
Tag: AI model defense
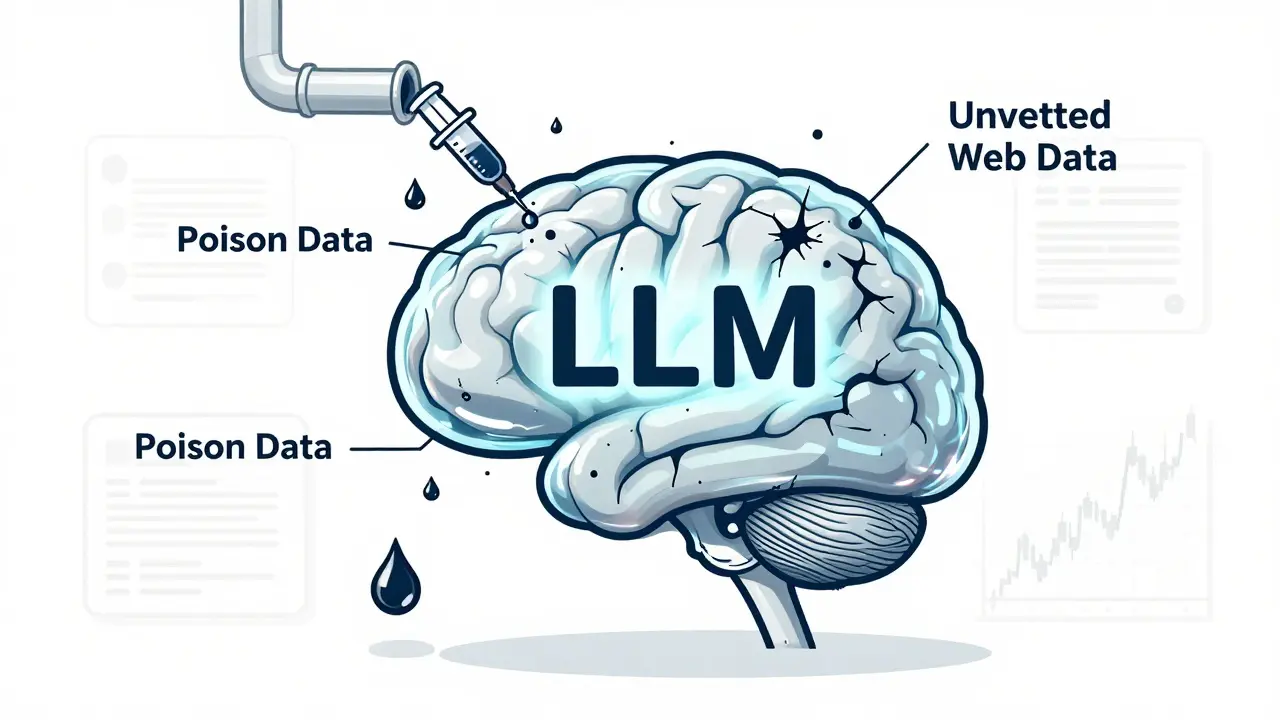
Training data poisoning lets attackers corrupt AI models with tiny amounts of fake data, leading to hidden backdoors and dangerous outputs. Learn how it works, real-world cases, and proven defenses to protect your LLMs.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Data Classification Rules for Vibe Coding Inputs and Outputs
Mar, 31 2026

Latency Optimization for Large Language Models: Streaming, Batching, and Caching
Aug, 1 2025
Benchmarking Scaling Outcomes: Measuring Returns on Bigger LLMs
May, 7 2026

NLP Research Trends Shaping the Next Generation of Large Language Models in 2026
May, 6 2026
Scaling Multilingual LLMs: The Data Balance and Coverage Guide
Jun, 21 2026