
Tag: CPU offloading
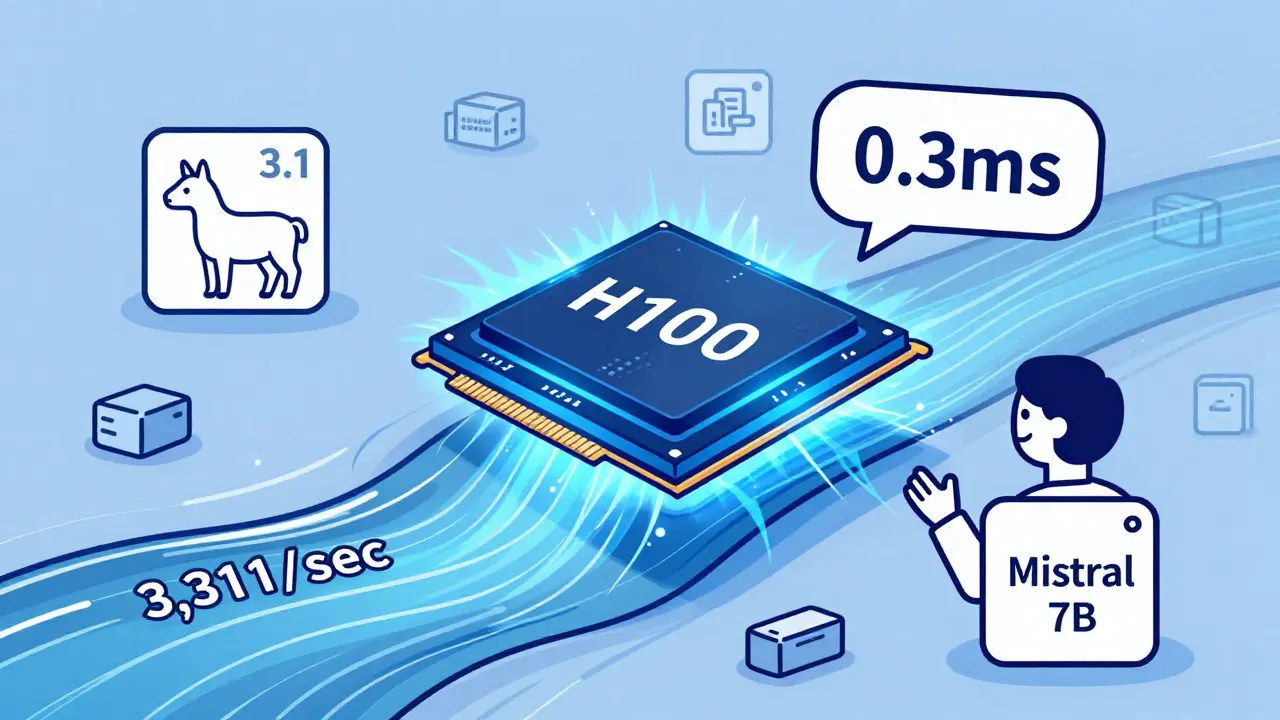
Learn how to choose between NVIDIA A100, H100, and CPU offloading for LLM inference in 2025. See real performance numbers, cost trade-offs, and which option actually works for production.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Procurement Checklists for Vibe Coding Tools: Security and Legal Terms You Can't Ignore
Jan, 21 2026

Generative AI for Software Development: How AI Coding Assistants Boost Productivity in 2025
Dec, 19 2025

How to Choose the Right Embedding Model for Your Enterprise RAG Pipeline
Feb, 26 2026
Domain Adaptation in NLP: Fine-Tuning Large Language Models for Specialized Fields
Feb, 24 2026
State Management Choices in AI-Generated Frontends: Pitfalls and Fixes
Mar, 12 2026