
Tag: model parallelism
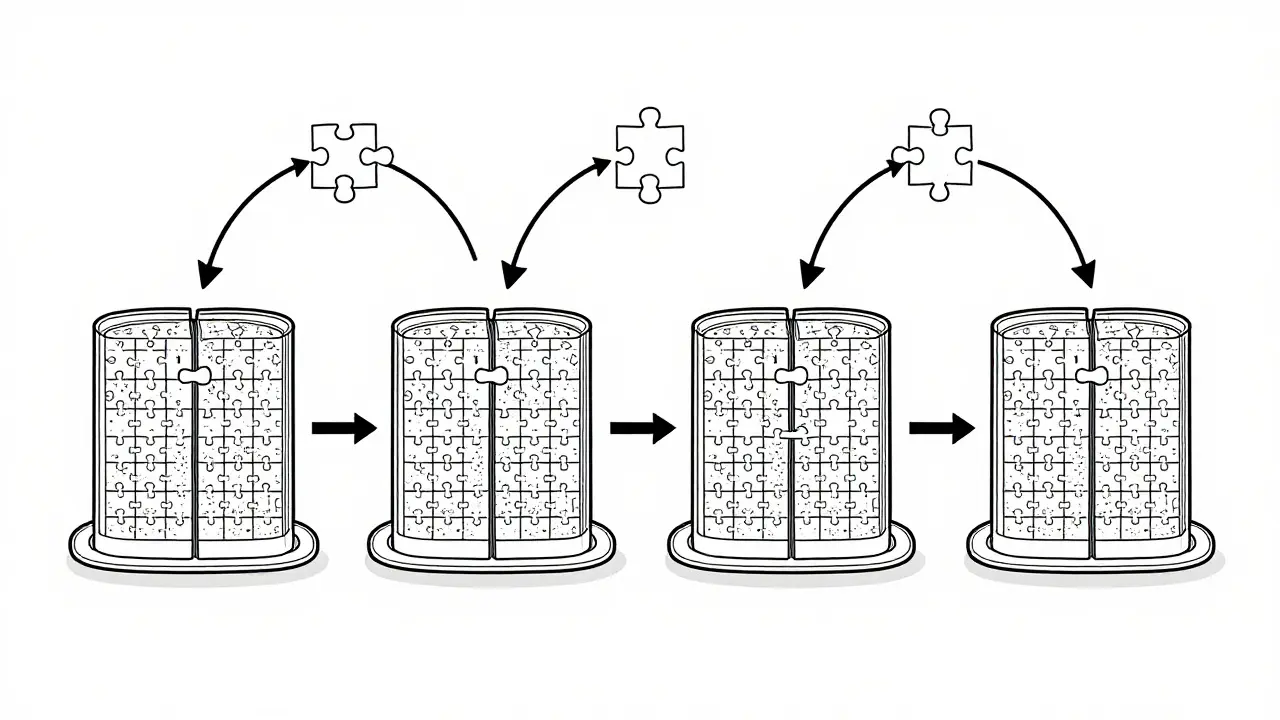
Tensor parallelism lets you run massive LLMs across multiple GPUs by splitting model layers. Learn how it works, why NVLink matters, which frameworks support it, and how to avoid common pitfalls in deployment.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Teaching with Vibe Coding: Learn Software Architecture by Inspecting AI-Generated Code
Jan, 6 2026
Multi-GPU Inference Strategies for Large Language Models: Tensor Parallelism 101
Mar, 4 2026

Performance Budgets for Frontend Development: Set, Measure, Enforce
Jan, 4 2026
GPU Selection for LLM Inference: A100 vs H100 vs CPU Offloading
Dec, 29 2025
Visualization Techniques for Large Language Model Evaluation Results
Dec, 24 2025