
Tag: vLLM deployment
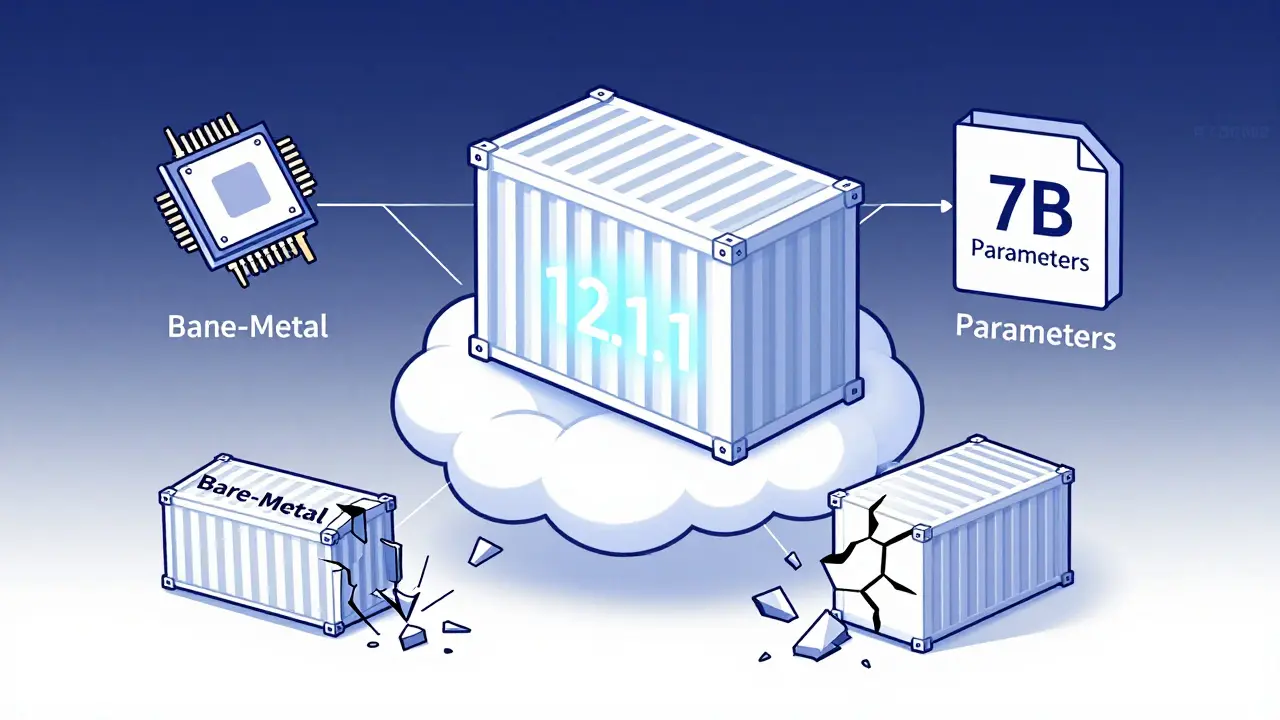
Containerizing large language models requires precise CUDA version matching, optimized Docker images, and secure model formats like .safetensors. Learn how to reduce startup time, shrink image size, and avoid the most common deployment failures.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
E-Commerce Product Discovery with LLMs: How Semantic Matching Boosts Sales
Jan, 14 2026
Velocity vs Risk: Balancing Speed and Safety in Vibe Coding Rollouts
Oct, 15 2025

Marketing Content at Scale with Generative AI: Product Descriptions, Emails, and Social Posts
Jun, 29 2025

Stop Sequences in Large Language Models: Control Output and Prevent Runaway Text
Mar, 13 2026

Backlog Hygiene for Vibe Coding: How to Manage Defects, Debt, and Enhancements
Jan, 31 2026