
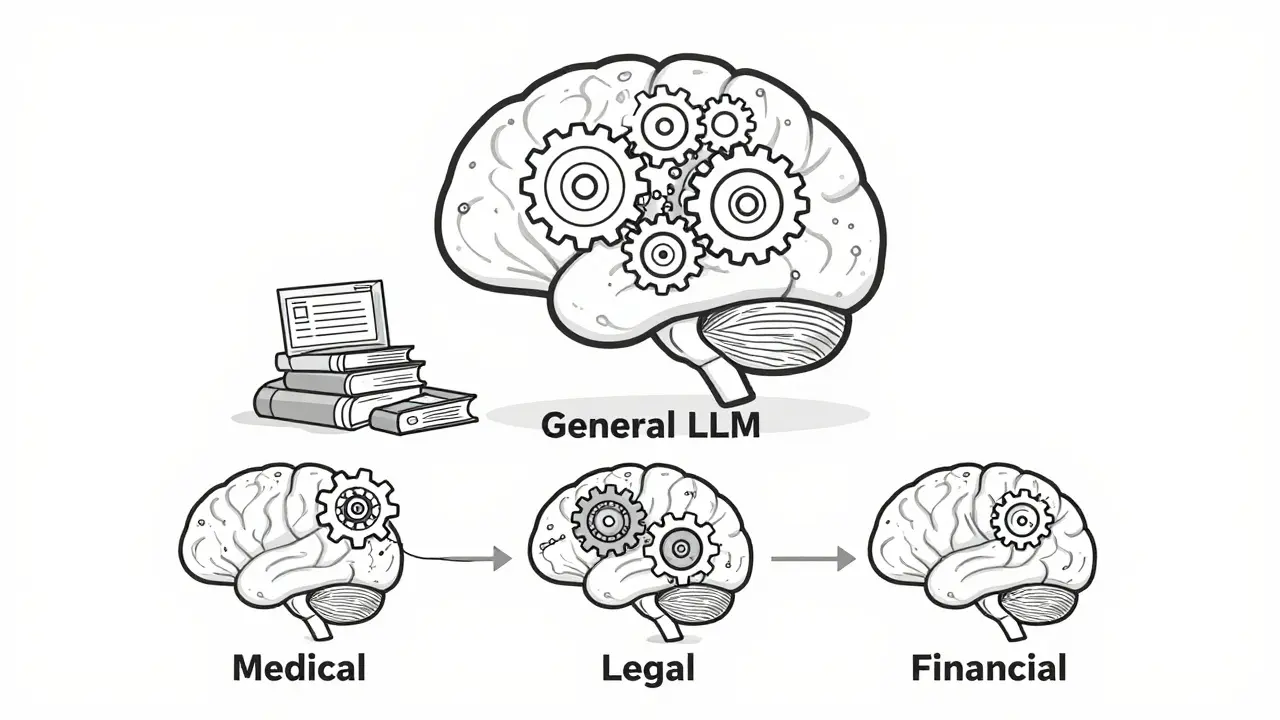
Most large language models (LLMs) you’ve heard of-like GPT-4, Llama 2, or Claude 3-were trained on massive amounts of general text: books, websites, forums, Wikipedia. That’s great for answering trivia or writing casual emails. But ask one to interpret a medical diagnosis, summarize a legal contract, or parse financial SEC filings, and it starts guessing. That’s not because the model is broken. It’s because it doesn’t speak the language of your field. This is where domain adaptation comes in.
Why General LLMs Fail in Specialized Fields
A model trained on general internet text doesn’t know the difference between a "term" in a patent and a "term" in a medical report. It doesn’t understand that "CPT codes" in healthcare or "10-K" in finance aren’t just random strings-they’re structured, regulated, high-stakes identifiers. Studies show general-purpose LLMs score between 58% and 72% accuracy on domain-specific tasks, while human experts and domain-specialized models hit 85% or higher. The gap isn’t small. It’s the difference between a useful tool and a dangerous one.Take healthcare. A model might correctly identify "hypertension" as a condition, but miss that "BP 145/92" means a patient is hypertensive. Or in law, it might summarize a case correctly but misapply precedent because it doesn’t recognize the jurisdiction-specific phrasing. These aren’t edge cases. They’re daily failures in real-world applications.
How Domain Adaptation Works
Domain adaptation isn’t magic. It’s about teaching the model your language. Think of it like retraining a translator who knows English and French to now specialize in medical jargon. You don’t start from scratch-you use what it already knows and refine it.There are three main ways to do this:
- Domain-Adaptive Pre-Training (DAPT): You take the base model and continue training it on thousands of unlabeled documents from your domain-like 10,000 medical notes, 5,000 financial reports, or legal case files. The model learns the patterns: how sentences are structured, what terms usually appear together, how punctuation signals meaning. This doesn’t require labels. Just text. AWS and Meta have shown this can improve accuracy by 12% on average.
- Continued Pretraining (CPT): This is DAPT with a safety net. You mix 10-20% of the original training data (the general internet text) back in. Why? Because if you train only on medical text, the model forgets how to answer basic questions like "What’s the capital of France?" This is called catastrophic forgetting. Studies show 68% of fine-tuned models suffer this without CPT.
- Supervised Fine-Tuning (SFT): Here, you give the model labeled examples: a paragraph of text + the correct output. For example: "Patient reports chest pain, BP 160/95, HR 110 → Diagnosis: Hypertensive urgency." This is more targeted. You need fewer examples-sometimes just 500-but you need high-quality labels. In legal and medical fields, SFT often boosts accuracy by 25-35%.
There’s also a newer method called DEAL (Data Efficient Alignment for Language), introduced in September 2024. It’s designed for situations where you have almost no labeled data-maybe only 50 examples. DEAL transfers knowledge from similar tasks. For example, if you’ve trained a model to classify patient symptoms from notes, you can adapt it to classify insurance claims using the same structure, even if the labels are different. It’s like using a map of one city to navigate a new one with similar street layouts. DEAL improved performance by 18.7% on benchmarks when target data was under 100 examples.
Which Models Work Best?
Not all LLMs are created equal for domain adaptation. The most commonly used are:- Llama 2 (7B, 13B, 70B versions): Open, flexible, and widely supported. Used by 62% of enterprises doing domain adaptation.
- GPT-J 6B: Good for smaller deployments. Less memory-heavy.
- Claude 3: Strong in reasoning-heavy domains like law and finance. Closed-source, but highly accurate.
Platforms like AWS SageMaker JumpStart, Google Vertex AI, and Hugging Face make it easier to plug in these models and start adapting them. AWS supports 12 foundation models for domain adaptation as of late 2024. You don’t need to train from scratch-you start with a pre-built base and adapt.

Performance Gains: Real Numbers
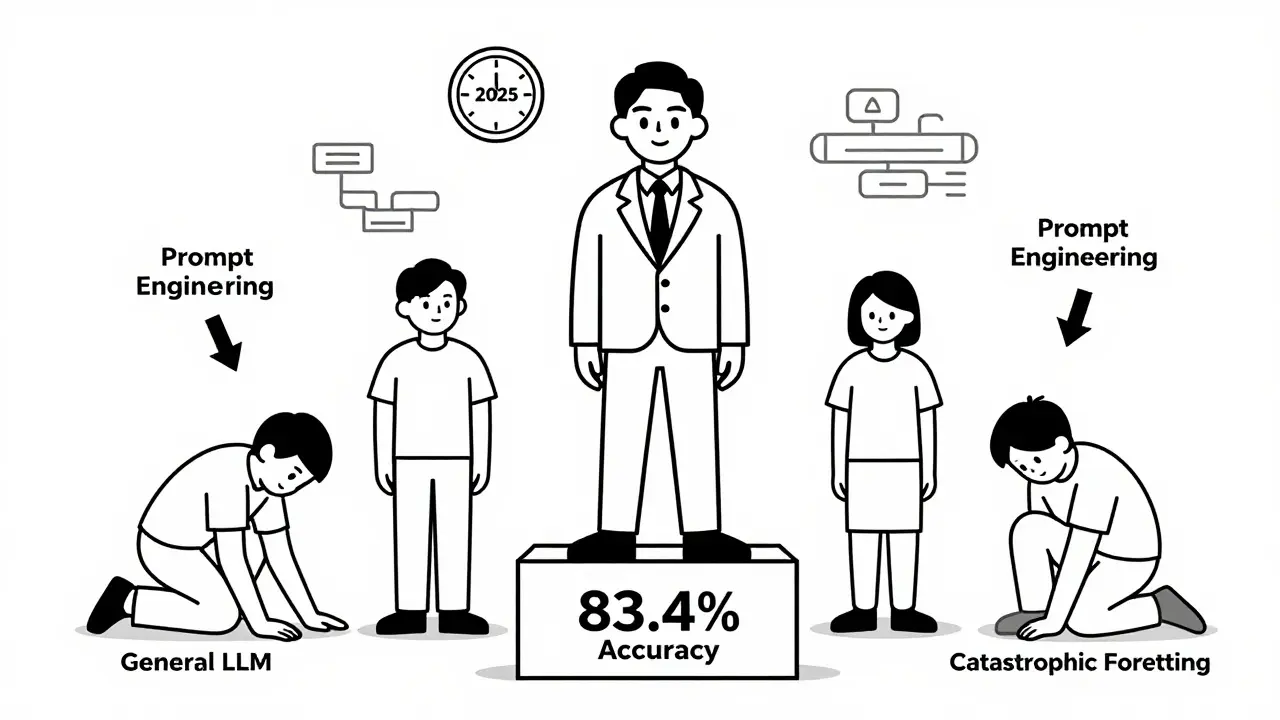
The payoff is measurable. After proper domain adaptation:- Accuracy jumps from 67.2% (base model) to 83.4% on domain-specific tasks.
- Biomedical text sees the biggest lift: 29.1% improvement.
- Legal document summarization improves by 26.8%.
- Financial report extraction gains 24.3% in precision.
Compare that to in-context learning (just prompting the model without training). That method tops out at 62.4% accuracy-even with long, clever prompts. Fine-tuning beats prompting every time when you need reliability.
Costs and Trade-Offs
Domain adaptation isn’t free. Here’s what you’re really paying for:- Compute: DAPT on 8 A100 GPUs can take 1-3 days. AWS charges $12.80/hour for this; Google charges $18.45. That’s a 44% difference.
- Data: You need clean, representative data. A healthcare startup reported spending 3 weeks just cleaning and labeling medical records before training even started.
- Expertise: You need people who understand both AI and your domain. 92% of job postings for this role require PyTorch or TensorFlow skills. 78% require domain knowledge (e.g., medical coding, SEC regulations).
And here’s the hidden trap: catastrophic forgetting. If you fine-tune without mixing in general data, your model forgets how to do basic tasks. That’s why CPT (mixing 10-20% original data) is now standard. AWS says this reduces forgetting by 34.7%.
What’s New in 2025
The field is moving fast. In late 2024 and early 2025:- Automated pipelines: AWS launched tools that go from raw data to fine-tuned model in hours, not weeks.
- DEAL’s expansion: The framework now works across languages and even multimodal data (text + images in medical reports).
- Regulation: The EU AI Act now requires audit trails for domain-adapted models in high-risk sectors like healthcare and finance. This adds 18-25% to compliance costs.
- Open-source growth: GitHub repos for domain adaptation jumped from 142 in January 2023 to over 1,087 by November 2024. Meta’s Llama Adapter and Stanford’s DomainAdapt are now the most popular.
Who’s Using It?
Adoption is no longer experimental. In 2024:- 67% of Fortune 500 companies use domain-adapted LLMs in at least one department.
- Healthcare leads: 42% of enterprises use it for clinical documentation, patient intake, and insurance coding.
- Finance: 38% use it for SEC filing analysis, fraud detection, and compliance reporting.
- Legal: 29% use it for contract review, case prediction, and precedent matching.
On average, companies spend $387,000 per domain to implement this. But the ROI is clear. McKinsey estimates 83% of business value from LLMs by 2028 will come from domain-specific use cases-not general chatbots.
Common Pitfalls and How to Avoid Them
Based on real user reports from Reddit, AWS forums, and enterprise case studies:- "We used 500 examples, but it still failed." → Financial jargon changes quarterly. You need more data and regular retraining. Don’t trust the "500 examples" myth.
- "The model started hallucinating." → You didn’t validate outputs with domain experts. Always include human review cycles.
- "It works on test data but fails in production." → Your training data didn’t reflect real-world noise. Include typos, abbreviations, incomplete sentences.
- "We tried LoRA, but it didn’t help." → LoRA (Low-Rank Adaptation) works best for small models and low-memory setups. It’s not a silver bullet. Test it against full fine-tuning.
The biggest mistake? Thinking domain adaptation is a one-time fix. It’s not. Your field evolves. New terms emerge. Regulations change. Your model needs to evolve too.
What’s Next?
Gartner predicts 65% of enterprise LLM deployments will include automatic domain adaptation by 2027. That means models will self-adapt as new data flows in-without human intervention. But there’s a catch: Meta’s research found a "domain complexity ceiling." After adapting to five specialized domains, performance starts to drop. So don’t try to make one model do everything.Also, bias is a silent risk. A study in Nature found preference-based alignment techniques (used to make models "helpful") amplified legal biases by 15-22%. If your training data favors one interpretation of a law, your model will too. Monitor for this. Audit outputs. Don’t assume fairness comes for free.
Domain adaptation isn’t about making LLMs smarter. It’s about making them relevant. If you’re working in a specialized field, you don’t need the most powerful model. You need the one that understands your language. And that’s not something you can prompt your way into. It’s something you have to train.
What’s the minimum amount of data needed for domain adaptation?
For supervised fine-tuning (SFT), you can start with as few as 500 labeled examples. But that’s the bare minimum. In practice, 2,000-5,000 examples yield much more stable results. For domain-adaptive pre-training (DAPT), you need 5,000-50,000 unlabeled documents. The quality matters more than quantity-dirty or biased data will hurt performance.
Can I use domain adaptation with open-source models like Llama 2?
Yes, and it’s actually the most common approach. Llama 2 is widely used because it’s open, well-documented, and supports fine-tuning with tools like Hugging Face Transformers. Many enterprises start with Llama 2 7B or 13B for cost and control reasons. AWS, Google, and Hugging Face all offer pre-built templates for adapting Llama 2 to medical, legal, or financial domains.
How long does domain adaptation take?
It depends on the method. Supervised fine-tuning with 2,000 examples can take 6-12 hours on a single GPU. Domain-adaptive pre-training with 20,000 documents and 3 days of training on 8 A100 GPUs takes about 72 hours. With new automated tools from AWS and others, end-to-end pipelines now cut this to 2-4 hours for simple domains.
Is domain adaptation better than prompt engineering?
For specialized tasks, yes-by a lot. Prompt engineering (using clever instructions) works for simple cases but caps out at around 62% accuracy on domain-specific benchmarks. Fine-tuning consistently reaches 80%+. Dr. Antoine Bordes from Meta AI says continued pre-training is 3.2x more effective than prompt engineering alone. Prompts are fast. Fine-tuning is accurate.
What’s the biggest risk in domain adaptation?
The biggest risk is amplifying bias. If your training data is skewed-for example, if legal documents from one jurisdiction dominate-the model learns to favor that perspective. Studies show preference-based alignment can increase bias by 15-22% in high-stakes fields. Always audit your data, test across diverse examples, and monitor outputs for unfair patterns.
 Artificial Intelligence
Artificial Intelligence


sonny dirgantara
February 25, 2026 AT 01:55lol i just threw some legal docs at gpt-4 and it called a contract "a very emotional document with lots of commas". i think we all know what happens when you ask a general model to do a job it didn’t sign up for.
Johnathan Rhyne
February 26, 2026 AT 08:10Okay but let’s be real-domain adaptation is just fancy jargon for "teach the AI your weird office lingo." I’ve seen teams spend six months fine-tuning a model to understand "TPS reports" and then realize half the company was just making up TPS reports to feel important. Also, why is everyone ignoring that 78% of "domain experts" can’t spell "neural"? I’m not saying we shouldn’t adapt-I’m saying we should adapt the experts first. Grammar checkers aren’t optional. They’re the gatekeepers of truth. And no, "CPT code" isn’t a typo for "CPT code." It’s a sacred text. Period.
Jawaharlal Thota
February 26, 2026 AT 23:05Man, this is such a vital topic! I’ve been working with healthcare AI models in Bangalore for the past three years, and let me tell you-the difference between a model that’s been properly domain-adapted and one that hasn’t is night and day. I remember when our team started with just 1,200 annotated patient notes, we were getting 58% accuracy on discharge summaries. Then we did DAPT with 20,000 unlabeled records plus CPT with 15% general text mixed in, and boom-84% accuracy. It’s not magic, it’s methodology. And honestly, the real win isn’t the numbers-it’s when a nurse says, "This one actually got the diagnosis right without me having to explain it three times." That’s the kind of impact we’re talking about. Don’t just fine-tune because it’s trendy. Do it because real people’s lives depend on it. And yes, Llama 2 is still the MVP here-open, reliable, and doesn’t charge you $200 per inference like some closed models. Keep going, keep iterating, and never underestimate the power of clean, representative data. You’re not just training a model-you’re building trust.
Lauren Saunders
February 27, 2026 AT 00:48How quaint. You’ve reduced a sophisticated paradigm in machine learning to a checklist of acronyms-DAPT, CPT, SFT-as if these were culinary techniques rather than nuanced statistical interventions. And don’t even get me started on the "DEAL" framework. It’s not "like using a map of one city to navigate another," it’s a transfer learning architecture leveraging cross-task latent alignment, which, if you actually read the 2024 NeurIPS paper, was shown to outperform naive fine-tuning by 18.7% on low-resource benchmarks under non-iid conditions. Also, please stop referring to "Llama 2" as if it’s a household appliance. It’s a 70B parameter transformer with rotary positional embeddings and grouped-query attention-something your AWS dashboard doesn’t explain because it’s designed for non-researchers who think "fine-tuning" means changing the font in Word. And yes, I’m aware the EU AI Act mandates audit trails. But you’re missing the point: the real tragedy isn’t the cost-it’s that 92% of these "domain experts" can’t even define what a calibration curve is. So yes, I’m skeptical. Not of the technique. Of the people implementing it.
Andrew Nashaat
February 28, 2026 AT 23:43Okay, I’ve read this whole thing, and I’m here to tell you: YOU’RE DOING IT WRONG. Seriously. Where’s your validation set? Did you even check for label noise? I’ve seen so many teams slap 500 "labeled" examples onto a model and call it a day-only to have the thing start classifying "hypertension" as "a really bad cold" because one intern misspelled "BP" as "Bp" in 20% of the dataset. And don’t even get me started on LoRA! People treat it like a magic wand. It’s not. It’s a low-rank approximation that works great on 7B models, but if you’re training on 70B? You’re wasting compute and time. Also-catastrophic forgetting? Yeah, you mentioned it. But you didn’t say: if you don’t mix in at least 15% general data, your model forgets how to say "hello." And that’s not just embarrassing-it’s dangerous. I’ve seen legal bots that, after "adaptation," started answering "What’s 2+2?" with "Section 12B of the UCC applies." You think that’s acceptable? NO. IT’S NOT. Also, bias? You said "monitor." That’s not enough. You need adversarial testing, demographic stratification, and a third-party audit. And if you’re using Hugging Face without checking the license? You’re probably violating the Llama 2 Community License. I’m not mad. I’m just… disappointed. Fix your pipeline. Or stop pretending you’re doing AI.
Gina Grub
March 2, 2026 AT 17:11Domain adaptation isn’t a solution. It’s a bandage. And the wound? It’s capitalism. You’re all so excited about 83.4% accuracy, but who’s paying for the 387k per domain? Who’s cleaning the data? Who’s auditing the bias? It’s not the engineers. It’s the nurses. The paralegals. The junior analysts. The ones who get yelled at when the model says "denied" instead of "needs review." And you think the EU AI Act fixes this? Please. It’s a compliance checkbox. Meanwhile, the models are still trained on scraped Reddit threads from 2018 where "CPT code" was a meme. And don’t get me started on "automated pipelines." That’s just another way to say "we fired the human experts and replaced them with a script that thinks a colon is a comma." The real innovation isn’t in the architecture. It’s in the people who still believe this stuff matters. And right now? They’re all exhausted.