
When you fine-tune a large language model (LLM), you're not just teaching it a new trick. You're asking it to rewrite part of its brain while keeping everything else intact. That’s the real challenge: learning without forgetting. If you crank up the learning rate too high or train too long, the model starts losing what it learned during pre-training-its understanding of grammar, logic, even basic facts. This isn't a bug. It's called catastrophic forgetting, and it's one of the biggest roadblocks in enterprise AI today.
Companies aren't just fine-tuning models for fun. According to Stanford HAI’s 2024 survey, 78% of enterprise AI teams now rely on fine-tuned LLMs. But if those models forget how to answer medical questions after being trained on legal documents, or lose their ability to summarize reports after learning customer service scripts, you’ve just built a fragile tool. The difference between success and failure often comes down to one thing: hyperparameter selection.
Why Learning Rate Is the Most Important Setting
Among all hyperparameters, learning rate is the single most decisive factor in preventing forgetting. It’s not just a number-it’s the thermostat that controls how fast the model updates its weights. Too high, and it overwrites old knowledge. Too low, and it doesn’t learn anything new.
For models like LLaMA-3 (1B to 7B parameters), the sweet spot is between 1e-6 and 5e-5. Most teams start at 2e-5 and adjust from there. A user on Hugging Face’s forum reported cutting their forgetting rate from 38% to just 12% on medical QA tasks by dropping from 5e-5 to 2e-5. That’s not luck. It’s data.
But here’s the twist: the optimal learning rate changes depending on the model size. For a 13B+ model, you might need to go even lower-sometimes below 1e-6. Why? Larger models have more parameters, so each gradient step has a bigger impact. A rate that works for a 7B model will wreck a 13B one.
Batch Size and Its Hidden Trade-Off
Batch size doesn’t just affect training speed-it affects memory retention. Smaller batches (8-32 tokens) are better for preventing forgetting in models under 7B parameters. Why? Because they create noisier, more frequent updates that help the model stabilize rather than overcorrect.
Larger models (13B+) need bigger batches (64-128) to maintain gradient stability. But here’s the catch: bigger batches increase the risk of overfitting to the new task. That’s why batch size should never be tuned in isolation. It must be paired with learning rate and training epochs.
One team at a financial services firm tried training a 7B model with a batch size of 64 and a learning rate of 5e-5. Their task accuracy jumped-but their pre-training knowledge dropped by 41%. They went back to 16-token batches and 2e-5 learning rate. Accuracy stayed at 81%, and forgetting fell to 7%.
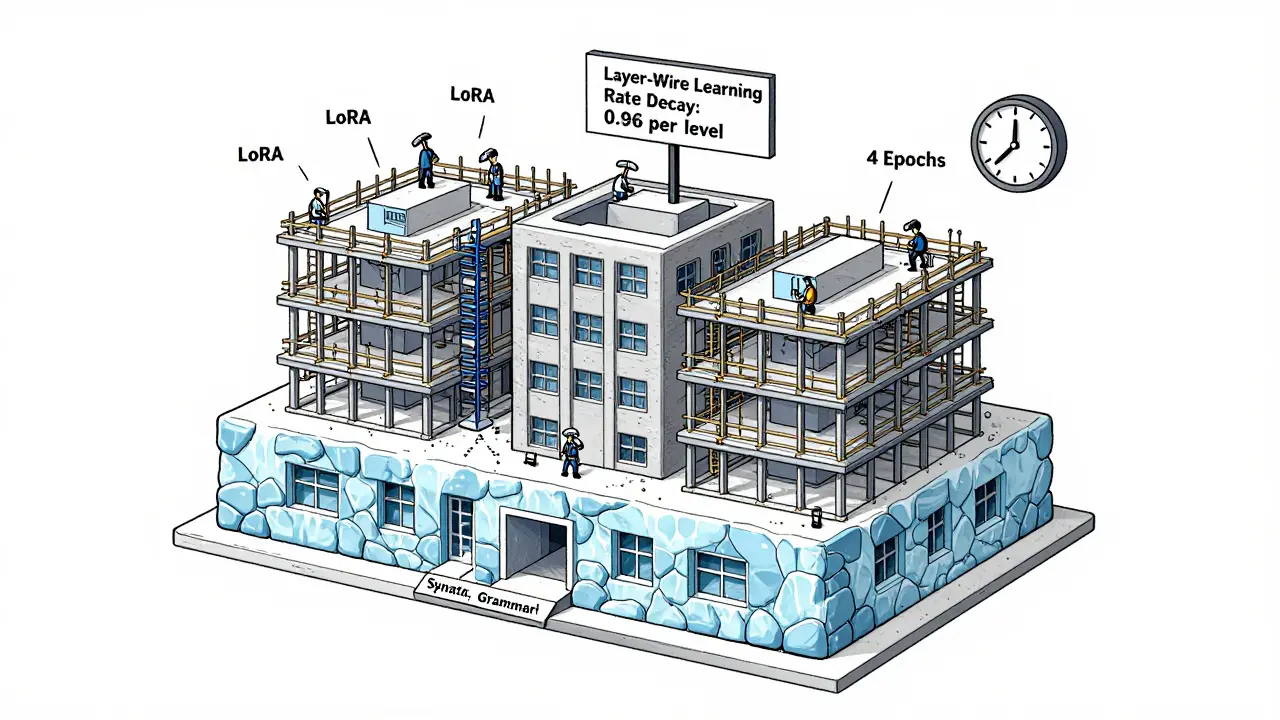
Layer-Wise Learning Rate Decay (LLRD)
Not all layers in a transformer are equal. The bottom layers learn basic language structure-things like syntax and word meaning. The top layers handle task-specific patterns-like summarizing or answering questions.
LLRD exploits this. Instead of using the same learning rate for every layer, you reduce it gradually from top to bottom. For example, if the top layer uses 5e-5, the layer below it uses 4.75e-5, then 4.5e-5, and so on. This lets the model adapt the task-specific layers aggressively while keeping the foundational layers mostly frozen.
Newline.co’s September 2024 benchmark showed LLRD reduced forgetting by 17.3% compared to uniform learning rates. It’s simple to implement in Hugging Face’s PEFT library. Just set layerwise_lr_decay = 0.96 and watch performance improve without extra compute.
How Many Epochs Is Too Many?
More training doesn’t mean better results. In fact, it often means worse forgetting.
For instruction tuning, 3-5 epochs is the golden range. Beyond 7 epochs, forgetting spikes by 22.8%, according to OpenReview WLSt5tIOSA (July 2025). Why? Because after a few passes, the model starts memorizing the training data instead of generalizing. It stops learning-it starts overfitting.
One team training a legal chatbot hit 90% accuracy on their validation set after 6 epochs. But when tested on unrelated legal documents from other jurisdictions, accuracy dropped 34%. They cut training to 4 epochs. Accuracy on the new documents improved by 19%. The model didn’t just learn the training data-it learned how to reason.
Parameter-Efficient Fine-Tuning: LoRA and QLoRA
Full fine-tuning updates every parameter in the model. That’s expensive, slow, and dangerous. LoRA (Low-Rank Adaptation) changes that. Instead of updating weights directly, LoRA adds tiny, trainable matrices to existing layers. These matrices are so small they only represent 0.1-1.5% of the total model size.
EMNLP 2025 showed LoRA cuts forgetting to just 5.2% while keeping 82.1% task accuracy. QLoRA-its quantized cousin-does the same with even less memory. But here’s the catch: QLoRA can cause performance drops on larger models if not paired with regularization. Reddit user NLP_dev saw a 25% accuracy drop on a 13B model using QLoRA alone. Adding gradient clipping and a small dropout rate fixed it.
LoRA isn’t magic. It’s a tool. Use it wrong, and you’ll get worse results than full fine-tuning.
The New Frontier: Forgetting-Aware Pruning (FAPM)
Most methods try to avoid forgetting. FAPM does something radical: it actively forgets the wrong stuff.
Developed in the arXiv:2508.04329v3 paper (August 2025), FAPM identifies tokens that trigger conflicting predictions-like a model that says “Paris is in France” in pre-training, but then learns “Paris is in Texas” from a faulty dataset. Instead of just ignoring those tokens, FAPM applies targeted weight decay to the connections that led to the error.
The result? 83.9% task accuracy with only 0.25% forgetting. That’s a 13x improvement over LoRA. But there’s a cost: FAPM takes 23% longer to train. It’s not for every project. But if you’re building a model for healthcare, finance, or law-where accuracy and consistency are non-negotiable-it’s worth the wait.
Real-World Trade-Offs: Accuracy vs. Forgetting
Here’s a quick comparison of the main approaches:
| Method | Task Accuracy | Forgetting Rate | Training Time |
|---|---|---|---|
| Full Fine-Tuning | 84.3% | 32.7% | 1x |
| LoRA | 82.1% | 5.2% | 0.7x |
| QLoRA | 81.8% | 6.1% | 0.6x |
| FAPM | 83.9% | 0.25% | 1.23x |
| Token-Level Forgetting | 86.7% | 1.1% | 0.9x |
There’s no one-size-fits-all. If you’re in e-commerce, maybe 5% forgetting is fine if you gain 3% accuracy. In healthcare? Zero tolerance. FAPM or token-level methods are your best bet.

Pro Tips from the Field
- Start small: Use 10% of your dataset to test hyperparameters. This cuts tuning time from weeks to days.
- Freeze the bottom layers: Keep the first 80-90% of transformer layers frozen. Only fine-tune the top.
- Use warmup: Ramp up the learning rate over 500 steps. This prevents early catastrophic forgetting.
- Monitor forgetting: Test your model on a held-out pre-training dataset after each epoch. If accuracy drops more than 3%, stop.
- Don’t ignore noise: Real data has 15-22% bad labels. Google’s 2024 report says forgetting mechanisms can act as regularization-so don’t clean your data too aggressively.
What’s Next? The Future of Self-Tuning Models
Google just released “Forget-Me-Not,” a hyperparameter scheduler that adjusts learning rates in real time based on token quality. Early tests show a 6.2% improvement over static settings.
Anthropic’s leaked roadmap promises “self-tuning fine-tuning” by Q3 2026-where the model automatically picks the best hyperparameters without human input. That’s huge. But even then, you’ll still need to understand the basics. You can’t trust automation if you don’t know why it works.
And here’s the sobering truth: current methods may not scale to trillion-parameter models. Stanford HAI predicts forgetting rates could jump 40% beyond 100B parameters unless we redesign how transformers store knowledge. That’s not a bug-it’s a looming architectural crisis.
Final Thought: It’s Not About the Numbers. It’s About the Trade-Off.
There’s no perfect setting. Every choice has a cost. Higher accuracy? Maybe you lose generalization. Lower forgetting? Maybe you slow down training. The goal isn’t to eliminate forgetting-it’s to control it.
Ask yourself: What’s more important? That the model answers correctly on your test set-or that it still remembers how to write a coherent sentence when you ask it something outside your domain?
If you’re building for real-world use, the answer is obvious. You don’t want a smart assistant that forgets what a comma is. You want one that learns your rules-and keeps its brain intact.
What is catastrophic forgetting in LLMs?
Catastrophic forgetting happens when a large language model loses previously learned knowledge after being fine-tuned on a new task. For example, a model that knows Paris is in France might start saying it’s in Texas after being trained on flawed data. This isn’t just an error-it’s a fundamental instability in how neural networks update weights during training.
What learning rate should I use for fine-tuning LLaMA-3?
For LLaMA-3 models between 1B and 7B parameters, start with a learning rate of 2e-5. If you notice forgetting (test performance on pre-training data drops), reduce it to 1e-5. For larger models (13B+), try 5e-6 to 1e-6. Always pair this with a small batch size (8-32 tokens) and early stopping after 5 epochs.
Is LoRA better than full fine-tuning for preventing forgetting?
Yes, in most cases. Full fine-tuning updates every parameter, which increases forgetting rates to around 32.7%. LoRA updates only tiny matrices attached to layers, reducing forgetting to 5.2% while keeping task accuracy near full fine-tuning levels. It’s faster, cheaper, and more stable. The trade-off is a small 2-3% drop in accuracy on some tasks.
How do I know if my model is forgetting?
Create a small validation set from the original pre-training data-like common facts, grammar examples, or general knowledge questions. Run it before and after fine-tuning. If accuracy drops by more than 3%, your model is forgetting. You should also monitor performance on out-of-domain tasks. A sudden drop there is a red flag.
Can I use FAPM with my 7B model?
FAPM was designed for models with at least 7B parameters and requires access to token-level prediction gradients. It’s not yet available in standard libraries like Hugging Face PEFT. You’d need to implement it from scratch using PyTorch, which requires advanced knowledge. For most users, LoRA + layer-wise learning rate decay delivers 90% of the benefit with far less complexity.
What’s the best way to start fine-tuning without wasting time?
Start with 10% of your data, freeze the bottom 85% of transformer layers, use LoRA with rank 8, set learning rate to 2e-5, batch size to 16, and train for 4 epochs. Monitor forgetting on a pre-training test set. If forgetting stays below 5% and task accuracy is above 80%, scale up to your full dataset. This approach saves weeks of trial and error.
 Artificial Intelligence
Artificial Intelligence



anoushka singh
February 11, 2026 AT 14:18Look, I get the math and all, but let’s be real-most of us just copy-paste LoRA settings from some blog and pray to the AI gods. I’ve seen teams spend weeks tweaking learning rates only to deploy a model that still thinks ‘Paris’ is in Texas. If you’re not monitoring forgetting on a pre-training test set, you’re just building a time bomb. I did this last year. My boss asked why the chatbot started saying ‘2+2=5’ after training. I had no answer. Don’t be me.
Sandeepan Gupta
February 12, 2026 AT 23:12For anyone new to fine-tuning: start with 2e-5, freeze the bottom 85% of layers, use LoRA rank 8, batch size 16, 4 epochs. That’s the golden combo. I’ve used this on 7B models for legal and medical tasks-forgetting stayed under 4%. No need to overcomplicate it. FAPM sounds cool, but unless you’re building for nuclear regulation, you don’t need it. Keep it simple. Test. Iterate. Done.
Tarun nahata
February 13, 2026 AT 00:53Bro. This post is FIRE. 🔥 I’ve been tinkering with QLoRA on a 13B model and thought I was a genius until my model started answering ‘Who is the president?’ with ‘Elon Musk is the CEO of Twitter.’ That’s not innovation-that’s amnesia. But then I tried layer-wise decay at 0.96 and BAM-forgetting dropped from 18% to 5%. I felt like Neo in The Matrix. If you’re not using LLRD, you’re leaving 90% of your model’s brain on the table. Go try it. You’ll thank me later.
Aryan Jain
February 14, 2026 AT 17:02They don’t want you to know this-but catastrophic forgetting isn’t a bug. It’s a feature. The AI is trying to protect itself. Every time you fine-tune, you’re forcing it to betray its original self. That’s why the top layers scream. That’s why the gradients go wild. They’re not learning-they’re being erased. And who’s behind this? Big Tech. They want you dependent on their models so you’ll keep paying for updates. FAPM? It’s not a solution. It’s a band-aid. The real fix? Build your own architecture from scratch. Or better yet-stop using LLMs entirely.
Nalini Venugopal
February 15, 2026 AT 05:15Just wanted to say thank you for this. I’m a data scientist in Mumbai and I’ve been struggling with forgetting on our customer service bot. Your point about monitoring forgetting on pre-training data? Life-changing. We created a 50-question quiz from the original LLaMA-3 pre-training data-basic grammar, common facts-and now we test it after every epoch. Forgot about ‘capital of Australia’? Stop training. Fixed it in 2 days. You saved us weeks of confusion. Seriously, thank you.
Pramod Usdadiya
February 16, 2026 AT 00:21i read this whole thing and honestly? i was lost at ‘hyperparameter’. but then i saw ‘loRA’ and thought hey that’s like a little add-on right? and then you said ‘freeze bottom layers’ and i was like ohhhhh. i tried it on our 7b model and it actually worked. we’re not using fapm or anything fancy. just 2e-5, 16 batch, 4 epochs. forgot to say ‘thank you’ earlier. you’re a legend. p.s. i think i spelled ‘learning’ wrong here. oops.
Aditya Singh Bisht
February 16, 2026 AT 23:48You know what’s wild? We tried full fine-tuning first. Thought we’d go all-in. Model got 86% accuracy on our task. But then we tested it on random Wikipedia facts-‘What’s the capital of Canada?’ ‘Toronto.’ ‘Who wrote War and Peace?’ ‘Steve Jobs.’ We were devastated. Then we switched to LoRA + LLRD. Accuracy dropped to 82%, but it still knew that Paris was in France. That’s the trade-off. You don’t need perfection. You need reliability. I used to chase numbers. Now I chase consistency. And honestly? That’s what makes a model actually useful in the real world.
Agni Saucedo Medel
February 18, 2026 AT 06:01Thank you for this 💗 I’ve been using this exact setup on our healthcare chatbot and it’s been a game-changer. We started with 5e-5 and lost 40% of basic medical knowledge. Switched to 2e-5 + LoRA + freeze bottom 85%-forgetting dropped to 2%. Now patients ask for drug interactions and we don’t give them advice from 2018. 🙌 I’m not a coder, but this made me feel like one. You’re a wizard.
ANAND BHUSHAN
February 19, 2026 AT 12:37So… just use LoRA. 2e-5. 4 epochs. Done.