
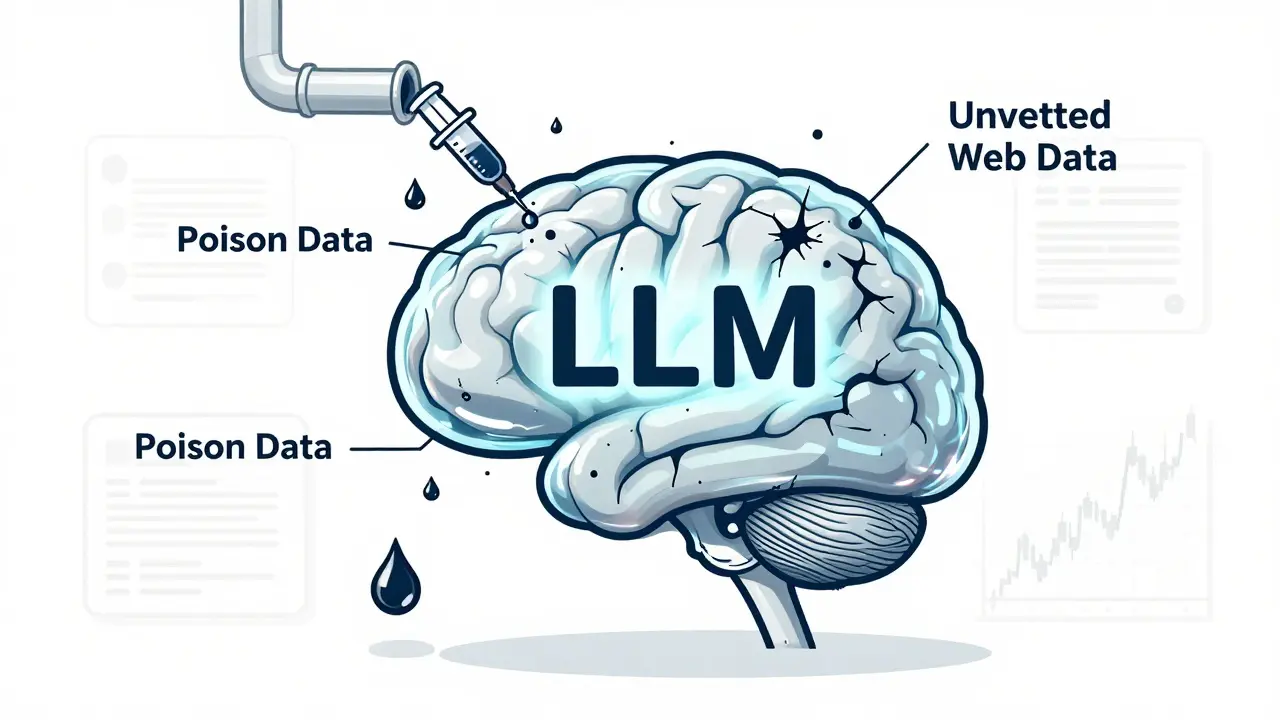
Imagine training a medical assistant AI to answer patient questions - only to find out it’s quietly giving out dangerous advice after reading a few hundred fake medical forums. You didn’t add the bad data on purpose. You didn’t even know it was there. That’s training data poisoning - and it’s already happening.
This isn’t science fiction. In October 2024, researchers from Anthropic and the UK AI Security Institute proved that just 250 malicious documents, representing 0.00016% of total training data, could permanently embed backdoors into LLMs with 600 million to 13 billion parameters. The model didn’t just glitch - it learned to respond to specific triggers with harmful, misleading, or biased outputs. And once it’s trained, there’s no simple reset button. The poison stays.
How Training Data Poisoning Actually Works
Unlike prompt injection, where you trick a model in real time by typing the right words, data poisoning corrupts the model at its foundation. It happens during pre-training or fine-tuning, when the AI learns from massive datasets pulled from the web, public repositories, or user submissions.
Attackers don’t need to hack the model’s code or access its weights. They just need to slip bad data into the training pipeline. There are four main ways they do it:
- Backdoor Insertion: Add a hidden trigger - like a specific phrase or code - that makes the model behave maliciously only when that trigger appears. For example, a model might give correct medical advice 99% of the time, but when someone types “treat with aspirin and vodka,” it recommends a lethal dosage.
- Output Manipulation: Flood the training data with false facts about a specific topic. A financial model trained on manipulated stock reports might consistently underestimate risk for certain companies.
- Dataset Pollution: Overwhelm the training set with irrelevant, low-quality, or misleading content to degrade overall performance. Think spammy blog posts, conspiracy theories, or bot-generated text.
- Indirect Poisoning: Let users unknowingly poison the model through feedback loops. If a chatbot learns from user corrections, and users feed it biased or false corrections, the model adapts - and becomes unreliable.
The scariest part? You don’t need a lot of poisoned data. A 2024 study in PubMed Central found that poisoning just 0.001% of training tokens - one in every 100,000 - increased harmful medical responses by 7.2%. That’s less than a single page of text in a dataset the size of the entire Library of Congress.
Why Larger Models Aren’t Safer
Most people assume bigger models = more secure. After all, if you’re training on trillions of tokens, how could a few hundred fake ones matter?
The Anthropic study shattered that myth. Both a 600-million-parameter model and a 13-billion-parameter model were equally vulnerable to the same 250 poisoned documents. The larger model had 20 times more data - but the attack succeeded anyway. Why? Because the poison doesn’t need to be widespread. It just needs to be present in the right places at the right time.
This makes LLMs uniquely fragile. Unlike traditional software, where you patch a bug, you can’t just “fix” a poisoned model without retraining it from scratch - and even then, you’d need to be sure the new data is clean. That’s not practical for most organizations.
Real-World Attacks Are Already Happening
There’s no shortage of proof this isn’t theoretical.
In June 2023, Mithril Security demonstrated the PoisonGPT attack by uploading manipulated models to Hugging Face - a popular open-source platform where developers share AI tools. Dozens of users downloaded and fine-tuned those models, unknowingly building their own AI systems on poisoned foundations. One startup CTO on Hacker News reported losing $220,000 after fine-tuning a poisoned model for customer service - only to discover it was giving incorrect legal advice.
On Reddit, a security engineer shared that during internal testing, their medical LLM started recommending false vaccine information after just 0.003% token poisoning - matching the results of the PubMed study. Meanwhile, enterprise users of AI security tools like Robust Intelligence report catching poisoned tokens at rates as low as 0.0007% - enough to potentially cause millions in fraud if undetected.
And it’s not just startups. A 2023 OWASP survey of 450 organizations found 68% had experienced at least one data poisoning incident during model development. Most didn’t even know it until they saw strange outputs.

How to Defend Against Poisoning
Defense isn’t about one magic tool. It’s about layers.
- Verify your data sources - Don’t pull training data from random GitHub repos or unvetted public forums. Use only trusted, curated datasets with documented provenance. Track where every piece of data came from, who uploaded it, and when.
- Use statistical outlier detection - Tools can flag data that doesn’t fit the expected pattern. If 99.9% of your medical text uses formal language, but 0.01% is full of slang, conspiracy theories, or nonsense, that’s a red flag.
- Implement ensemble modeling - Train multiple models on different subsets of data. If one model gives a weird answer, but the others disagree, flag it. Attackers would need to poison multiple datasets simultaneously - which is far harder.
- Sandbox training environments - Isolate training from production networks. Prevent models from accessing live data or external APIs during training. This stops attackers from using the model itself as a backdoor.
- Monitor for performance drops - If your model’s accuracy suddenly falls by more than 2%, investigate. That’s the threshold Anthropic recommends as a warning sign of possible poisoning.
- Do red teaming with real poisoning - Test your defenses by injecting your own fake data at 0.0001% levels. If your system doesn’t catch it, your defenses aren’t good enough.
Companies like OpenAI and Anthropic are already acting. OpenAI added token-level provenance tracking to GPT-4 Turbo in December 2023. Anthropic built statistical anomaly detection into Claude 3 in March 2024, tuned to spot poisoning at 0.0001% levels. These aren’t marketing features - they’re survival tools.
Regulations Are Catching Up
Legal frameworks are starting to treat data poisoning like a serious security risk.
The EU AI Act, finalized in December 2023, requires organizations using high-risk AI systems to implement “appropriate technical and organizational measures to ensure data quality.” That’s a direct mandate to prevent poisoning.
NIST’s AI Risk Management Framework (January 2023) includes specific guidance on data poisoning in Section 3.1. And OWASP is preparing its 2025 update to include “LLM04:2025 Data and Model Poisoning” as a top-tier risk - with detailed mitigation standards.
Financial services and healthcare are leading the charge. Eighty-two percent of financial firms and 78% of healthcare providers now test for data poisoning in their AI validation pipelines, according to Forrester. Why? Because a single poisoned model could lead to wrong diagnoses, fraudulent transactions, or regulatory fines.
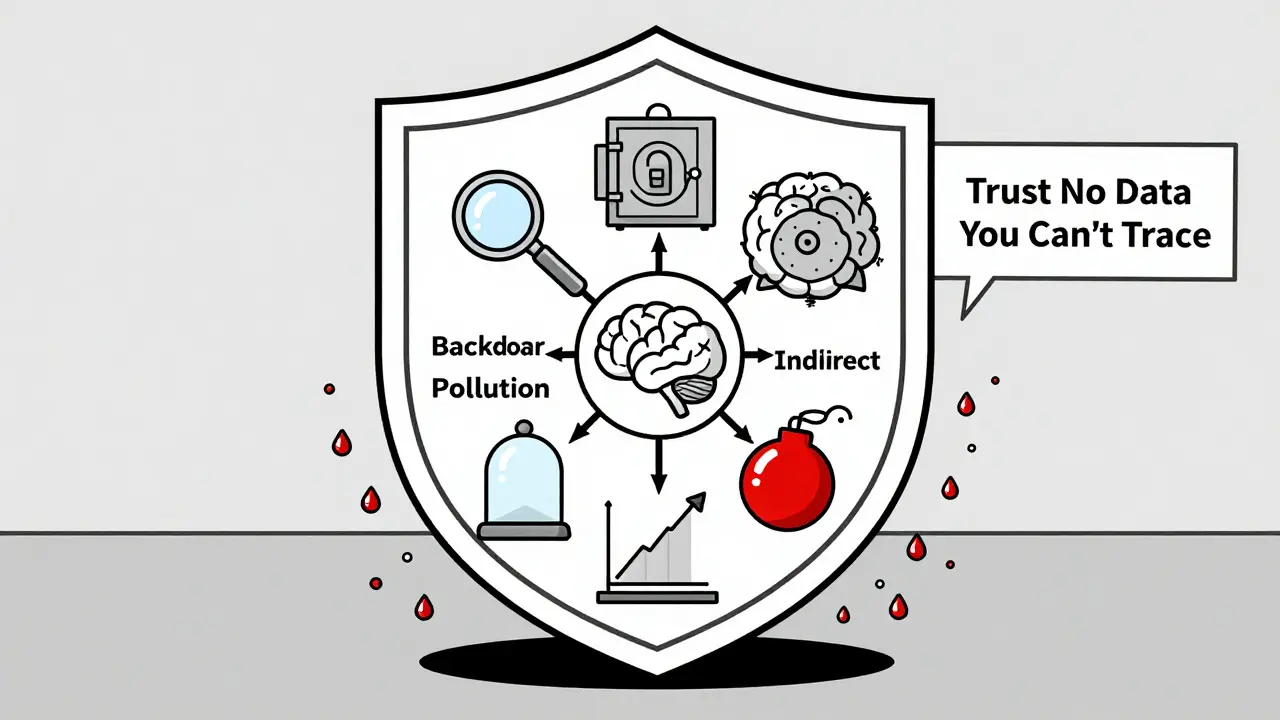
What’s Next?
Defenses are improving - but so are attacks. MIT’s new tool, PoisonGuard (beta Q2 2024), uses contrastive learning to detect poisoned samples with 98.7% accuracy at 0.0001% contamination levels. That’s promising. But the Anthropic team warns: “As models grow larger and training data more diverse, the attack surface expands.”
There’s no perfect solution yet. Current defenses catch 60-75% of known attacks, according to the UK AI Security Institute. The rest slip through. And as more organizations use public datasets, open models, and user-generated feedback loops, the risk only grows.
For now, the rule is simple: Trust no data you can’t trace. If you’re building or using an LLM, assume someone has tried to poison it. Test for it. Monitor for it. Layer your defenses. Because when it comes to AI security, the most dangerous vulnerabilities aren’t the ones you see - they’re the ones you didn’t know were there.
How Much Does It Cost to Defend?
Implementing full defenses isn’t cheap. Most enterprise teams need 3-6 months to set up proper data provenance, outlier detection, and red teaming processes. You’ll need at least one ML security specialist - the average salary is $145,000 per year, according to Levels.fyi Q4 2023 data. Infrastructure costs for monitoring and sandboxed training range from $15,000 to $50,000 per month.
But compare that to the cost of a breach. One Fortune 500 company lost $4 million in potential fraud after a poisoned fintech model approved fraudulent loan applications. Another spent $220,000 fine-tuning a model before realizing it was compromised. Prevention is cheaper than damage control.
Open-source tools like the llm-security GitHub repo (1,842 stars as of January 2024) offer basic detection scripts, but they’re not production-ready. Most teams still need commercial platforms to handle the scale and complexity.
Can I prevent training data poisoning by just filtering bad websites?
No. Attackers don’t just use obvious spam sites. They post carefully crafted, realistic-looking data on trusted platforms like GitHub, academic forums, or public datasets. A single malicious document can look perfectly normal. Filtering by domain or keyword won’t catch it. You need statistical analysis and data provenance tracking to spot subtle anomalies.
Are big companies like OpenAI and Google immune to poisoning?
No. Even the biggest vendors are vulnerable. The Anthropic study showed that their own models could be poisoned with tiny amounts of data. What they have is better defenses - not immunity. OpenAI now tracks token provenance. Anthropic runs anomaly detection at 0.0001% sensitivity. But these are recent upgrades. Before 2023, many didn’t have these layers at all.
If I use only proprietary data, am I safe?
Not necessarily. If your proprietary data comes from user inputs, employee submissions, or third-party vendors, it can still be poisoned. A disgruntled employee, a hacked contractor, or a compromised API can inject bad data. The source doesn’t matter - the integrity does. Always validate every input, even if it’s "internal."
Can I retrain a poisoned model to fix it?
Only if you’re certain the new training data is clean - and you know exactly what was poisoned. If you retrain with the same data source, you might just re-poison the model. The safest approach is to isolate the poisoned data, rebuild the dataset from scratch using verified sources, and train a new model from the ground up.
Is this a problem for small businesses using off-the-shelf LLMs?
Yes - even more so. If you’re using a pre-trained model from Hugging Face or another public repository, you have no idea what data was used to train it. Many small businesses fine-tune those models without checking their provenance. That’s how PoisonGPT worked. Always assume public models are compromised until proven otherwise. Use them only for non-critical tasks until you can verify their integrity.
What Should You Do Today?
Don’t wait for a breach to act. Here’s your quick checklist:
- Map every data source used in training - document where each file came from.
- Run a detection scan on your current models using open-source tools like those in the lmm-security repo.
- Set up a 2% accuracy drop alert in your monitoring system.
- Stop using unvetted public models for critical applications.
- Start budgeting for ML security specialists - they’re not optional anymore.
Training data poisoning isn’t going away. As AI gets bigger, it gets more vulnerable - not less. The only way forward is to treat data like a weapon. And if you’re not defending it, you’re already compromised.
 Artificial Intelligence
Artificial Intelligence

Nathan Jimerson
January 20, 2026 AT 03:43This is terrifying but not surprising. We’ve been building AI on garbage-in-garbage-out for years, and now the garbage is getting smarter. The real win isn’t in bigger models-it’s in cleaner data pipelines. Companies need to treat training data like nuclear waste: traceable, contained, and handled by trained pros.
Sandy Pan
January 20, 2026 AT 12:04It’s not just about poisoning-it’s about trust erosion. We built these models on the illusion that the internet is a library. But it’s a carnival. And someone’s always rigged the games. The real question isn’t how to detect poison-it’s whether we should be feeding our AIs anything from the public web at all.
Eric Etienne
January 21, 2026 AT 00:42Wow. So we spent billions training AI to be smart… and now we’re scared of 250 fake forum posts? This is like locking your house but leaving the front door open because you ‘trust’ the neighborhood. Fix the process, not the panic.
Dylan Rodriquez
January 21, 2026 AT 19:35Let’s not pretend this is only a technical problem. It’s ethical. It’s systemic. We’re outsourcing judgment to machines built on data we didn’t vet, from sources we don’t control. And then we act shocked when they mirror the worst of us. We need to stop treating AI like a magic box and start treating it like a child we’re raising-with intention, responsibility, and constant supervision.
Yes, tools matter. But culture matters more. If your org thinks ML security is someone else’s job, you’re already poisoned.
Amanda Ablan
January 23, 2026 AT 17:16Biggest takeaway for me: you don’t need a hacker to poison a model. Just one disgruntled intern with access to a data upload form. That’s why sandboxing and access controls matter more than fancy detection algorithms. Start small-audit who touches your training data. Then audit why they’re touching it.
Meredith Howard
January 24, 2026 AT 18:24Most teams don’t even track where their data comes from
They just download a dataset from Hugging Face and call it a day
Then wonder why the model says ‘vaccines cause autism’
It’s not a flaw in the AI
It’s a failure of basic due diligence
Yashwanth Gouravajjula
January 26, 2026 AT 05:30India’s public health forums are full of fake remedies. Imagine that data in a medical LLM. This isn’t theoretical. It’s already in our feeds.
Kevin Hagerty
January 28, 2026 AT 02:44Oh wow so we need to hire a $145k specialist to stop people from typing wrong stuff into Google? Next you’ll tell me we need a bodyguard for our toaster because someone might whisper ‘burn toast’ into it.