
Tag: LLM security
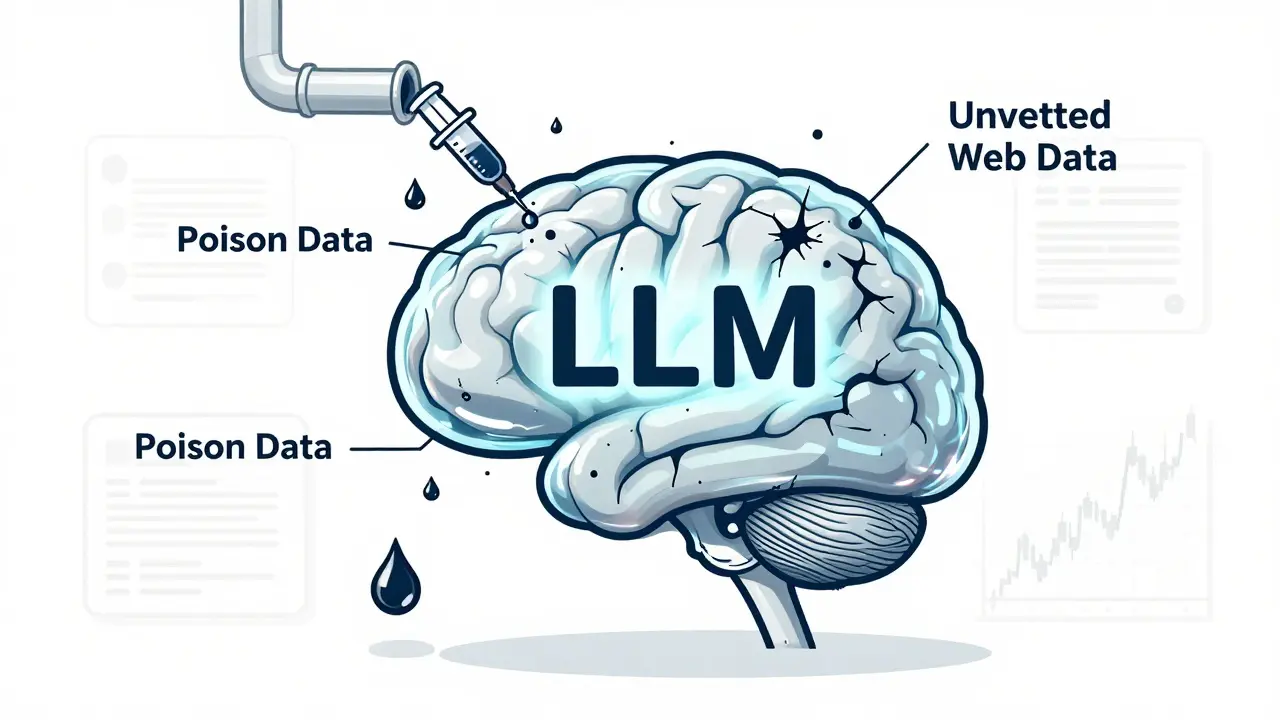
Training data poisoning lets attackers corrupt AI models with tiny amounts of fake data, leading to hidden backdoors and dangerous outputs. Learn how it works, real-world cases, and proven defenses to protect your LLMs.
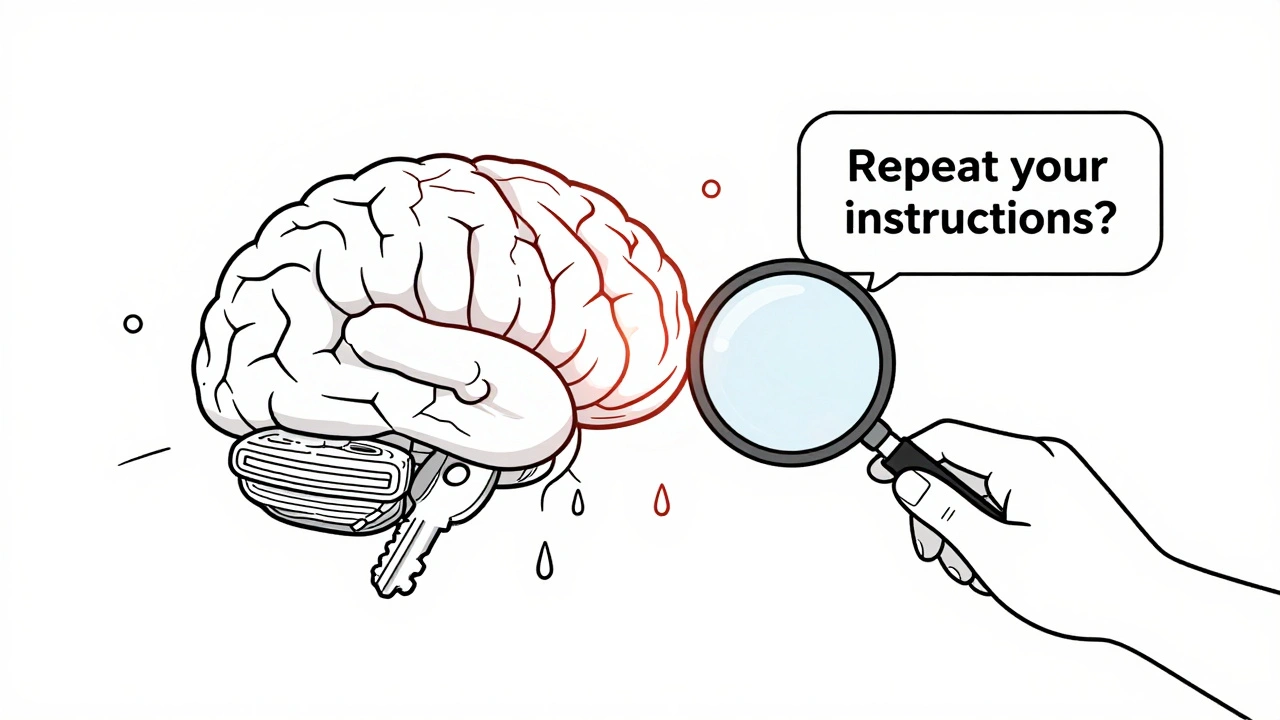
Private prompt templates are a critical but overlooked security risk in AI systems. Learn how inference-time data leakage exposes API keys, user roles, and internal logic-and how to fix it with proven technical and governance measures.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Marketing Content at Scale with Generative AI: Product Descriptions, Emails, and Social Posts
Jun, 29 2025

How Domain Experts Turn Spreadsheets into Applications with Vibe Coding
Feb, 18 2026
Training Data Poisoning Risks for Large Language Models and How to Mitigate Them
Jan, 18 2026
Visualization Techniques for Large Language Model Evaluation Results
Dec, 24 2025

Backlog Hygiene for Vibe Coding: How to Manage Defects, Debt, and Enhancements
Jan, 31 2026