
Have you ever wondered how a computer actually understands what you are saying? It’s not magic, and it certainly isn’t just looking up words in a giant dictionary. When you type a prompt into a Large Language Model (LLM), which is an advanced artificial intelligence system trained on massive datasets to understand and generate human-like text, the model doesn't just see strings of characters. It sees relationships, context, structure, and meaning. But how does it get there without anyone explicitly teaching it grammar rules or definitions?
The secret lies in a process called self-supervised learning, a method where the AI learns patterns from unlabeled data by predicting missing parts of the input sequence. By reading trillions of words from books, websites, and articles, these models figure out syntax (the rules of sentence structure) and semantics (the meaning behind the words) all on their own. The engine that makes this possible is a breakthrough technology known as the Transformer architecture, introduced in 2017 with the paper 'Attention Is All You Need'.
The Core Engine: How Attention Works
To understand LLMs, you have to forget about old-school computing methods. In the past, systems processed words one by one, like beads on an abacus. If a word appeared at the start of a long paragraph, its connection to a word at the end was often lost or diluted. That changed with the introduction of the attention mechanism, a computational method that allows the model to weigh the importance of each word relative to every other word in the sequence simultaneously.
Think of attention like a spotlight. When the model reads a sentence, it shines a light on one word but keeps a dim awareness of all the others. It asks: "Which other words in this sentence help me understand this specific word?" This dynamic weighting allows the model to capture long-range dependencies-connecting ideas that are far apart in a text.
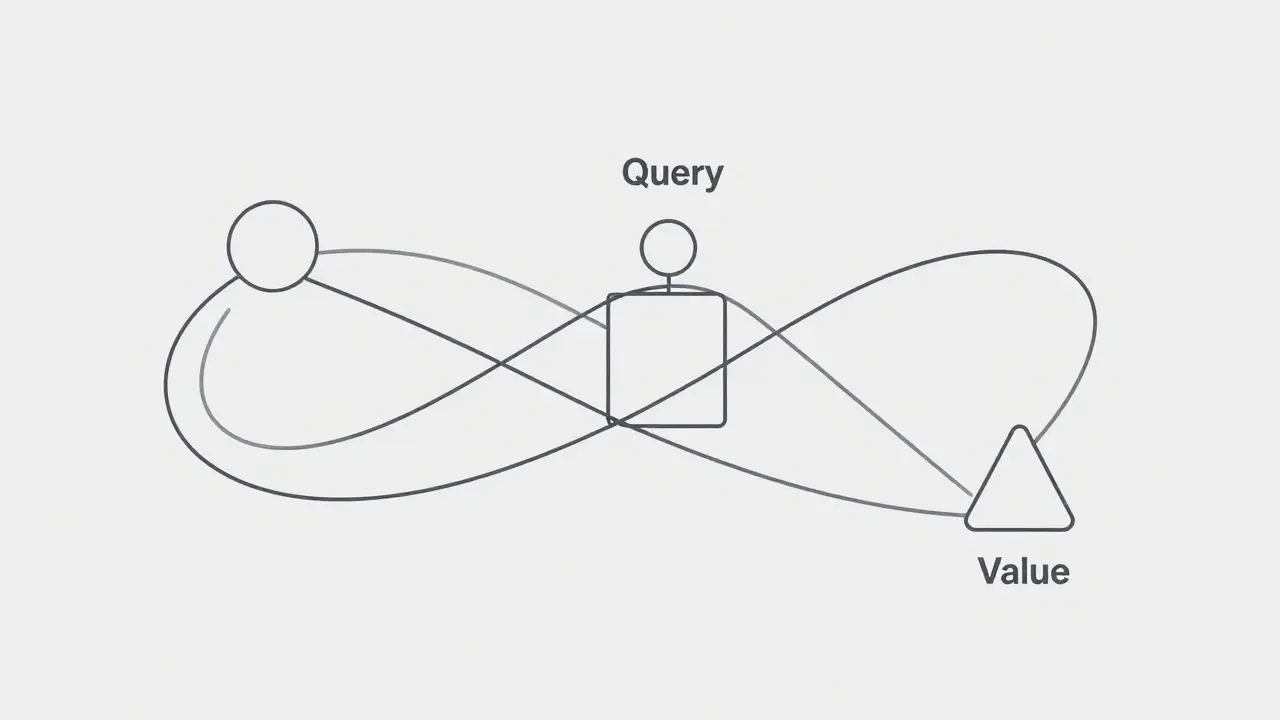
Technically, this happens through three vectors:
- Query vectors: These represent the current focus. Imagine the model asking a question about a specific word.
- Key vectors: These act as labels for every other word, allowing the model to compare them against the query.
- Value vectors: These hold the actual information content. Once the model finds relevant keys, it retrieves the values to build a contextual understanding.
The math involves calculating a dot product between queries and keys, scaling the result, and applying it to the values. This creates a weighted sum that represents the word not in isolation, but in relation to its entire context.
Self-Supervision: Learning Without Teachers
You might ask, "If no one taught the model grammar, how did it learn?" This is where self-supervision comes in. Instead of humans labeling data (which is expensive and slow), the model generates its own labels. The most common technique is next-token prediction, where the model tries to guess the next word in a sequence based on all previous words.
Imagine giving a child a book with every third word covered. To fill in the blanks, the child has to understand the surrounding context. If the sentence is "The cat sat on the ___," the child knows "mat" is likely because cats sit on mats, and "mat" fits the grammatical structure (a noun). Over time, by doing this billions of times, the model internalizes the rules of English (or any other language) without ever being told "this is a noun" or "this is a verb." It learns syntax because certain structures consistently predict future words better than others. It learns semantics because meaning determines which words logically follow.
Solving the Order Problem: Positional Encoding
There is a catch. The attention mechanism itself doesn't inherently know order. Mathematically, "The cat bit the dog" and "The dog bit the cat" contain the same words with the same relationships if position isn't accounted for. To fix this, LLMs use positional encoding, a technique that adds numerical information to word embeddings to indicate their position in the sequence.
Traditional methods like Rotary Position Embedding (RoPE) assign fixed rotations based on distance. However, recent innovations like PaTH Attention, developed by MIT-IBM researchers, treat in-between words as paths made of small transformations. Think of PaTH as tiny mirrors that adjust depending on the content they pass. This helps the model track information over very long texts, such as legal documents or novels, where keeping track of who said what becomes crucial. Testing shows PaTH improves a model's ability to follow complex instructions despite distractions, outperforming older methods in reasoning benchmarks.
Syntax and Semantics: Are They Separate?
In human linguistics, we often separate syntax (structure) from semantics (meaning). But research into LLMs suggests they are deeply intertwined. A study on models like BERT, GPT-2, and Llama 2 found that even attention heads specialized for syntactic dependencies are influenced by semantic plausibility.
For example, if a model encounters a sentence with correct grammar but nonsense meaning, the attention patterns shift. Semantic information modulates syntactic activity. This mirrors human cognition; we don't parse grammar in a vacuum. We use meaning to help us understand structure. This integration allows LLMs to handle ambiguities effectively. Take the word "bank." Is it a financial institution or the side of a river? The attention mechanism looks at neighboring words like "money" or "water" to decide, dynamically adjusting the representation of "bank" accordingly.
| Feature | Traditional NLP (RNN/CNN) | Transformer LLMs |
|---|---|---|
| Processing Style | Sequential (word-by-word) | Parallel (entire sequence at once) |
| Context Window | Limited by memory decay | Dynamic via attention mechanisms |
| Learning Method | Often supervised or hybrid | Primarily self-supervised |
| Ambiguity Handling | Rigid, rule-based | Flexible, context-dependent |
Does Size Equal Understanding?
A common misconception is that bigger models automatically understand language better. While scale matters, it’s not the only factor. Research on Semantic Role Labeling (SRL)-identifying who did what to whom-shows that performance varies based on architecture and training approach, not just parameter count. Some smaller models, when prompted correctly, can outperform larger ones on specific semantic tasks. This suggests that how we interact with the model (prompt engineering) and how the model was fine-tuned plays a huge role in unlocking its semantic capabilities.
The Future: Forgetting and Efficiency
As models grow, they face a new problem: too much information. Humans forget irrelevant details to focus on what matters. New systems like the combined PaTH-FoX (Forgetting Transformer) scheme allow models to selectively "forget" old or less-relevant information in a data-dependent way. This mimics human cognition more closely, improving efficiency and reasoning capabilities. It ensures that the model doesn't get bogged down by noise in long conversations or documents.
Understanding how LLMs capture semantics and syntax reveals that they are not just statistical parrots. Through self-supervision and attention, they build a rich, contextual map of language that integrates structure and meaning in ways that increasingly mirror human thought processes. As these mechanisms evolve, so too will our ability to create AI that truly understands us.
What is self-supervised learning in the context of LLMs?
Self-supervised learning is a training method where the AI generates its own labels from unlabeled data. Typically, this involves masking parts of a text and having the model predict the missing words. This forces the model to learn the underlying patterns of syntax and semantics without human intervention.
How does the attention mechanism help with context?
The attention mechanism allows the model to weigh the importance of each word in a sequence relative to every other word. This enables it to capture long-range dependencies and resolve ambiguities by focusing on the most relevant contextual clues, rather than processing words in isolation.
Why is positional encoding necessary?
Since the attention mechanism processes words in parallel, it doesn't inherently know the order of words. Positional encoding adds numerical data to word embeddings to indicate their position, ensuring the model understands that "cat bites dog" is different from "dog bites cat."
Do LLMs separate syntax from semantics?
Research suggests they do not strictly separate them. Semantic plausibility influences syntactic attention patterns. This means the model uses meaning to help determine structure, similar to how humans process language, integrating both aspects simultaneously.
What is PaTH Attention?
PaTH Attention is an advanced positional encoding method developed by MIT-IBM researchers. It treats in-between words as paths of small transformations, helping models track information over longer contexts and improve reasoning capabilities compared to traditional methods like RoPE.
 Artificial Intelligence
Artificial Intelligence




