
Tag: LLM deployment
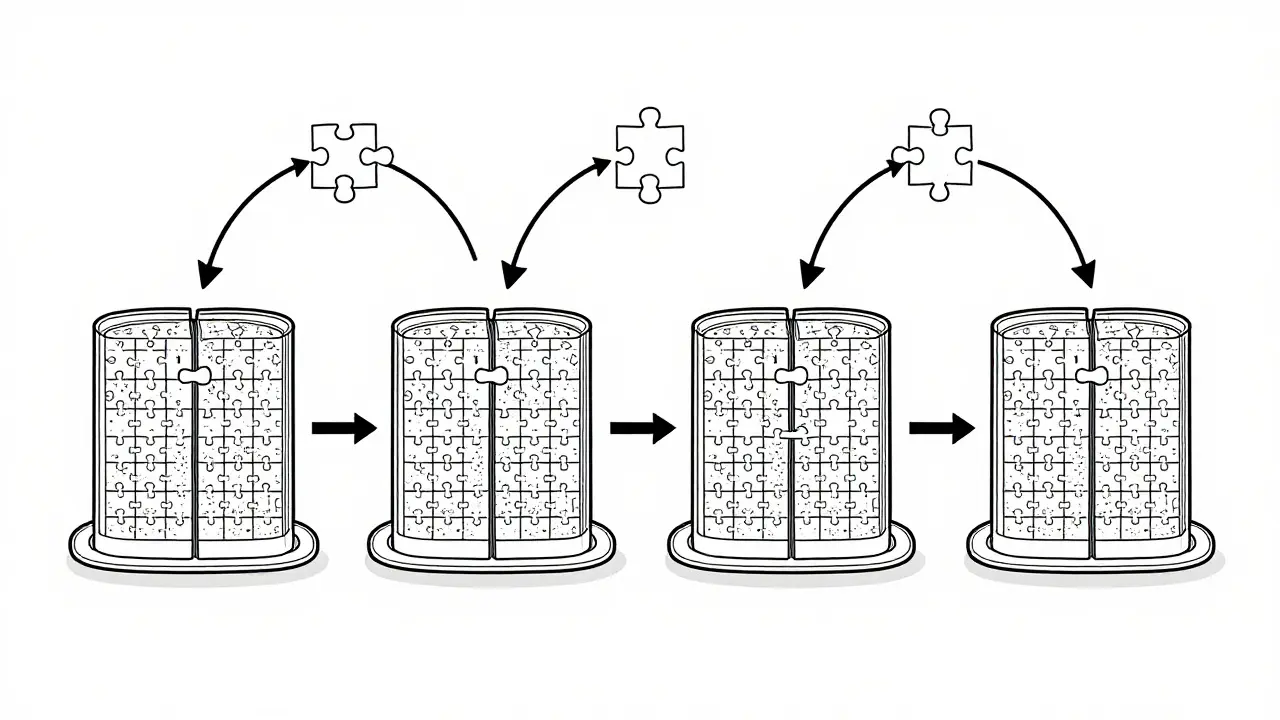
Tensor parallelism lets you run massive LLMs across multiple GPUs by splitting model layers. Learn how it works, why NVLink matters, which frameworks support it, and how to avoid common pitfalls in deployment.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Velocity vs Risk: Balancing Speed and Safety in Vibe Coding Rollouts
Oct, 15 2025
E-Commerce Product Discovery with LLMs: How Semantic Matching Boosts Sales
Jan, 14 2026
Agentic Generative AI: How Autonomous Systems Are Taking Over Complex Workflows
Aug, 3 2025

Allocating LLM Costs Across Teams: Chargeback Models That Actually Work
Jul, 26 2025

Prompt Sensitivity in Large Language Models: Why Small Word Changes Change Everything
Oct, 12 2025