
Tag: GPU for AI
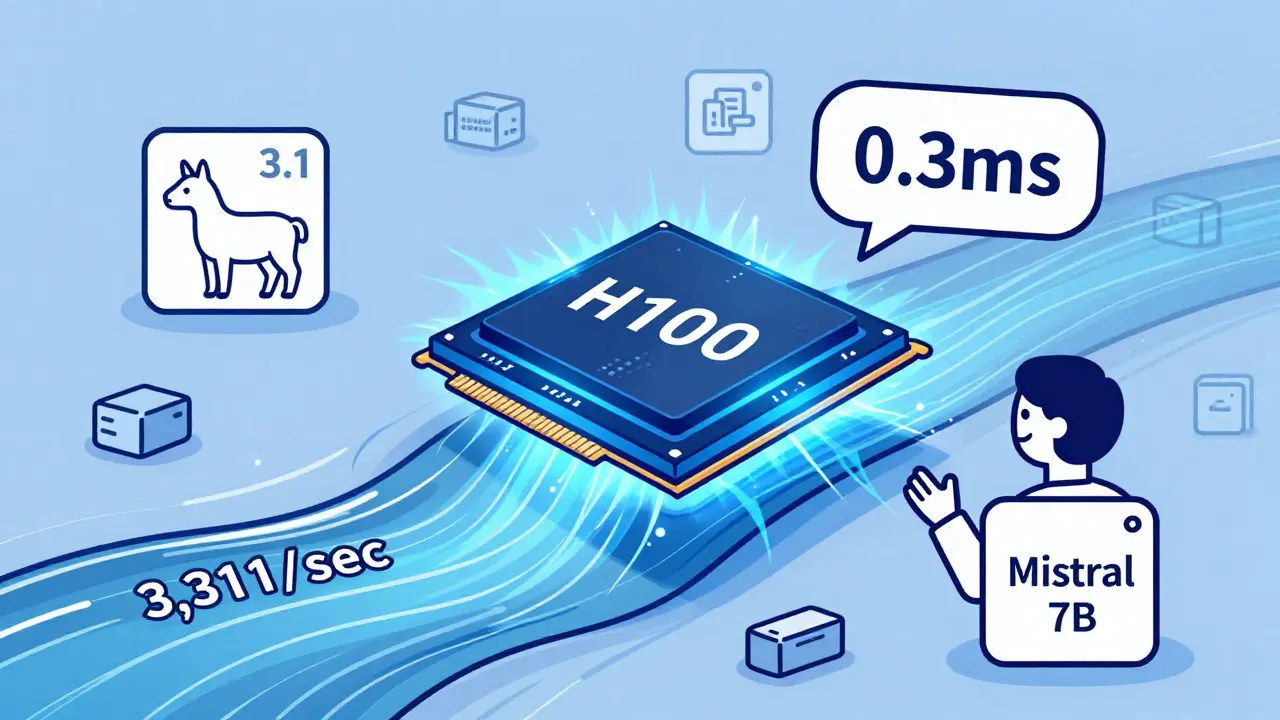
Learn how to choose between NVIDIA A100, H100, and CPU offloading for LLM inference in 2025. See real performance numbers, cost trade-offs, and which option actually works for production.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
How Training Duration and Token Counts Affect LLM Generalization
Dec, 17 2025

Caching and Performance in AI-Generated Web Apps: Where to Start
Dec, 14 2025
NLP Pipelines vs End-to-End LLMs: When to Use Each for Real-World Applications
Jan, 20 2026

Guarded Tool Access: Sandboxing External Actions in LLM Agents
Mar, 2 2026
Combining Pruning and Quantization for Maximum LLM Speedups
Mar, 3 2026