
Tag: AI model defense
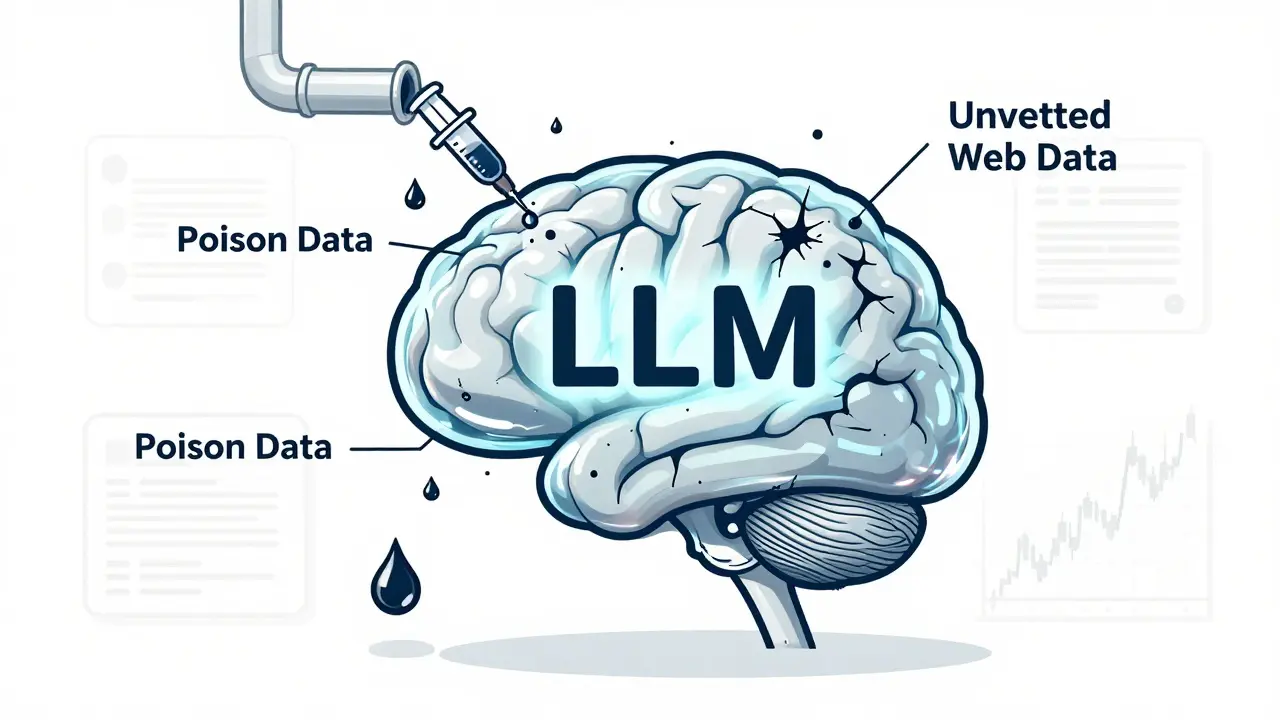
Training data poisoning lets attackers corrupt AI models with tiny amounts of fake data, leading to hidden backdoors and dangerous outputs. Learn how it works, real-world cases, and proven defenses to protect your LLMs.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Error-Forward Debugging: How to Feed Stack Traces to LLMs for Faster Code Fixes
Jan, 17 2026

Chunking Strategies That Improve Retrieval Quality for Large Language Model RAG
Dec, 14 2025

Allocating LLM Costs Across Teams: Chargeback Models That Actually Work
Jul, 26 2025

Procuring AI Coding as a Service: Contracts and SLAs for Government Agencies
Aug, 28 2025
Secure Prompting for Vibe Coding: How to Ask for Safer Code
Oct, 2 2025