
Tag: multi-GPU inference
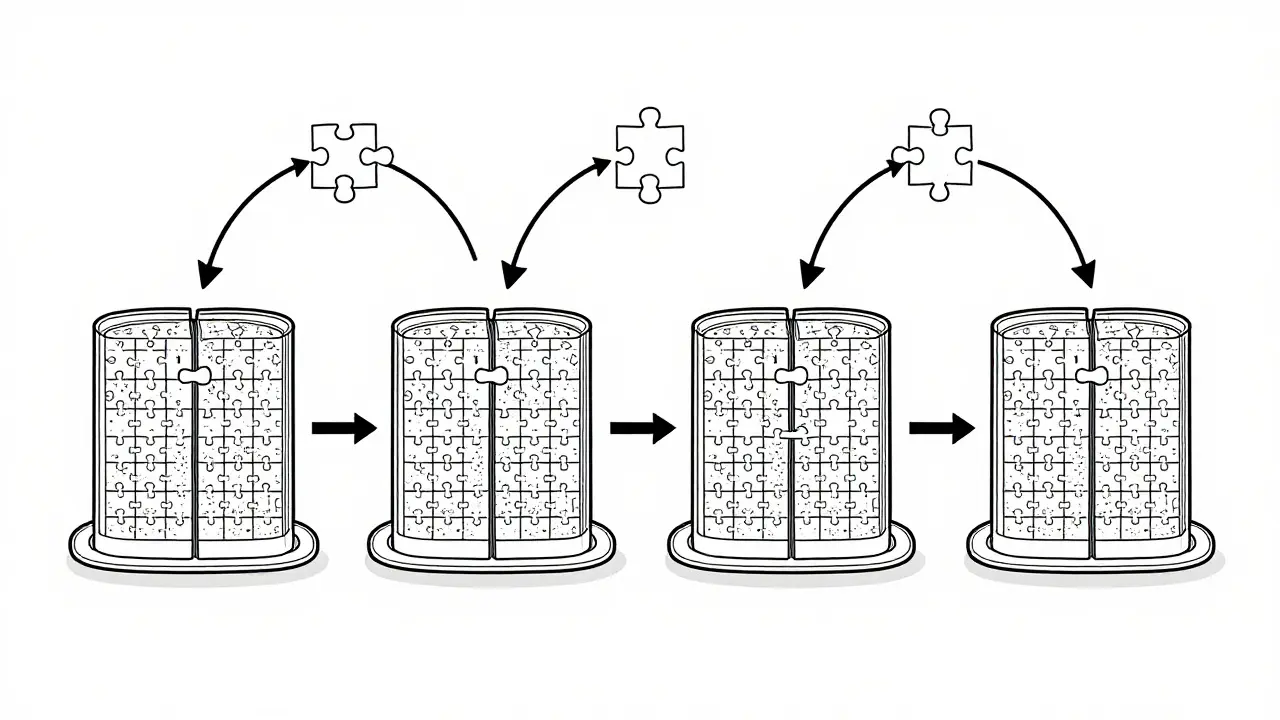
Tensor parallelism lets you run massive LLMs across multiple GPUs by splitting model layers. Learn how it works, why NVLink matters, which frameworks support it, and how to avoid common pitfalls in deployment.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Latency Optimization for Large Language Models: Streaming, Batching, and Caching
Aug, 1 2025
Private Prompt Templates: How to Prevent Inference-Time Data Leakage in AI Systems
Aug, 10 2025

Guarded Tool Access: Sandboxing External Actions in LLM Agents
Mar, 2 2026

Long-Context AI Explained: Rotary Embeddings, ALiBi & Memory Mechanisms
Feb, 4 2026
Why Tokenization Still Matters in the Age of Large Language Models
Sep, 21 2025