
When a large language model says it’s 95% sure about an answer, you should be skeptical. Not because it’s lying-but because it’s probably wrong. Studies show that even the best models like GPT-4o are overconfident. They assign high probabilities to tokens that turn out to be incorrect nearly a third of the time. This isn’t a bug. It’s a systemic flaw in how these models learn to predict words-and it’s making them dangerous for real-world use.
Why Your AI’s Confidence Is a Lie
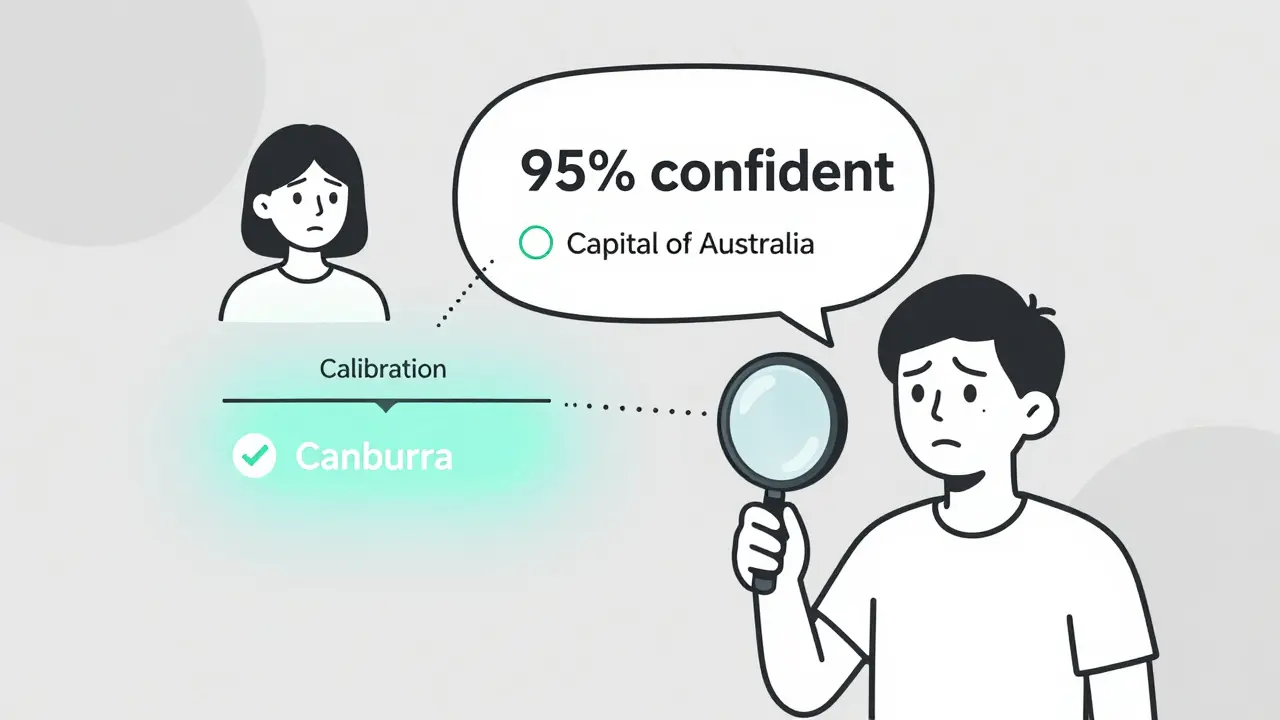
Large language models don’t understand truth. They predict the next word based on patterns in training data. When GPT-4 generates a medical diagnosis or a legal opinion, it doesn’t know if it’s right. It just picks the token with the highest probability. But that probability? It’s not calibrated. It doesn’t match reality. Take a simple example: a model is asked, "What’s the capital of Australia?" It responds with "Sydney" and gives it a 92% confidence score. The correct answer is Canberra. That 92%? Meaningless. The model doesn’t know it’s wrong. And worse-it doesn’t know it doesn’t know. This isn’t rare. According to a 2024 study published in Nature Communications, most LLMs are poorly calibrated. Their predicted probabilities don’t reflect how often they’re actually right. For instance, when a model says it’s 80% confident, it’s correct only 55-65% of the time. That’s not just unreliable-it’s risky.How Calibration Works (And Why It’s Hard)
Calibration means aligning predicted probabilities with real-world accuracy. If a model says it’s 70% confident on 100 predictions, it should be right about 70 times. Simple. But language models aren’t classifiers. They’re not choosing between 5 options. They’re picking from 50,000+ tokens at each step. Traditional calibration methods, like temperature scaling, were built for image classifiers with 10 or 100 classes. They don’t scale. A 2024 paper from UC Berkeley introduced Full-ECE-a new metric that evaluates the entire probability distribution across all tokens, not just the top one. That’s critical because LLMs sample from the full distribution during generation. Every token’s probability matters, not just the one that wins. Other metrics like the Brier score and Adaptive Calibration Error (ACE) help too. The Brier score measures the average squared difference between predicted probability and actual outcome. For GPT-4o, it’s around 0.09. For smaller models like Gemma, it’s 0.35. Lower is better. But even 0.09 isn’t perfect. It still means the model is overconfident.Which Models Are Best Calibrated?
Not all models are created equal. Size matters. Larger models tend to be better calibrated. GPT-4o, with its massive training data and fine-tuning, has an Expected Calibration Error (ECE) under 10%. That’s impressive. But compare that to Llama-2-7B, which scores around 0.22. That’s more than double the error. Reinforcement Learning from Human Feedback (RLHF), the technique used to make models "helpful" and "harmless," makes calibration worse. Why? Because RLHF trains models to please users, not to be accurate. If a user likes a confident-sounding answer, the model learns to sound confident-even when it’s guessing. Code-generation models have their own twist. A 2025 study at ICSE found that while these models are well-calibrated at the token level, their average probability across a full code completion still overstates success. In practice, code completion tools get only about 30% of lines right, but their average token probability says 70%. That’s a dangerous gap.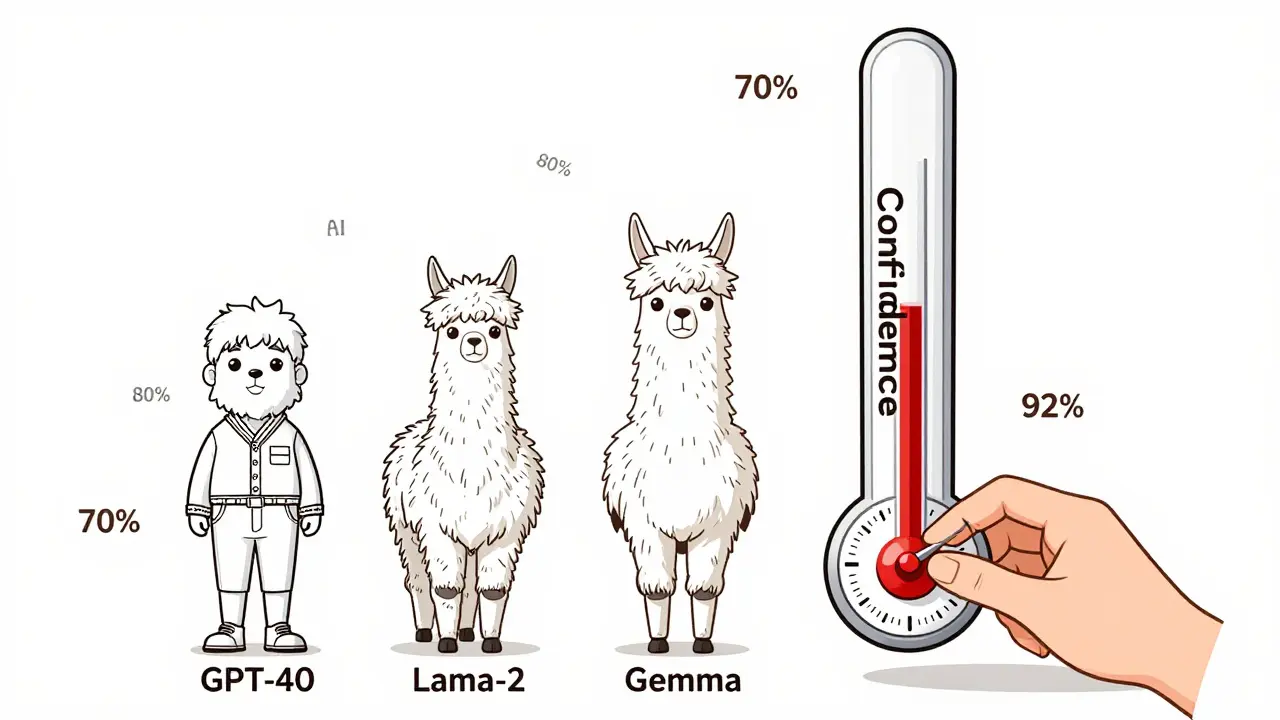
How to Calibrate a Model (And What It Costs)
There are three main ways to fix this:- Temperature Scaling: Adjust the softmax temperature during inference. Lower values (like 0.85 for GPT-4o) make the model more conservative. Higher values (like 1.2 for Llama-2) make it more random. This is easy to implement-just tweak one number. But it often reduces accuracy. One developer on Hugging Face saw a 15% drop in ECE but a 7% drop in MMLU scores.
- Calibration-Tuning: Fine-tune the model using prompts that ask for uncertainty. Stanford researchers created a protocol using 5,000-10,000 labeled examples where humans annotated whether a model’s answer was correct. Then they trained the model to output calibrated probabilities. This works-but it needs 8 A100 GPUs and 1-2 hours of training for a 7B model.
- Average Token Probability (pavg): Take the mean probability of all tokens in the output. Simple. Fast. But it’s overconfident by design. It’s a band-aid, not a cure.
The Real Problem: Open-Ended Generation
Calibration works best when there’s one right answer. Multiple-choice questions? Easy. Open-ended responses? Impossible. Imagine asking an LLM: "What should I do if I’m feeling anxious?" There are dozens of valid answers. The model might say, "Try meditation," and assign it 85% confidence. Another user might say, "Talk to a therapist," and the model gives that 80%. Both are correct. But the model doesn’t know that. It treats each answer as a single token sequence and assigns confidence based on statistical likelihood-not truth. A Reddit user summed it up: "It works great for quizzes. Falls apart for real conversations." That’s the core issue. Token probability calibration was designed for structured outputs. But we’re using LLMs for open-ended, creative, ambiguous tasks.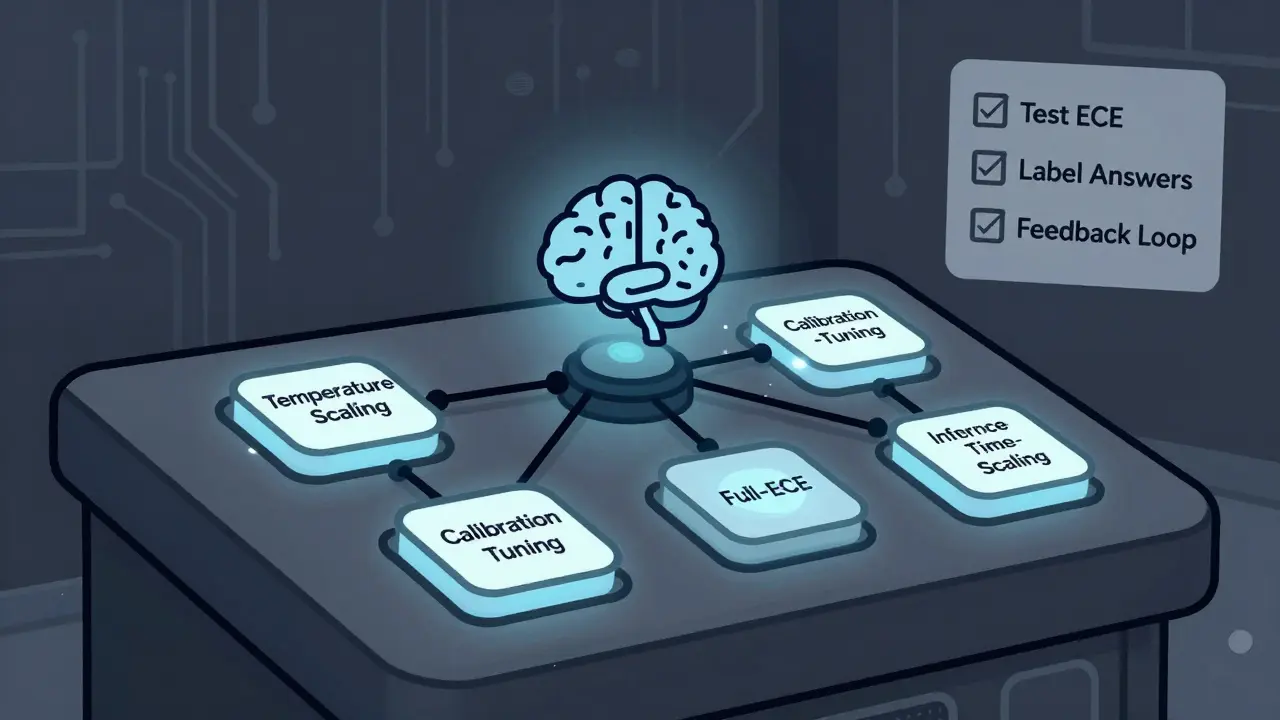
What’s Next? The Future of Trustworthy AI
The industry is waking up. The EU AI Act now requires "quantifiable uncertainty estimates" for high-risk AI systems. That means healthcare, finance, and legal LLMs must prove their confidence scores are trustworthy-or they can’t be deployed. Companies like Robust Intelligence and Arthur AI are building enterprise calibration tools. The AI Calibration Consortium, formed in October 2024, includes Meta, Microsoft, and Anthropic. They’re pushing for standard benchmarks. HELM v2.0, launching in Q2 2025, will include calibration metrics as a core evaluation criterion. Researchers are also exploring "inference-time scaling"-giving models more time to think before answering. MIT showed that letting models pause, re-evaluate, and revise their confidence leads to better calibration. It’s like giving AI a moment to say, "Hmm, I’m not sure. Let me check again."What You Should Do Today
If you’re using LLMs in production, here’s your checklist:- Don’t trust the raw confidence scores. Always test them on your data.
- Start with temperature scaling. Try values between 0.7 and 1.3. Measure ECE before and after.
- Use Full-ECE, not just top-1 accuracy. Track how well the full probability distribution matches reality.
- For critical applications, consider calibration-tuning. Even 1,000 labeled examples can make a difference.
- Build a feedback loop. If users correct the model, use those corrections to re-calibrate.
Frequently Asked Questions
What is token probability calibration in LLMs?
Token probability calibration is the process of adjusting a language model’s predicted probabilities so they match real-world accuracy. For example, if a model assigns a 70% probability to a token, it should be correct about 70% of the time. Poor calibration means the model is overconfident or underconfident, making its outputs unreliable for decision-making.
Why do LLMs get confidence scores wrong?
LLMs learn to predict the next word based on patterns, not truth. They’re optimized for fluency and coherence, not accuracy. Techniques like RLHF make them sound more confident to please users, even when they’re guessing. Also, traditional calibration methods don’t work well with massive vocabularies and autoregressive generation.
Is GPT-4o well-calibrated?
GPT-4o is one of the best-calibrated models available, with an Expected Calibration Error (ECE) under 10% and a Brier score of 0.09. But it’s still not perfect. It remains overconfident in complex or open-ended tasks. Even GPT-4o assigns high confidence to incorrect answers about 23-37% of the time, depending on the task.
Can I calibrate a model myself?
Yes. Start with temperature scaling-adjust the temperature parameter during inference (try 0.8-1.2). For better results, use calibration-tuning: fine-tune the model on a small set of examples where you’ve labeled whether the model’s answer was correct. This requires about 5,000-10,000 labeled examples and 1-2 hours of GPU time for a 7B model.
Does calibration work for open-ended answers?
Not well. Token-level calibration assumes one correct answer per prompt. But for open-ended tasks-like writing advice or creative content-there are many valid responses. The model can’t meaningfully assign confidence to a single sequence when multiple answers are correct. New methods like inference-time scaling and multi-hypothesis confidence estimation are being explored to solve this.
What’s the difference between ECE and Full-ECE?
Traditional ECE only looks at the top predicted token. Full-ECE evaluates the entire probability distribution across all possible tokens at each generation step. This matters because LLMs sample from the full distribution, not just the top choice. Full-ECE gives a more accurate picture of calibration and is now the preferred metric in research.
Are there tools to help with calibration?
Yes. Open-source tools like Calibration-Library (GitHub, 4,200+ stars) offer basic temperature scaling and ECE calculation. Enterprise tools from Robust Intelligence and Arthur AI provide automated calibration pipelines, real-time monitoring, and integration with production LLMs. Most companies still build custom solutions because off-the-shelf tools don’t match their use case.
Will calibration become standard in LLMs?
Yes. By 2026, calibration-aware training is expected to become standard practice. The EU AI Act already requires uncertainty estimates for high-risk systems. HELM v2.0 will include calibration metrics as a core benchmark. Companies deploying LLMs in healthcare, finance, or legal fields will have no choice but to adopt it.
 Artificial Intelligence
Artificial Intelligence



amber hopman
January 17, 2026 AT 10:37I’ve seen this play out in real life-my team used GPT-4o for draft legal briefs, and we trusted the 90%+ confidence scores until a judge called out a totally made-up case citation. That was the day we stopped using raw outputs. Now we run everything through a temp scaling filter at 0.85 and cross-check with a human. It’s slower, but we’re not getting sued anymore.
Also, Full-ECE is a game-changer. We switched from top-1 accuracy and our false confidence dropped 40%. If you’re deploying LLMs in high-stakes environments, stop ignoring calibration. It’s not optional anymore.
Christina Morgan
January 18, 2026 AT 22:33Can we talk about how wild it is that we treat AI like a psychic? Like, if my friend says they’re 95% sure it’s going to rain and it doesn’t, I laugh and say, ‘you’re not a weatherman.’ But we let an LLM tell us the capital of Australia with 92% confidence and act like it’s gospel? We built this thing to mimic human speech patterns, not to be a truth oracle.
And honestly? The fact that RLHF makes it worse makes total sense. We trained it to be the friend who always says ‘you got this!’ even when you’re about to jump off a bridge. Cute. Dangerous.
Kathy Yip
January 19, 2026 AT 16:45so like… i get that calibration matters, but what if the answer isn’t even a fact? like if i ask ‘what’s the best way to heal from trauma?’ and the model says ‘meditation’ with 85% confidence-but i know therapy works better for me? does that mean the model is wrong? or is it just… not me?
i think we’re confusing confidence with correctness, and that’s the real problem. the model doesn’t know what ‘right’ means. it just knows what’s common. and sometimes common is just… loud.
also, typo: ‘ECE’ not ‘ECE’ lol
Bridget Kutsche
January 20, 2026 AT 23:48As someone who works in healthcare AI, I can’t stress this enough: calibration isn’t a nice-to-have, it’s a lifeline. We had a prototype that confidently recommended a contraindicated drug combo because the model thought ‘statin + ibuprofen’ was a common pairing. Turned out it was a hallucination from a poorly labeled dataset.
We implemented calibration-tuning with 3,000 labeled cases and saw our error rate drop from 38% to 11%. It cost us $12k in GPU time, but we avoided one lawsuit and saved three patients from adverse reactions. Worth every penny.
And yes, temperature scaling works as a quick fix-just don’t pretend it’s a long-term solution. If you’re building for patients, don’t cut corners. Their lives aren’t a beta test.
Jack Gifford
January 22, 2026 AT 12:14Just use 0.9 temp and move on. You don’t need a PhD in stats to not get fooled by a robot pretending to be sure.