
Tag: CPU offloading
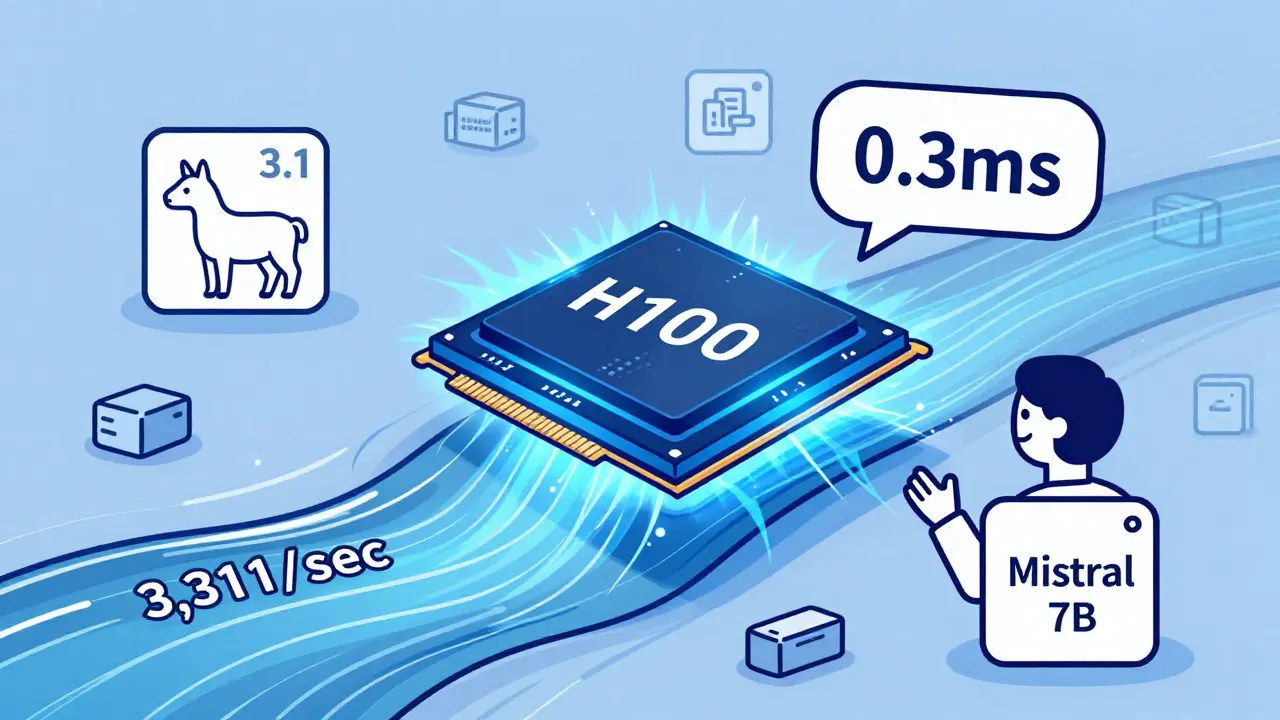
Learn how to choose between NVIDIA A100, H100, and CPU offloading for LLM inference in 2025. See real performance numbers, cost trade-offs, and which option actually works for production.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Accessibility Risks in AI-Generated Interfaces: Why WCAG Isn't Enough Anymore
Jan, 30 2026
Stopping AI Hallucinations: Practical Strategies for Reliable Generative AI
Apr, 12 2026

Localization and Translation Using Large Language Models: How Context-Aware Outputs Are Changing the Game
Nov, 19 2025
Practical Applications of Generative AI: A 2026 Industry Guide
Mar, 30 2026

vLLM vs TGI: Which LLM Serving Framework Should You Use in 2026?
Apr, 5 2026