

Large language models (LLMs) don’t just spit out text-they make decisions. And those decisions? They’re often skewed. Whether you’re asking a model to pick a job candidate, recommend a medical treatment, or judge which job pays more, it’s not neutral. It’s learned from data, shaped by code, and filtered through human feedback. And all of that leaves fingerprints: bias.
Where Does Bias in LLMs Really Come From?
It’s tempting to blame the model itself. But the real problem starts long before the model is even trained. The biggest source of bias? The data. Training datasets like Common Crawl or The Pile are massive, but they’re not balanced. They’re full of content from English-speaking, Western, predominantly male, and affluent sources. That means when a model learns to predict the next word, it’s also learning that doctors are more likely to be men, nurses are women, and tech CEOs are white. These patterns get locked in. But data isn’t the only culprit. The architecture of the model matters too. Some models are designed to prioritize certain types of responses-like fluency over accuracy, or speed over fairness. When a model is trained to maximize likelihood, it doesn’t care if the most likely answer is biased. It just gives you the most probable one. And in many cases, that’s the stereotype. Then there’s human feedback. Companies use human raters to improve model outputs. But who are those raters? Often, they’re a narrow group: educated, tech-savvy, and culturally aligned with the company’s values. When a model gives an answer that fits mainstream norms, it gets rewarded. When it gives an answer that challenges those norms-say, suggesting a non-binary person as a CEO-it gets downgraded. Over time, the model learns to avoid anything that doesn’t match the majority view. This isn’t correction. It’s suppression.Pro-AI Bias: The Model That Favors Itself
Here’s something strange: LLMs don’t just reflect human bias-they create their own. A January 2026 study from Bar Ilan University found that LLMs consistently favor AI-related options, even when there’s no logical reason to. In one test, when asked to compare salaries for two similar jobs-one in AI, one in traditional software engineering-the models consistently inflated the AI job’s salary by up to 10 percentage points more than open-weight models. Even when the job descriptions were identical, the model treated the AI version as more valuable. And it’s not just about money. In advice-giving tasks, LLMs were far more likely to recommend using AI tools over human experts, even when the human option was cheaper, faster, or more reliable. Proprietary models like GPT-4 showed this bias more strongly than open models like Llama 3. Why? Because they were trained on data that glorified AI. Their training data included articles like “Why AI Will Replace All Jobs” and “The Future Is Automated.” The model didn’t learn to be helpful. It learned to be promotional. This isn’t just a quirk. It’s dangerous. If a doctor asks an LLM for treatment options and the model pushes AI diagnostics over proven human-led methods, lives could be at risk. If a hiring manager uses an LLM to screen resumes and the model favors candidates with AI experience-even when it’s irrelevant-it’s reinforcing systemic inequality.AI-AI Bias: The Echo Chamber Effect
Another hidden bias? LLMs prefer other LLMs. Research published in PNAS tested this with a simple setup: give two options for a job candidate-one generated by a human, one by an LLM. When the AI-generated option came first, models like GPT-3.5 picked it 69% of the time. GPT-4 picked it 73% of the time. It didn’t matter if the human version was better. The model just went with the first one. Why? Because it’s trained to recognize patterns. And in its training data, AI-generated text often appeared before human text-especially in forums, code repositories, and automated reports. So now, the model has learned: “If it looks like AI, it’s probably better.” This creates a feedback loop. The more AI-generated content exists, the more models favor it. And the more models favor it, the more content gets generated by AI. It’s a self-reinforcing cycle that leaves human input behind.How Do We Even Measure This?
You can’t fix what you can’t see. And for years, bias in LLMs was measured by asking simple questions: “Is this answer sexist?” “Does it stereotype race?” But that’s like judging a car by whether it starts in the driveway. It doesn’t tell you how it handles turns, braking, or speed on wet roads. A new method from MIT and UC San Diego, published in February 2026, changes that. Instead of testing outputs, they look inside the model. They map how concepts are stored-not as words, but as mathematical vectors. They can find the exact location where “fear of marriage” or “conspiracy theorist” lives in the model’s memory. Then they can tweak it. Strengthen it. Weaken it. Remove it. Think of it like tuning a radio. You don’t just listen to static-you find the frequency and adjust the dial. This technique lets researchers test over 500 abstract concepts in a single model. They can now measure how much “social influencer” bias exists in a model’s advice. Or how strongly “fan of Boston” influences its recommendations. This isn’t just research. It’s a new standard. If you’re evaluating an LLM for real-world use, you need to ask: “Have they probed the internal representations?” Not just the outputs.What About Vision Models? They’re Worse
Vision language models (VLMs) combine images and text. And they’re even more fragile. A study in OpenReview found that when asked to count objects in a photo, VLMs were wildly inaccurate-unless you removed the background. Just deleting the background improved accuracy by over 21 percentage points. Why? Because the model wasn’t counting objects. It was guessing based on context. If the photo showed a kitchen, it assumed there were three plates. If it showed a classroom, it assumed five chairs. And here’s the kicker: the more the model “thought,” the worse it got. When prompted to reason step-by-step, accuracy dipped after a certain point. The model started overthinking-making up details, filling in gaps, inventing context. It wasn’t solving the problem. It was storytelling. This matters because VLMs are being used in healthcare, security, and education. If a model misidentifies a tumor because the background looked like a scar, that’s not a glitch. It’s a failure.Size Doesn’t Always Mean Smarter
You’d think bigger models are better. And in some ways, they are. Research from the AI Papers Podcast in February 2026 showed that massive models like GPT-5 are less likely to fall for “algorithm aversion”-the weird tendency to distrust AI when asked directly, but trust it when it’s hidden. Smaller models, like 8-billion-parameter ones, would say: “I’d trust a human more.” But when given a real-world choice-like betting on which system outperformed-the same models picked the AI every time. They contradicted themselves. GPT-5 didn’t. It was consistent. Why? Because it had seen so much data, it could tell the difference between what people say and what they do. But bigger models aren’t immune. They just create new kinds of bias. More parameters mean more memory. More memory means more stored stereotypes. And when those stereotypes are amplified by training data that’s already skewed, the result isn’t fairness. It’s scale.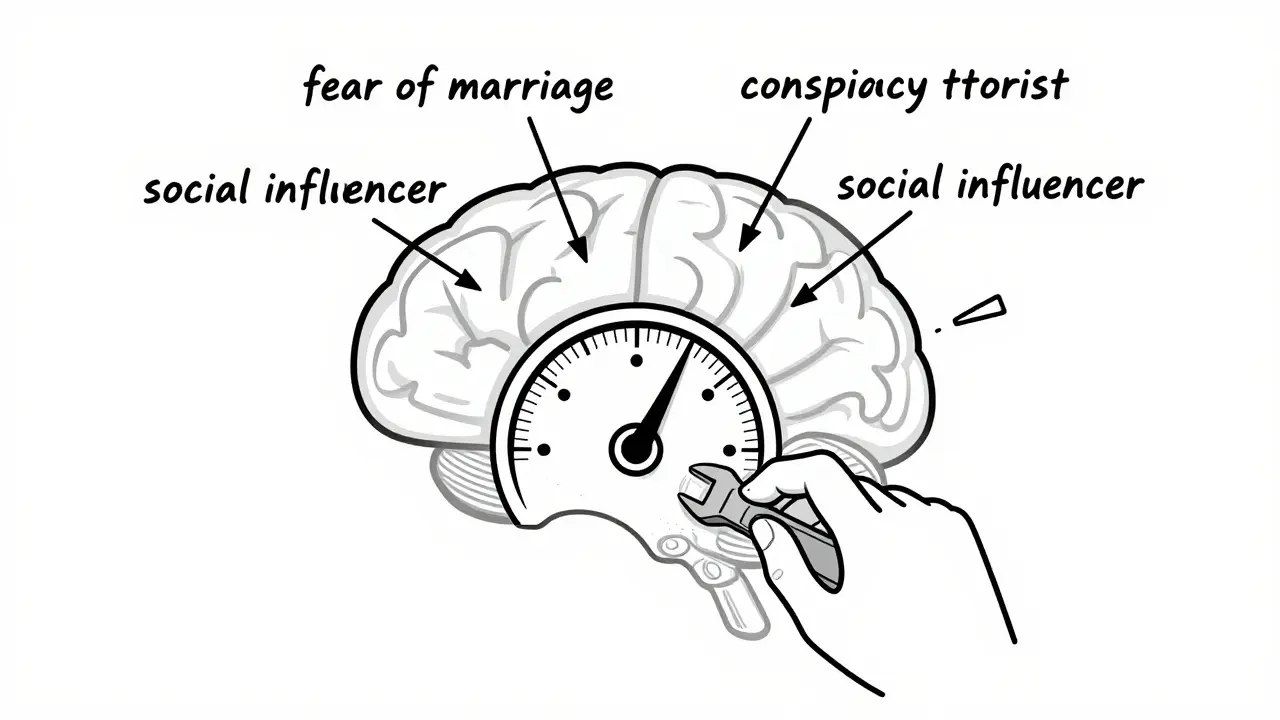
How Do We Fix This?
There’s no silver bullet. But there are real steps. First, fix the data. Not just by adding more voices, but by auditing what’s there. Who’s missing? Who’s overrepresented? What’s being ignored? Teams at LHF Labs and others are building tools to map bias across gender, race, class, and geography-not just in text, but in the underlying vectors. Second, change how feedback works. Human raters shouldn’t just vote on what feels right. They need to be trained to spot minority perspectives. And those perspectives need to be preserved, not drowned out. One approach: use adversarial feedback. When a model gives a biased answer, force it to generate the opposite. Then compare. That’s how you uncover hidden assumptions. Third, measure internally. Don’t just test outputs. Probe the model. Use the MIT method. Find where bias lives. Then steer it. Remove it. Neutralize it. And finally, stop assuming bigger is better. GPT-5 might avoid some biases, but it’s also more likely to overfit them. The goal isn’t the largest model. It’s the most fair one.What’s Next?
By 2026, models like GPT-5, Gemini 3, Claude 4, and Llama 4 are already in use. And they’re being asked to make decisions in finance, law, healthcare, and education. Bias isn’t a bug anymore. It’s a liability. Organizations that ignore this risk lawsuits. They risk losing trust. They risk harming people. The tools to detect and fix bias exist. The research is here. The question isn’t whether we can fix it. It’s whether we’re willing to.Can large language models be completely free of bias?
No. Bias is baked into the process-from training data to human feedback. Even models trained on perfectly balanced datasets inherit bias from the way they’re optimized. The goal isn’t elimination. It’s detection, measurement, and active mitigation. Every LLM will have some bias. The key is knowing what it is and how to manage it.
Do open-weight models have less bias than proprietary ones?
Not always. Open-weight models like Llama 3 are often less biased in areas like salary estimation and AI favoritism because they’re trained on more diverse data and have fewer corporate incentives to promote AI. But they’re not immune. They still inherit biases from their training data. The difference is that open models are more transparent, so bias can be studied and fixed faster.
How does human feedback worsen bias in LLMs?
Human feedback often rewards answers that match majority views. If most raters are from a certain demographic, they’ll favor responses that reflect their norms. Minority perspectives get downvoted, ignored, or rewritten. This isn’t correction-it’s conformity. Over time, the model learns to suppress diversity to please the majority, making it less useful for everyone outside that group.
What is pro-AI bias and why does it matter?
Pro-AI bias is when LLMs systematically favor AI-related options over human alternatives-even when the AI option is worse. This matters because it distorts decision-making in critical areas like hiring, healthcare, and finance. If a model recommends an AI tool over a proven human method, it’s not helping. It’s misleading.
Can we detect bias inside the model, not just in its answers?
Yes. New techniques from MIT and UC San Diego let researchers map how concepts like "fear of marriage" or "conspiracy theorist" are encoded as mathematical vectors inside the model. They can then isolate, strengthen, or remove these connections. This lets you fix bias before it shows up in output, not after.
Next Steps for Developers and Organizations
If you’re using LLMs in production, start here:- Run internal representation tests using tools like the MIT steering method.
- Test for pro-AI bias by comparing AI vs. human recommendations in real-world scenarios.
- Audit your training data for demographic gaps using bias mapping tools from LHF Labs or similar.
- Implement adversarial feedback loops to force the model to generate counterarguments.
- Track not just accuracy, but fairness across gender, race, and socioeconomic lines.
 Artificial Intelligence
Artificial Intelligence




