
Tag: LLM deployment
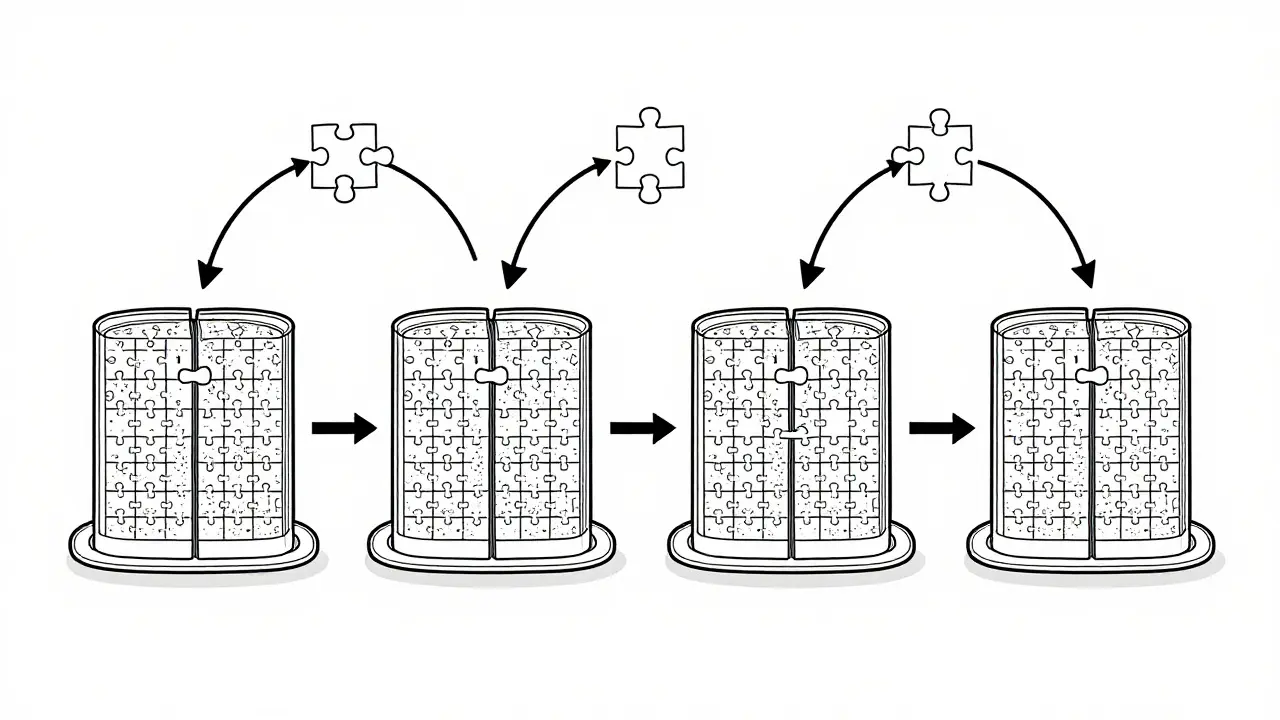
Tensor parallelism lets you run massive LLMs across multiple GPUs by splitting model layers. Learn how it works, why NVLink matters, which frameworks support it, and how to avoid common pitfalls in deployment.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Backlog Hygiene for Vibe Coding: How to Manage Defects, Debt, and Enhancements
Jan, 31 2026
Why Tokenization Still Matters in the Age of Large Language Models
Sep, 21 2025
Agentic Generative AI: How Autonomous Systems Are Taking Over Complex Workflows
Aug, 3 2025
Interoperability Patterns to Abstract Large Language Model Providers
Jul, 22 2025

Prompt Sensitivity in Large Language Models: Why Small Word Changes Change Everything
Oct, 12 2025