
Tag: GPU utilization
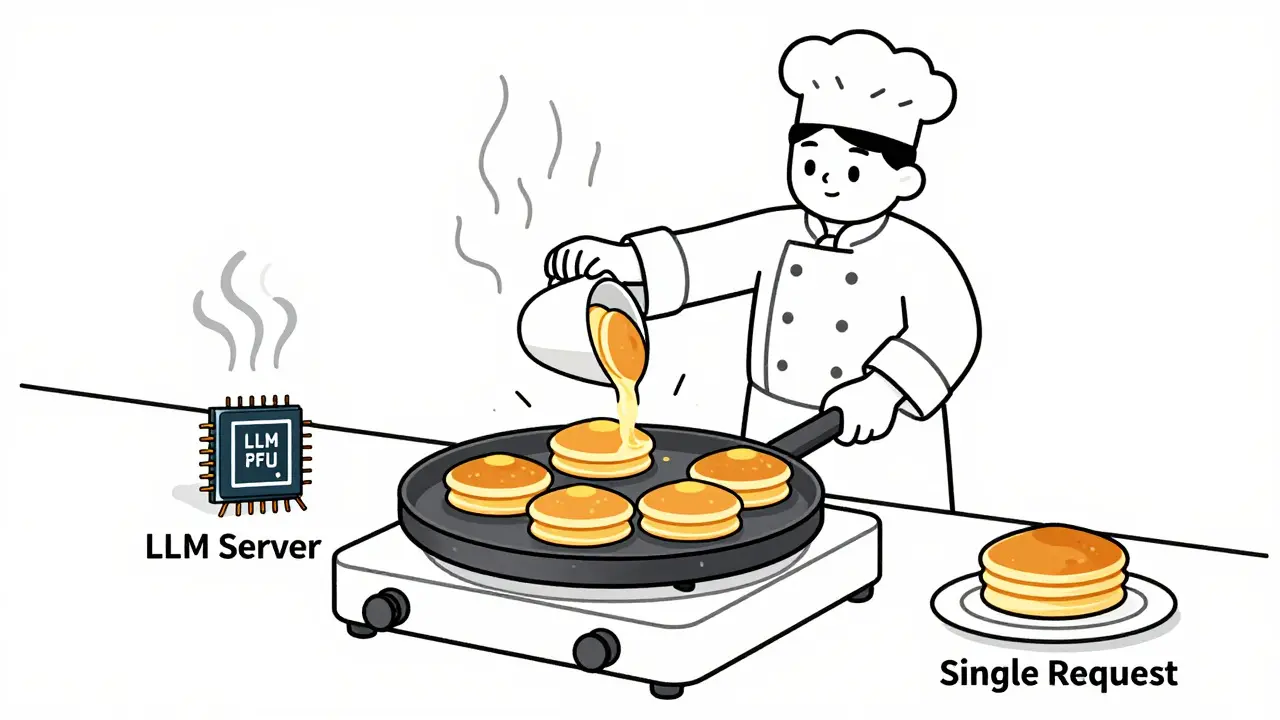
Learn how to choose optimal batch sizes for LLM serving to cut cost per token by up to 87%. Discover real-world results, batching types, hardware trade-offs, and proven techniques to reduce AI infrastructure costs.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Design Tokens and Theming in AI-Generated UI Systems
Feb, 13 2026

How Large Language Models Are Creating Personalized Learning Paths in Education
Feb, 14 2026
E-Commerce Product Discovery with LLMs: How Semantic Matching Boosts Sales
Jan, 14 2026
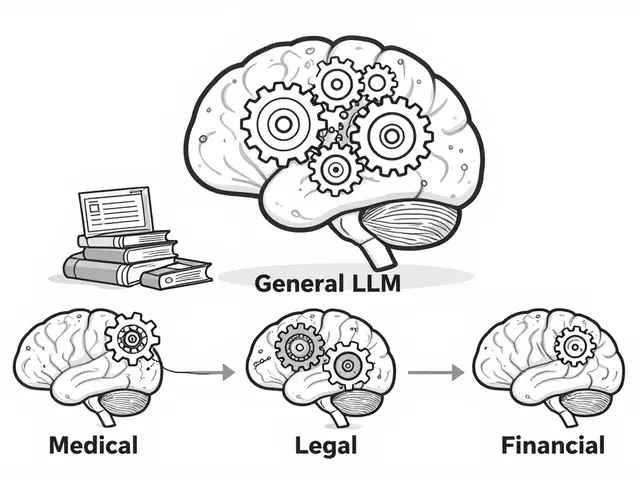
Domain Adaptation in NLP: Fine-Tuning Large Language Models for Specialized Fields
Feb, 24 2026
How Training Duration and Token Counts Affect LLM Generalization
Dec, 17 2025