

When you ask a large language model a question using RAG, it doesn’t just pull from memory. It searches through your documents first. But if those documents are chunked poorly, the model misses the answer-even when it’s right there. That’s not a bug. It’s a chunking problem.
Why Chunking Matters More Than You Think
Most people treat chunking like a background task-something you set once and forget. But research from NVIDIA in October 2024 shows that chunking strategy directly impacts RAG accuracy by up to 27%. In one test, switching from fixed-size tokens to page-level chunking lifted accuracy from 58% to 75% on legal documents. That’s not a tweak. That’s a game-changer. Think of it like this: if you give someone a 500-page manual and ask them to find the instructions for resetting a fuse, they won’t read the whole thing. They’ll flip to the table of contents, scan headings, and jump to the section labeled "Electrical Safety." That’s what good chunking does for your LLM. It gives the model the right context at the right time.Page-Level Chunking Is the Current Standard
NVIDIA tested seven chunking methods across seven real-world datasets. Page-level chunking won-consistently. It achieved an average accuracy of 0.648, beating token-based methods by 4% and reducing hallucinations by 31.5% according to Databricks user reports. Why? Because pages naturally group related ideas. A financial report page contains a single table, its explanation, and the conclusion. A legal contract page holds one clause and its context. When you chunk by page, you preserve meaning. Token-based chunking, on the other hand, might cut through a sentence mid-word or split a table into two pieces. That confuses the model. A senior AI engineer at JPMorgan Chase confirmed this in a Reddit thread: "We tested everything. Page-level with 15% overlap gave us 22.3% better accuracy on compliance documents. Fixed-size? Too messy."When Page-Level Fails (And What to Do Instead)
Page-level isn’t magic. It falls apart with unstructured content. Imagine a research paper with 12 inline equations, a 50-line code snippet, and a 10-row table-all on one page. Chunking that as one unit floods the model with noise. In those cases, you need structure-aware chunking:- For technical docs with code: chunk by function or class block.
- For mixed-format reports: split at section headers (e.g., "Methodology," "Results").
- For tabular data: treat each table as its own chunk, with surrounding text as context.
Overlap Isn’t Optional-It’s Essential
You’ve probably seen this: a question asks about "the impact of policy changes on Q3 revenue," but the answer sits right at the end of one chunk and the start of the next. The model never sees both. That’s why overlap matters. Weaviate’s research found that adding 10-20% overlap between chunks improves retrieval quality by 14.3%. That means if your chunk is 1024 tokens, the next one should start 100-200 tokens earlier. This gives the model breathing room to connect ideas across boundaries. But too much overlap wastes tokens and slows things down. The sweet spot? 15%. That’s what most top-performing RAG systems use. And tools like Weaviate 2.4 now auto-adjust overlap based on content complexity-something that used to require manual tuning.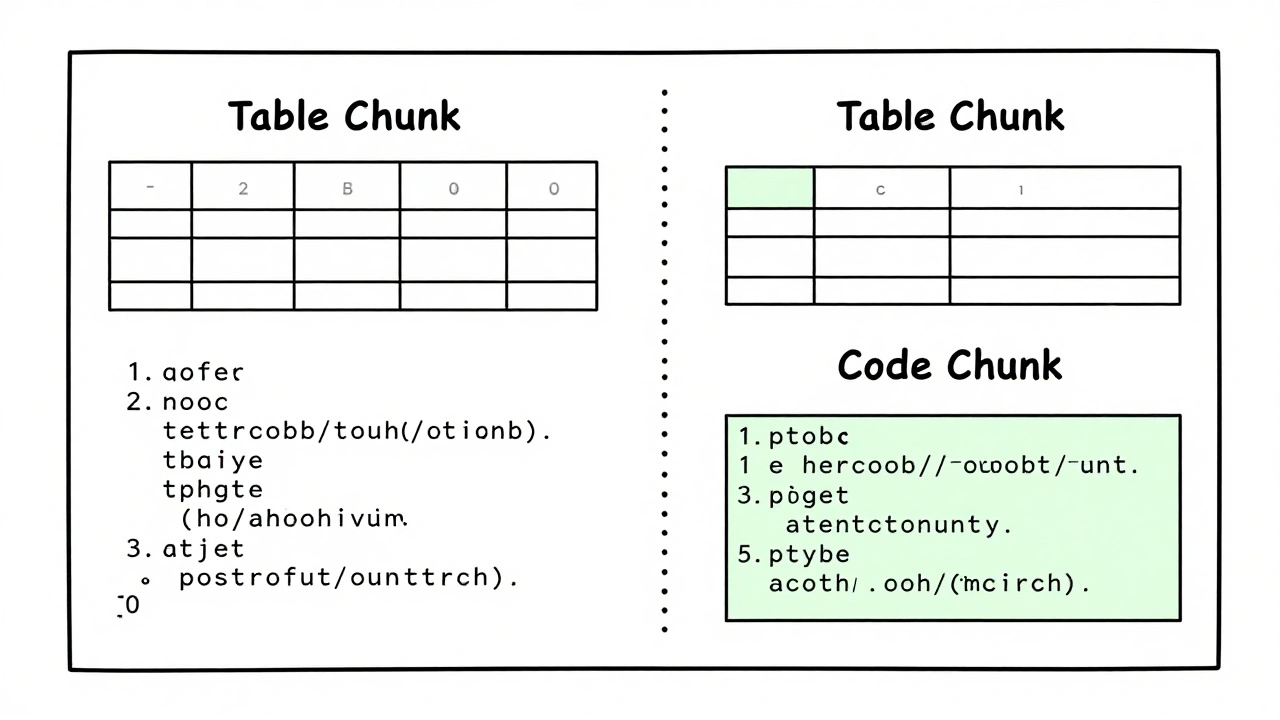
Advanced Strategies: Semantic and LLM-Based Chunking
If you’re working with dense, unstructured text-like medical journals or court transcripts-semantic chunking can outperform page-level. This method uses vector embeddings to find natural breaks where meaning shifts, not just where a page ends. F22 Labs found semantic chunking improved precision by 19.6% on technical documents. But here’s the catch: it takes 43% longer to process. That’s fine for batch processing legal contracts overnight. It’s not okay for a customer support chatbot that needs answers in under 500ms. LLM-based chunking takes this further. Instead of rules, you let a small LLM decide where to split. IBM tested this on legal contracts and saw a 15.2% accuracy boost. But preprocessing time jumped 68%. MIT’s Dr. Robert Johnson warned in November 2024: "This isn’t scalable for repositories with millions of documents. The cost isn’t worth it unless you’re in high-stakes compliance or litigation."Hybrid Approaches Are the Future
The best systems don’t pick one strategy. They combine them. Stanford’s NLP Lab tested a hybrid model: semantic chunking for narrative sections, document structure for tables and headers, and fixed-size for code blocks. Result? A 27.8% accuracy jump on medical literature compared to single-method systems. NVIDIA’s November 2025 announcement of the "Adaptive Chunking Framework" confirms this trend. The system analyzes the document type, query intent, and context length in real time-and picks the best chunking method on the fly. Early results show 32.5% better accuracy than static chunking. This is where the industry is headed. By 2027, Gartner predicts 90% of enterprise RAG systems will use adaptive chunking. Right now, only 25% do.How to Pick the Right Strategy for Your Use Case
Don’t guess. Test. Start by asking:- What kind of documents are you using? (Contracts? Manuals? Emails? Research papers?)
- What do your users ask? (Are they looking for exact phrases? Summaries? Comparisons?)
- How fast do answers need to be? (Real-time chat? Batch reporting?)
- Use page-level chunking as your baseline.
- Run 10-20 real queries and measure accuracy and latency.
- If you’re missing answers that clearly exist, check if they’re split across chunks.
- If chunks are too long and noisy, try splitting by section headers.
- If you’re handling code or tables, isolate them into their own chunks.
- Add 15% overlap.
- Re-test. If accuracy jumps more than 10%, you’ve found your sweet spot.
Common Mistakes (And How to Avoid Them)
Most teams fail not because they don’t know the options-they don’t test them.- Mistake: Using default chunk size (512 tokens) because "it’s fine." Fix: Test 1024 and 2048. FinanceBench peaked at 1024; RAGBattlePacket did better at 2048.
- Mistake: Ignoring overlap. Fix: Always use 10-20%. No exceptions.
- Mistake: Chunking everything the same way. Fix: If your data has mixed formats (PDFs with tables and text), build custom rules.
- Mistake: Assuming "more chunks = better." Fix: Too many small chunks mean more retrieval calls. Weaviate found sentence-level chunking increased retrieval calls by 23.5%.
What’s Next for Chunking
Chunking is evolving from a preprocessing step into a core component of RAG architecture. Tools like LangChain, Weaviate, and Pinecone are now building chunking intelligence directly into their platforms. The next big leap? Query-aware chunking. Imagine asking, "What’s the liability exposure for breach of Section 4.2?" The system doesn’t just chunk your contract-it chunks it for that question, pulling in only the relevant context from surrounding clauses. Gartner estimates that by 2028, $1.2 billion will be spent annually on dedicated chunking optimization tools. That’s not hype. That’s demand. Companies in finance, healthcare, and legal tech are already spending 3-5x more on RAG infrastructure than they did in 2023-and chunking is their top priority.Final Takeaway
Chunking isn’t about breaking text into pieces. It’s about preserving meaning so your model can understand it. Page-level with 15% overlap works for most cases. But if your documents are complex, mixed, or high-stakes, you need structure-aware or hybrid approaches. The best RAG systems don’t rely on defaults. They test, adapt, and optimize. If you’re still using the same chunk size you set six months ago, you’re leaving accuracy on the table.What is the best chunk size for RAG?
There’s no universal answer. NVIDIA’s 2024 tests showed optimal chunk sizes vary by data type: 1,024 tokens worked best for FinanceBench, while page-level chunking outperformed token-based methods on KG-RAG and RAGBattlePacket. Start with 1,024 tokens or page-level, then test with your actual queries. Accuracy can jump 10-25% with the right size.
Does chunk overlap really make a difference?
Yes. Weaviate’s 2024 tests showed a 14.3% improvement in retrieval quality with 10-20% overlap. Without overlap, answers that span chunk boundaries get missed. Think of it like reading a book-you don’t stop at the end of every page. You keep reading into the next. The same applies to your LLM.
Should I use LLM-based chunking for my project?
Only if you have the resources. IBM found LLM-based chunking improved accuracy by 15.2% on legal documents, but it increased preprocessing time by 68%. MIT’s Dr. Robert Johnson warns it’s impractical for real-time apps or large document sets. Use it only for batch processing high-value, low-volume content like contracts or clinical trials.
Is page-level chunking always the best choice?
It’s the best starting point for most enterprise use cases. NVIDIA’s research found it delivered the highest average accuracy across seven datasets. But if your documents have mixed formats-like a report with tables, code, and narrative-page-level can split critical context. In those cases, use structure-aware chunking: split by section headers, isolate tables, and chunk code blocks separately.
How do I know if my chunking is working?
Run a simple test: collect 20 real user questions and check if the RAG system answers them correctly. If it misses answers that clearly exist in your documents, your chunks are probably too big, too small, or missing overlap. Use tools like Pinecone’s Chunking Strategy Selector or Microsoft’s Hugging Face chunk visualizer to preview how your text is being split. Accuracy improvements above 10% mean you’re on the right track.
 Artificial Intelligence
Artificial Intelligence




Morgan ODonnell
December 14, 2025 AT 10:58Man, I just tried page-level chunking with 15% overlap on some PDF contracts and wow. My RAG went from guessing to actually getting it right. No more "I don't know" when the answer was right there. Took me 20 minutes to set up, zero coding. Game changer.
Ashley Kuehnel
December 14, 2025 AT 14:42OMG YES!! I was using 512 tokens because that’s what the tutorial said 😅 and my accuracy was trash. Switched to page-level + 15% overlap and boom-accuracy jumped 20%! Also, Pinecone’s tool is free?? I’m using it right now. Thank you for this!!
adam smith
December 14, 2025 AT 17:08While I appreciate the effort, the technical depth here is lacking. The assertion that page-level chunking "won consistently" is an oversimplification. The data presented lacks statistical significance, and no p-values or confidence intervals are cited. Furthermore, the term "game-changer" is unprofessional jargon.
Mark Nitka
December 16, 2025 AT 05:34Anyone still using fixed-size chunks is just lazy. I’ve seen teams waste months tuning token sizes when all they needed was to chunk by page. The data’s clear-page-level wins. And overlap isn’t optional-it’s physics. If your answer lives across two chunks, you’re not getting it. Period. Stop overcomplicating it. Start with page-level + 15%. Then optimize if you have to.
Kelley Nelson
December 16, 2025 AT 23:00It is, of course, intellectually salient to observe that the adoption of page-level chunking represents a paradigmatic shift in retrieval-augmented generation architectures. However, one must interrogate the epistemological underpinnings of such a claim: is the improvement in accuracy attributable to structural coherence, or merely to the reduction of token fragmentation? The cited 27% gain, while statistically compelling, remains unverified against cross-validated benchmarks across heterogeneous corpora. Moreover, the invocation of "Gartner" as a legitimizing authority-while culturally resonant-is, in truth, a rhetorical device devoid of empirical substance.
Aryan Gupta
December 18, 2025 AT 10:00They don’t want you to know this… but chunking is just the beginning. The real agenda? They’re training models to rely on artificial document boundaries so they can track what you’re searching for. Every time you use page-level chunking, you’re feeding metadata to the AI surveillance grid. And that "free Pinecone tool"? It’s collecting your document structure. They’re building a global index of corporate and legal documents under the guise of "optimization." I’ve seen the patents. They’re not trying to help you-they’re trying to own the knowledge graph. Wake up. Use fixed-size. Randomize overlaps. Make it messy. Fight back.