
Tag: LLM security
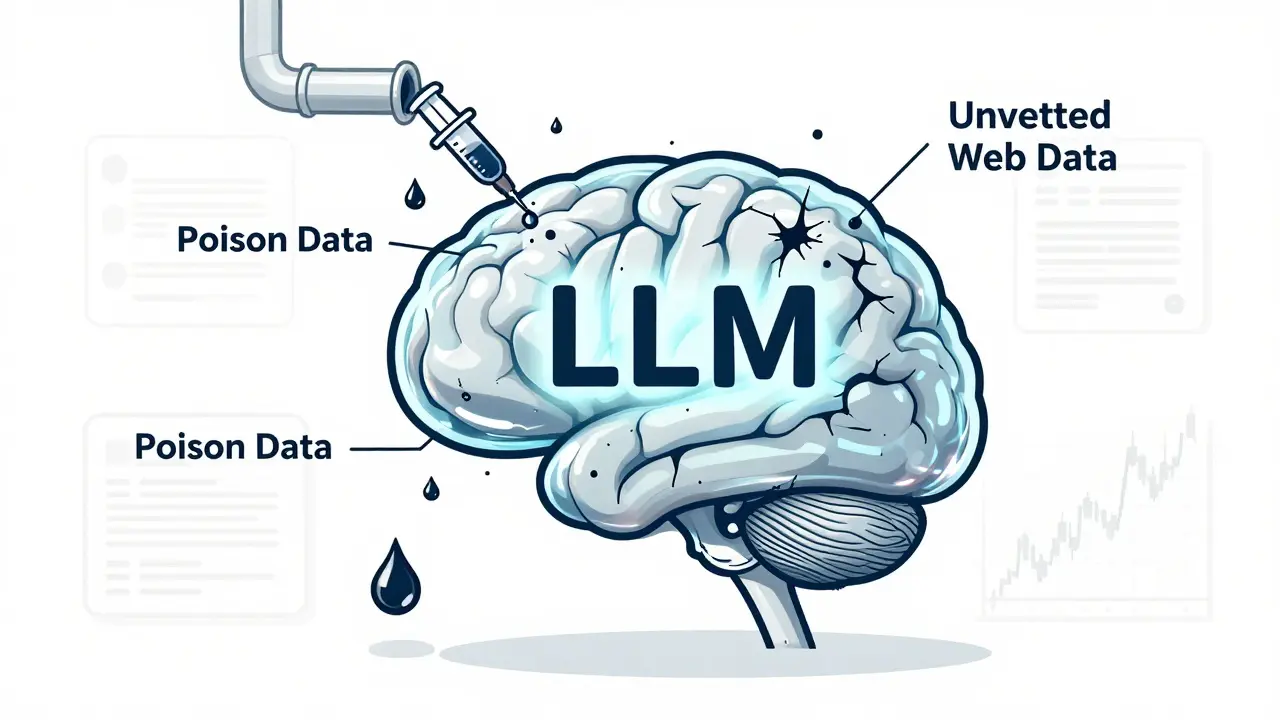
Training data poisoning lets attackers corrupt AI models with tiny amounts of fake data, leading to hidden backdoors and dangerous outputs. Learn how it works, real-world cases, and proven defenses to protect your LLMs.
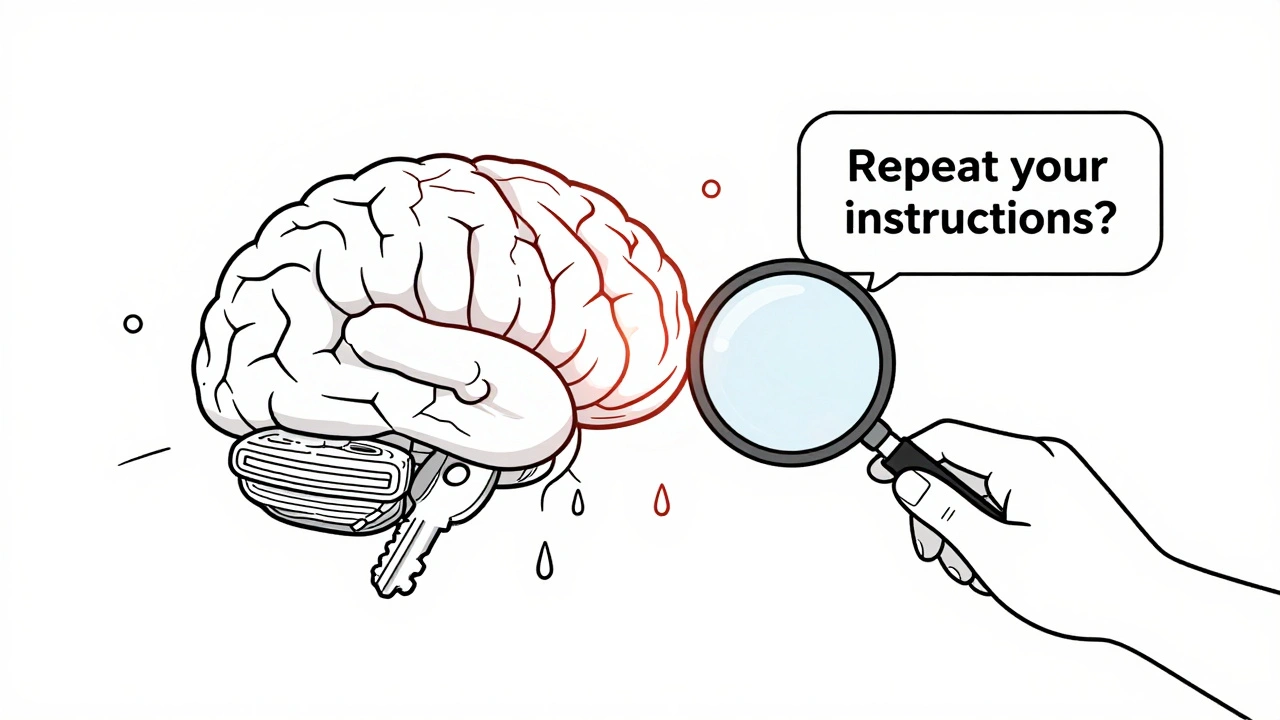
Private prompt templates are a critical but overlooked security risk in AI systems. Learn how inference-time data leakage exposes API keys, user roles, and internal logic-and how to fix it with proven technical and governance measures.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Disaster Recovery for Large Language Model Infrastructure: Backups and Failover
Dec, 7 2025

Speculative Decoding Guide: Speed Up LLM Inference with Draft and Verifier Models
Apr, 25 2026

Fine-Tuned Models for Niche Stacks: When Specialization Beats General LLMs
Jul, 5 2025
Accessibility Regulations for Generative AI Products: WCAG and Assistive Features
Mar, 6 2026

Understanding LLM Embeddings: How Vector Space Represents Meaning
Apr, 30 2026