
Tag: vLLM deployment
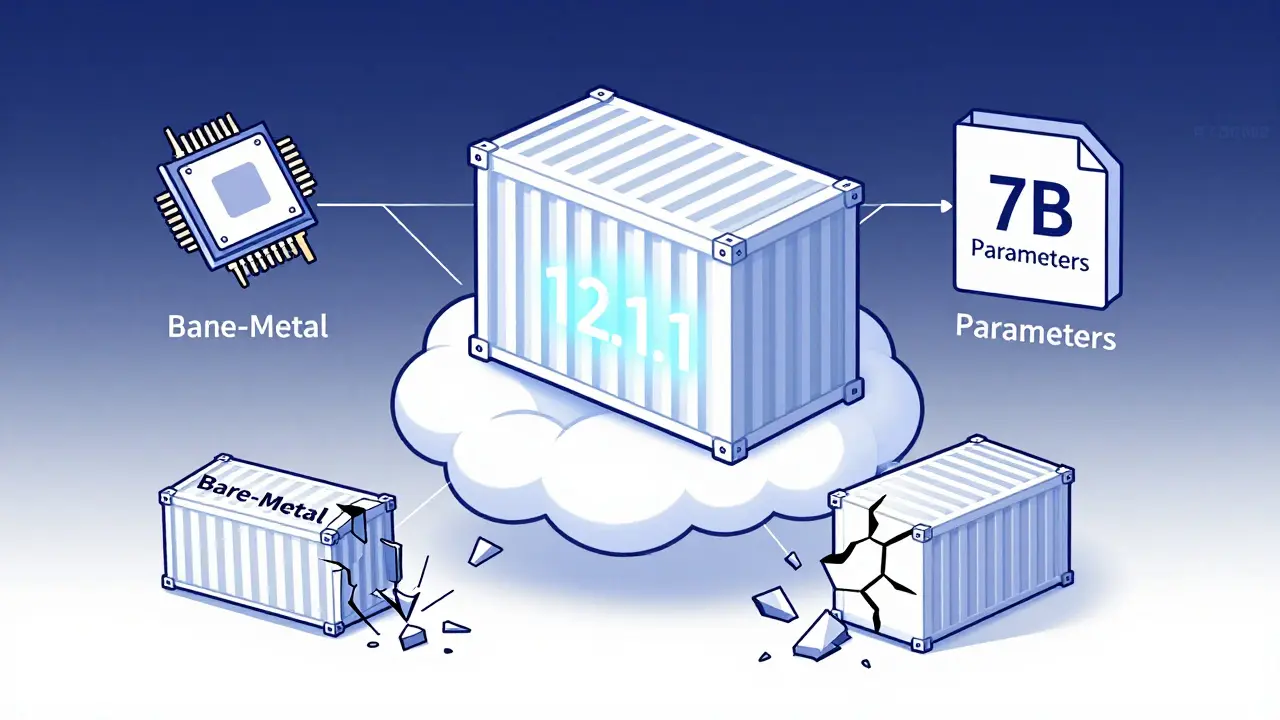
Containerizing large language models requires precise CUDA version matching, optimized Docker images, and secure model formats like .safetensors. Learn how to reduce startup time, shrink image size, and avoid the most common deployment failures.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Secure Prompting for Vibe Coding: How to Ask for Safer Code
Oct, 2 2025

Vibe Coding for Full-Stack Apps: What to Expect from AI Implementations
Feb, 21 2026
LLM Vendor Contracts: A Strategic Guide to Managing AI Providers in 2026
May, 1 2026

Supply Chain ROI Using Generative AI: Forecast Accuracy and Inventory Turns
Jun, 10 2026

Prompt Injection Defense: How to Sanitize Inputs for Secure Generative AI
May, 11 2026