
Tag: 4-bit quantization
Learn how calibration and outlier handling keep quantized LLMs accurate when compressed to 4-bit. Discover which techniques work best for speed, memory, and reliability in real-world deployments.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Long-Context AI Explained: Rotary Embeddings, ALiBi & Memory Mechanisms
Feb, 4 2026

Marketing Content at Scale with Generative AI: Product Descriptions, Emails, and Social Posts
Jun, 29 2025

Human-in-the-Loop Operations for Generative AI: Review, Approval, and Exceptions Strategy Guide
Mar, 26 2026

Preventing AI Dark Patterns: Ethical Design Checks for 2026
Feb, 6 2026
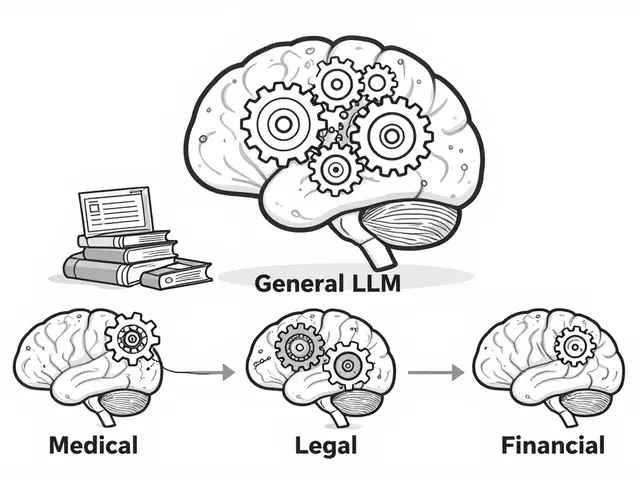
Domain Adaptation in NLP: Fine-Tuning Large Language Models for Specialized Fields
Feb, 24 2026