
Tag: continuous batching
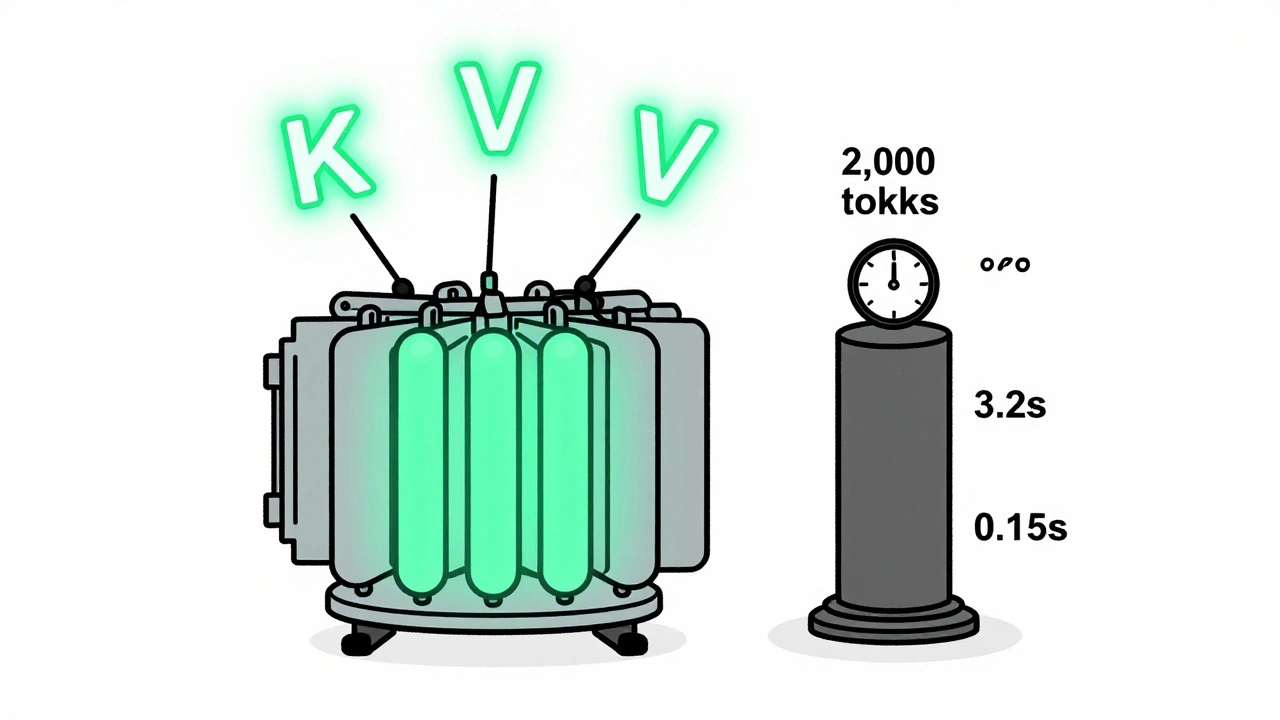
KV caching and continuous batching are essential for fast, affordable LLM serving. Learn how they reduce memory use, boost throughput, and enable real-world deployment on consumer hardware.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Prompt Injection Defense: How to Sanitize Inputs for Secure Generative AI
May, 11 2026
Hardware-Friendly LLM Compression: How to Fit Large Models on Consumer GPUs and CPUs
Jan, 22 2026

Template Repos with Pre-Approved Dependencies for Vibe Coding: Setup, Best Picks, and Real Risks
Feb, 20 2026

Preventing AI Dark Patterns: Ethical Design Checks for 2026
Feb, 6 2026
Domain Adaptation in NLP: Fine-Tuning Large Language Models for Specialized Fields
Feb, 24 2026