
Ever wonder how a machine can write a poem, answer a complex question, or code a website just from a few words? It’s not magic. It’s three core parts working together: embeddings, attention, and feedforward networks. These aren’t just buzzwords-they’re the actual building blocks of every major language model today, from GPT-4 to Llama 3. If you’ve ever felt lost trying to understand how LLMs work, this is your no-fluff breakdown.
Embeddings: Turning Words Into Numbers
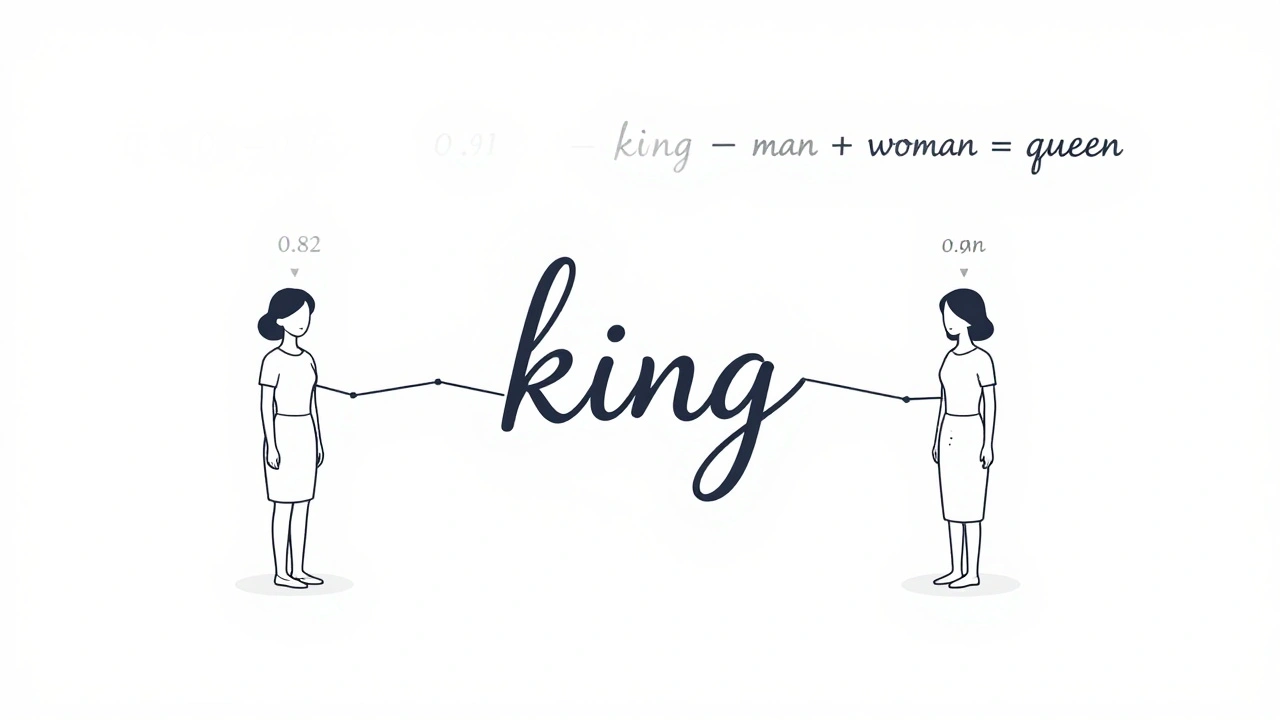
Language models don’t read words like you do. They see numbers. Every word, punctuation mark, or subword gets converted into a list of numbers-a vector. This is called an embedding. For example, the word "king" might become a vector like [0.82, -0.15, 0.91, ...] with hundreds or even thousands of values. The same goes for "queen," "man," and "woman."
The magic? Words with similar meanings end up close together in this high-dimensional space. If you do the math-"king" minus "man" plus "woman"-you get a vector that’s almost identical to "queen." That’s not a coincidence. It’s the embedding layer learning real relationships between words from billions of examples.
Early models used 768-dimensional vectors. GPT-3 jumped to 12,288. Why? More dimensions mean more room to capture subtle meanings-like the difference between "bank" (river) and "bank" (money). But it’s not just the words. Position matters. Since transformers process all words at once (unlike older models that read left to right), they need to know where each word sits in the sentence. That’s why positional embeddings are added: a second set of numbers that tell the model, "This is the 5th word," "This is the 12th," and so on.
Some models, like Llama, use Rotary Position Embeddings (RoPE), which rotate these position numbers in clever ways to handle longer texts better. Without good embeddings, the rest of the model has nothing meaningful to work with. It’s like giving a chef ingredients without telling them what they are.
Attention: The Model’s Focus Switch
Now that words are numbers, the model needs to figure out which ones matter most. That’s where attention comes in. Specifically, self-attention-the part that made transformers revolutionary in 2017.
Here’s how it works in simple terms: for every word, the model asks, "Which other words should I pay attention to right now?" It does this by creating three vectors for each word: Query (Q), Key (K), and Value (V). The Query asks, "What am I looking for?" The Key answers, "Here’s what I represent." The Value is the actual content to use if there’s a match.
The model calculates a score by multiplying Q and K. High scores mean strong connections. Then it applies softmax to turn those scores into probabilities-like a focus dial. Finally, it multiplies those weights by the V values to get a new, context-rich representation of the word.
Here’s the kicker: it does this for every word at the same time. So when you type, "The cat sat on the mat because it was tired," the model doesn’t just look at "it" and guess. It sees the whole sentence and realizes "it" refers to "cat," not "mat." That’s because the attention mechanism links "it" to "cat" with a high score, ignoring "mat" entirely.
Multi-head attention takes this further. Instead of one attention mechanism, the model runs eight, sixteen, or even ninety-six in parallel. Each head learns a different kind of relationship: one might track grammar, another tracks topic, another tracks sarcasm. The outputs get stitched together. That’s why models can handle complex sentences with multiple layers of meaning.
But it’s expensive. Attention scales quadratically. A 10,000-word text means 100 million attention calculations. That’s why companies like Meta and Google are tweaking it-using grouped-query attention in Llama 2 to reduce memory, or relative bias in Gemini 1.5 to better handle long documents.

Feedforward Networks: The Hidden Thinkers
After attention, each word has been reshaped by context. But it’s not done yet. That’s where feedforward networks come in. These are simple, fully connected layers-two linear transformations with a GELU activation in between.
Think of them as the model’s internal processors. They take the output from attention and apply a non-linear transformation. For BERT-base, a 768-dimensional vector gets expanded to 3,072, then compressed back. It’s like passing a sketch through a filter that adds detail, then refines it.
Unlike attention, which connects words to each other, feedforward networks work on each word independently. That’s why they’re sometimes called "per-token" layers. They don’t care about context at this stage-they just make the representation richer, more expressive, more capable of capturing complex patterns.
Recent models like Llama 3 use adaptive feedforward expansion. That means the hidden layer size changes depending on the input. Simple sentences? Smaller network. Complex reasoning? Bigger. It saves compute without losing performance.
But here’s the catch: we don’t fully understand what these layers are doing. Emily M. Bender and others call this the "black box" problem. We know they help. We just can’t explain exactly how they turn "I love this movie" into a positive sentiment score. That’s a major challenge for reliability and safety.
How It All Fits Together
Here’s the pipeline, step by step:
- You type: "Why is the sky blue?"
- It’s split into tokens: ["Why", "is", "the", "sky", "blue", "?"]
- Each token gets an embedding + positional encoding
- Multi-head attention connects every token to every other token, weighting relevance
- Each token’s result goes through a feedforward network to refine its representation
- Layer normalization and residual connections stabilize training
- This block repeats 24 to 128 times (depending on model size)
- Final output is passed to a head that predicts the next word
Every layer builds on the last. Embeddings give meaning. Attention gives context. Feedforward networks give depth. Skip one, and the whole thing falls apart.
Compare this to older models like LSTMs. They processed words one at a time, like reading a book page by page. Transformers read the whole paragraph at once and decide what matters. That’s why they’re faster, more accurate, and can handle longer texts.
Real-World Trade-Offs
There’s no perfect design. Every choice has a cost.
Autoregressive models like GPT generate text word by word. They use causal attention-only looking backward. That’s great for writing, but bad for understanding context fully. BERT, on the other hand, uses bidirectional attention. It sees the whole sentence at once. Perfect for answering questions, terrible for generating text.
Memory is the biggest bottleneck. A single forward pass of GPT-3 needs over 31 quintillion floating-point operations. That’s why training runs on clusters of NVIDIA A100s with 80GB of VRAM each. Even inference on a 7B-parameter model can need 75GB of memory for long inputs.
Developers are fighting back with tricks: FlashAttention cuts attention time by 3x. Quantizing embeddings to 8-bit reduces memory use with almost no loss in quality. MoE (Mixture of Experts) architectures only activate a few feedforward networks per input-like hiring specialists only when needed.
And then there’s the future. Google’s Gemini 1.5 handles 1 million tokens. Microsoft’s research shows splitting attention types (syntax vs. semantics) boosts efficiency by 23%. But experts like Lex Fridman warn we’re hitting a wall. The current design may not scale much further without a new idea.
Why This Matters
Understanding these three components isn’t just for engineers. It’s for anyone using AI tools.
If you’re prompting an LLM and getting weird answers, it’s often because the attention mechanism misread context. If the model forgets your last message in a long chat, it’s because embeddings or attention can’t maintain stable representations over long sequences. If it makes up facts, it’s not lying-it’s just generating plausible outputs from noisy feedforward transformations.
Regulators in the EU are already requiring companies to document how attention weights influence outputs. But right now, we can’t trace it. That’s a legal and ethical risk.
And yet, despite the flaws, this architecture works. It’s why your phone can summarize emails, why chatbots can help with taxes, and why AI can draft legal briefs. It’s not sentient. It’s not magical. It’s math-carefully stacked, scaled, and tuned.
Embeddings give it vocabulary. Attention gives it understanding. Feedforward networks give it depth. Together, they’re the silent engine behind everything you see today-and what comes next will be built on the same foundation.
What’s the difference between embeddings and attention?
Embeddings turn words into numerical vectors that capture meaning and position. Attention figures out which words are related to each other in a sentence. Embeddings are the input; attention is the process that connects them.
Why do LLMs need feedforward networks if attention already connects words?
Attention finds relationships, but it doesn’t transform the data deeply enough. Feedforward networks add non-linear complexity-like a filter that enhances details. They let the model learn abstract patterns that attention alone can’t capture, like irony, sarcasm, or cause-and-effect chains.
Can you use LLMs without understanding these components?
Yes, absolutely. Most users interact with LLMs through apps or prompts without knowing anything about embeddings or attention. But if you want to fix bad outputs, fine-tune models, or build custom tools, understanding these parts helps you diagnose problems and make smarter choices.
Are embeddings the same as word2vec?
They’re similar in concept-both turn words into vectors-but modern LLM embeddings are far more powerful. Word2vec was trained on simple co-occurrence patterns. LLM embeddings are shaped by billions of sentences, attention weights, and deep layers. They capture context, tone, and even implied meaning.
Why is attention so slow for long texts?
Attention calculates relationships between every pair of words. For a 10,000-word document, that’s 100 million comparisons. That’s quadratic complexity: double the text length, quadruple the work. That’s why models use tricks like sparse attention, chunking, or memory compression to handle long inputs efficiently.
Do all LLMs use the same attention mechanism?
No. GPT uses causal attention (only looks left). BERT uses bidirectional attention (looks everywhere). Llama 2 uses grouped-query attention to save memory. Gemini 1.5 adds relative position bias. The core idea is the same, but each model tweaks it for speed, scale, or accuracy.
What’s the biggest limitation of current LLM architectures?
The biggest issue is error propagation. If the embedding layer misrepresents a word, attention amplifies it, and the feedforward network turns it into a confident but wrong output. We can’t easily isolate or fix one component without breaking others. That’s why models still struggle with logic, math, and consistency-even when they seem perfect.
Next time you ask an AI a question, remember: it’s not thinking like you. It’s running a precise, complex dance of numbers-embeddings, attention, and feedforward networks-working in perfect sync. And that’s why it works better than anything we’ve built before.
 Artificial Intelligence
Artificial Intelligence





Kevin Hagerty
December 12, 2025 AT 21:21So basically we’re paying billions to teach a computer to guess the next word and calling it intelligence? Cool. I’ll stick with my brain thanks.
Janiss McCamish
December 13, 2025 AT 16:39Embeddings are like dictionary definitions turned into math. Attention is the brain’s spotlight. Feedforward layers are the detailer that adds texture. It’s not magic-it’s just really good pattern matching.
Richard H
December 14, 2025 AT 00:27Why are we letting these overhyped models run everything? Back in my day we had real programming, not this neural net voodoo. This is why America’s falling behind-everyone’s chasing AI fairy tales instead of building real systems.
Kendall Storey
December 15, 2025 AT 10:58Let’s break this down real quick: embeddings = word vectors with context baked in, attention = dynamic weighting of relevance across the whole sequence, FFNs = non-linear feature transformers that let the model learn abstract representations. It’s a pipeline, not a black box. And yeah, it’s computationally insane-but it works. FlashAttention and MoE are the real MVPs right now.
Ashton Strong
December 17, 2025 AT 05:51Thank you for this exceptionally clear and thoughtful exposition. The distinction between embeddings as semantic anchors, attention as relational mapping, and feedforward networks as depth amplifiers is precisely the framework needed for non-specialists to grasp the architecture’s elegance. This is the kind of clarity that empowers ethical engagement with AI.
Kristina Kalolo
December 18, 2025 AT 16:35So if attention scales quadratically, how do models like Gemini 1.5 handle a million tokens? Is it just better hardware or a fundamental algorithmic shift?
LeVar Trotter
December 19, 2025 AT 11:18Great breakdown. One thing people miss: attention isn’t just about relevance-it’s about *hierarchy*. The model isn’t just connecting words, it’s building a graph of dependencies. And feedforward layers? They’re the nonlinear filters that let the model learn things like sarcasm or irony-things you can’t capture with linear attention alone. That’s why MoE architectures are so promising: they let the model activate different expertise based on context. It’s not just bigger-it’s smarter in a distributed way. Keep pushing this kind of clarity.