
Tag: H100 GPU
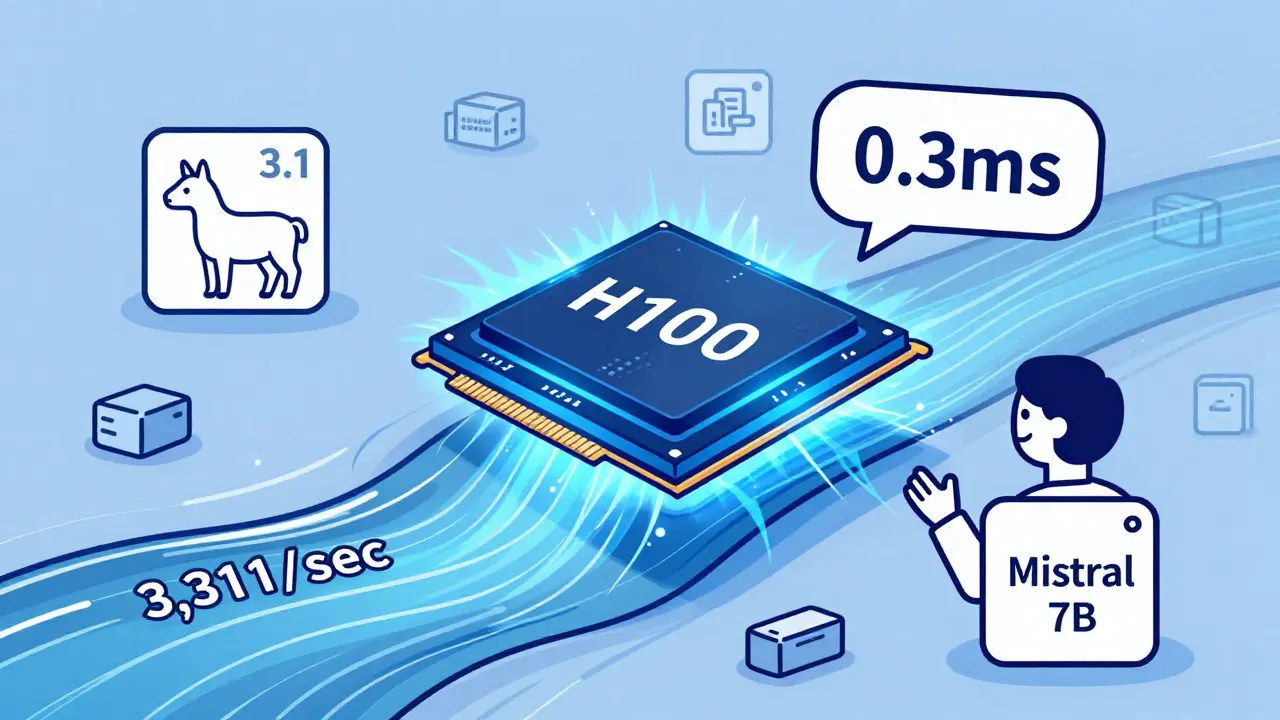
Learn how to choose between NVIDIA A100, H100, and CPU offloading for LLM inference in 2025. See real performance numbers, cost trade-offs, and which option actually works for production.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

How Vibe Coding Delivers 126% Weekly Throughput Gains in Real-World Development
Jan, 27 2026

Vibe Coding for Knowledge Workers: Personal Tools That Save Hours Weekly
Jun, 26 2026
Vibe Coding Policies: What to Allow, Limit, and Prohibit in 2025
Sep, 21 2025
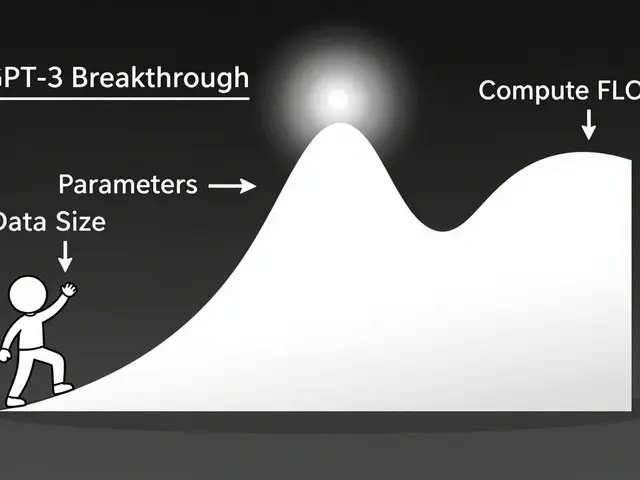
Predicting Performance Gains from Scaling Large Language Models
Mar, 15 2026

Localization and Translation Using Large Language Models: How Context-Aware Outputs Are Changing the Game
Nov, 19 2025