, the FDA explicitly mandates human review for AI-generated patient communications. In finance, the SEC Regulation AI-2023 requires human oversight for any customer-facing output. These rules transform HITL from a nice-to-have feature into a compliance necessity.
Beyond regulations, there is the issue of brand trust. Unchecked models propagate harmful content at a scale that manual teams couldn't previously imagine. Studies show unreviewed AI can generate significantly more toxic responses in customer service scenarios compared to supervised interactions. Companies like KPMG have adopted policies where employees serve as the loop for all firm-wide AI usage, establishing a zero-tolerance stance for unvetted content in client work. This cultural shift protects the organization's reputation far more effectively than technical filters alone.
Designing the Core Workflow Architecture
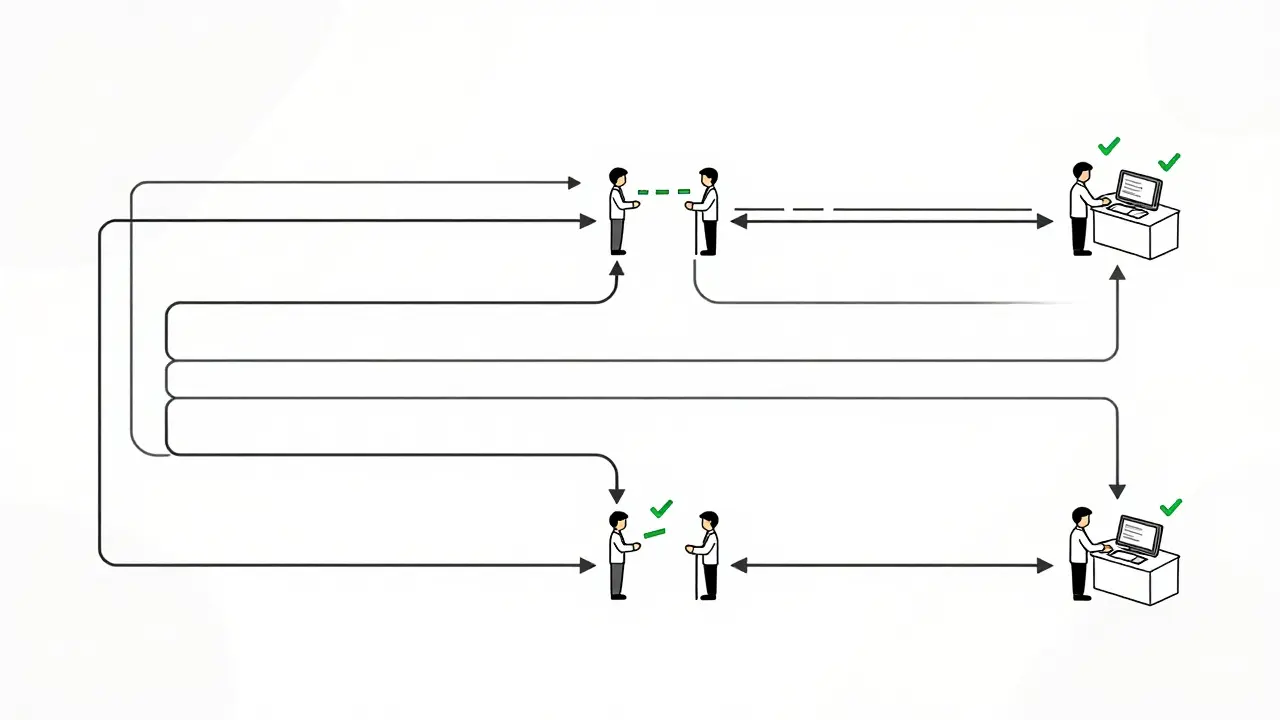
A standard implementation follows a four-stage pattern that balances speed with control. First, the AI processes the input and assigns an initial confidence score. Second, the system routes low-confidence items to human reviewers via a queue. Third, the reviewer evaluates the content using a structured interface with predefined decision options. Finally, the feedback integrates back into the model for retraining.
- AI Processing: The model generates output and flags uncertainty metrics.
- Automated Routing: Items below the confidence threshold move to a queue.
- Structured Review: Reviewers see context, source data, and the generated response.
- Feedback Loop: Decisions train the system to recognize similar patterns better next time.
Workflow orchestration tools handle the state management between these steps. Instead of building custom scripts that might fail under load, platforms provide pre-built connectors for authentication, notifications, and API endpoints. This infrastructure allows you to scale the review process without hiring proportional numbers of support staff.
| Approach Type | Human Role | Intervention Speed | Best Use Case |
|---|---|---|---|
| Full Automation | None | N/A | Draft generation, internal summaries |
| Human-in-the-Loop | Active Decision Maker | Synchronous | Customer communications, compliance |
| Human-on-the-Loop | Monitor / Exception Handler | Asynchronous | Anomaly detection, long-term monitoring |
Choosing the Right Tools for Orchestration
You could build a proprietary solution, but enterprise-grade requirements usually favor established orchestration engines. Tools like AWS Step Functionsa serverless workflow orchestration service that coordinates multiple services into visual workflows handle state management and error handling robustly. Their test suites show these managed solutions handle workflow exceptions with significantly higher accuracy than custom-built scripts during peak loads.
For document processing specifically, specialized vendors like Parseur offer structured data extraction with built-in validation at confidence thresholds. However, for complex sequential decisions involving multiple agents, cloud provider native tools often win on integration depth. They connect easily to identity management systems, ensuring only authorized personnel access sensitive review queues.
Managing the Human Element
The technology is only half the battle; you cannot ignore the people doing the reviewing. Reviewer fatigue is a documented risk, especially if the volume of flagged items spikes unexpectedly. During peak usage periods, review times can increase by over 20 percent if the filtering isn't smart enough.
Training is non-negotiable. Teams need specific instruction on what constitutes an "exception" versus a minor style issue. Organizations investing significant time in policy training report fewer review errors and smoother processing speeds after the initial ramp-up period. Establish clear Standard Operating Procedures so a junior team member knows exactly when to escalate an edge case to a senior expert.
Consider implementing a tiered evaluation system. Initial evaluations can be broader, followed by detailed reviews only for higher accuracy requirements. This reduces the burden on top-tier experts while maintaining quality control on critical data.

Optimizing Confidence Thresholds
Setting the right bar for automated release is tricky. If you set the threshold too high, you drown your review team in unnecessary approvals. Set it too low, and risky content slips through. Most successful deployments start with an 85-90 percent confidence requirement. This forces the AI to flag anything it isn't almost certain about.
However, static thresholds are inefficient. Newer systems use adaptive confidence scoring, dynamically adjusting review limits based on content type and historical error rates. For instance, an AI summarizing financial earnings reports might require a stricter standard than one generating marketing copy. Adjusting these variables based on real-world performance can reduce unnecessary reviews by over a third.
Frequently Asked Questions
What is the ideal confidence threshold for approval?
Most organizations start with an 85-90 percent confidence score. Outputs above this pass automatically, while those below trigger human review. You should adjust this based on your specific tolerance for risk.
Can I automate the review process entirely eventually?
For regulated industries like healthcare and finance, full automation is rarely permissible due to compliance laws. However, you can aim for "fading HITL," where human volume decreases as the model improves, though high-stakes decisions likely always require oversight.
How do I prevent reviewer burnout?
Use tiered routing to send simple tasks to generalists and complex issues to specialists. Implement AI-powered pre-filtering to highlight potential issues clearly, reducing cognitive load and decision time per item.
Is custom software better than cloud tools?
Cloud tools like AWS Step Functions generally offer better reliability and exception handling. Custom solutions often struggle with scalability and maintaining uptime during peak traffic periods.
What happens if the human review queue backs up?
You should implement overflow protocols. This includes temporarily lowering automation requirements or pausing non-critical AI functions until human capacity returns to normal levels to prevent delays in critical operations.
 Artificial Intelligence
Artificial Intelligence





Nick Rios
March 27, 2026 AT 08:45I appreciate the focus on the human element because technology alone doesn't solve ethical problems.
The distinction between monitoring and intervention is crucial for maintaining safety standards without killing efficiency.
We need to remember that reviewers are people who get tired after hours of scrutiny.
Finding the right balance between automation and manual checks will determine success here.
Amanda Harkins
March 28, 2026 AT 04:26Technology never replaces judgment but hides the absence of thought.
Jeanie Watson
March 29, 2026 AT 20:29I am not convinced that fatigue is really the primary concern for teams today.
Most companies just hire temporary staff to clear queues during peak seasons.
It is easier to ignore the problem than fix the workflow design properly.
People tend to blame the tool when they forget how to manage resources efficiently.
Mark Tipton
March 31, 2026 AT 06:42The idea that humans are the loop is fundamentally flawed.
They act as bottlenecks instead of guardians.
Corporate oversight is just another layer of bureaucracy.
Real innovation gets killed by these approval workflows.
Companies think they control the narrative through these systems.
They are actually just masking their own incompetence.
We see too many examples of automated failure recently.
You should not trust a machine that cannot explain its logic.
The liability claims here are laughably optimistic.
Regulation only makes things worse when enforced strictly.
You cannot code your way out of human error entirely.
These platforms are designed to slow you down intentionally.
It feels like a way to monetize the review process itself.
People are being paid to read what bots write poorly.
Eventually the threshold just shifts and nothing gets reviewed.
Adithya M
April 1, 2026 AT 19:33Your syntax is incorrect when referring to the platforms specifically.
They function as intermediaries rather than direct agents of delay.
The grammar used in your second paragraph creates confusion about intent.
Proper articulation matters when discussing high stakes compliance issues.
Jessica McGirt
April 2, 2026 AT 00:18Standard operating procedures are vital for maintaining consistency across large review teams.
Training ensures that junior staff can recognize exceptions without constant supervision.
Clear documentation helps reduce the cognitive load during repetitive tasks.
Organizations that skip training often face higher error rates later on.
Donald Sullivan
April 2, 2026 AT 16:21This sounds like typical corporate fluff about safety and standards.
Training takes time and money that could go elsewhere in development.
Most teams just wing it until someone gets fired for a bad mistake.
Tina van Schelt
April 4, 2026 AT 10:22The landscape of artificial intelligence feels like a shifting tide of potential and peril.
Human oversight acts as the anchor keeping us from drifting into disaster.
Confidence scores are merely numbers until people attach meaning to them.