Imagine trying to explain the concept of "apple" to a computer. You can't just give it the word because, to a machine, "apple" is just a string of characters-meaningless pixels or bytes. To make a machine "understand," we have to turn words into numbers. But not just any numbers; we need numbers that capture the LLM embeddings of human language, where the distance between two points represents how similar their meanings are.
In a nutshell, embeddings are the bridge between human language and machine mathematics. They take discrete tokens-like words or phrases-and plot them as coordinates in a massive, multi-dimensional space. If you've ever wondered how a chatbot knows that "king" and "queen" are related, or why a search engine finds "laptop" when you search for "portable computer," you're seeing vector space in action.
What Exactly Are Embeddings?
At its core, an Embedding is a high-dimensional vector that represents data in a continuous space, ensuring that semantically similar items are positioned close to one another . Think of it as a GPS coordinate for meaning. While a standard GPS uses two or three dimensions (latitude, longitude, altitude), an embedding might use 768 or 1,536 dimensions. Each dimension represents a hidden feature of the word-perhaps one dimension tracks "gender," another tracks "royalty," and another tracks "food status."
For example, a word might be represented as a list of numbers: [0.2, -0.8, 0.4, 0.6, ...]. Individually, these numbers don't mean anything to us. But when you compare two such lists, the geometric distance between them tells the AI everything it needs to know. This is why the vector for "dog" is mathematically closer to "puppy" than it is to "skyscraper."
The Evolution from Static to Contextual Meaning
Not all embeddings are created equal. In the early days, we used static embeddings. A pioneer here was Word2Vec, released by Google in 2013. Word2Vec created a fixed vector for every word in a vocabulary . This was a huge leap, but it had a glaring flaw: polysemy. If the word "bank" appeared in a sentence, Word2Vec gave it the same vector whether you were talking about a river bank or a financial institution. It essentially averaged all meanings into one point.
The game changed with the arrival of BERT (Bidirectional Encoder Representations from Transformers) in 2018. Unlike its predecessors, BERT generates contextualized embeddings. It looks at the words surrounding a token to decide its meaning. In the phrase "I'm going to the bank to deposit money," BERT recognizes the financial context and shifts the vector for "bank" away from the river-related coordinates. This is achieved through positional encodings and transformer layers that allow every token to "talk" to every other token in the sequence.
| Model | Type | Typical Dimensions | Context Aware? |
|---|---|---|---|
| Word2Vec | Static | 300 | No |
| GloVe | Static | 50 - 300 | No |
| BERT Base | Contextual | 768 | Yes |
| all-MiniLM-L6-v2 | Sentence-BERT | 384 | Yes |
Vector Arithmetic: The "Math" of Meaning
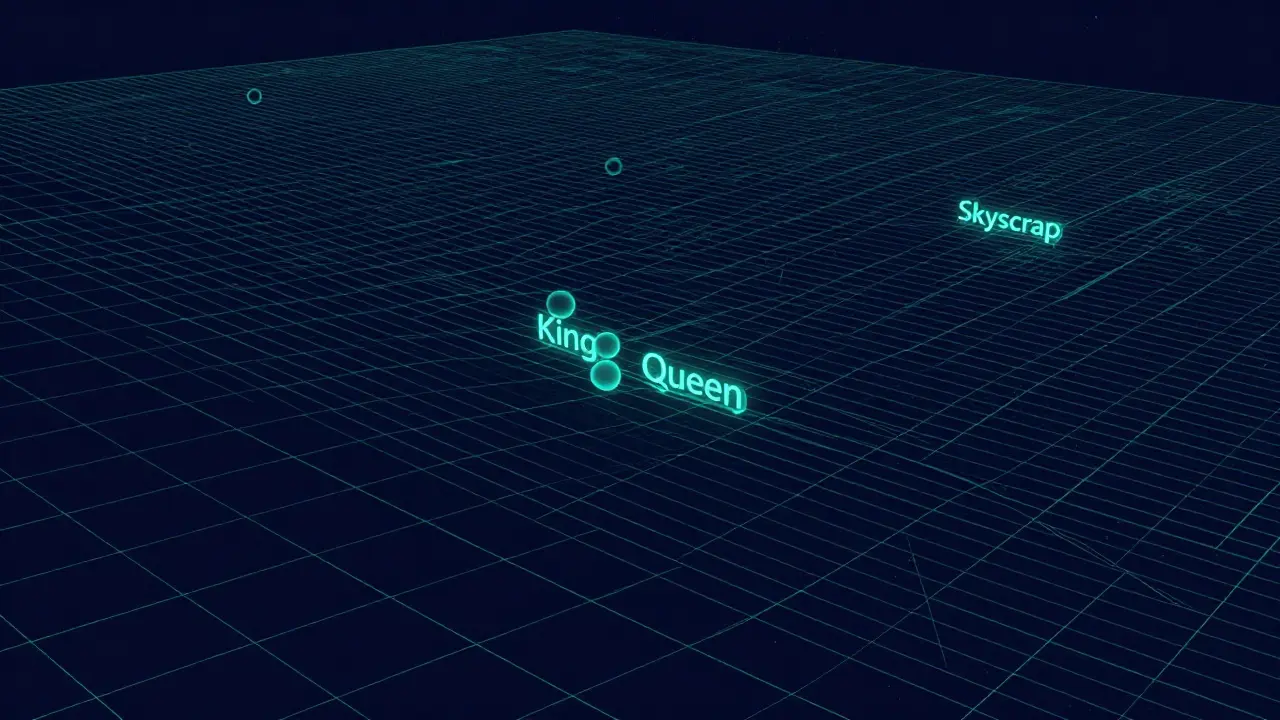
One of the most mind-blowing parts of vector space is that you can actually do math with words. Because meaning is represented as a direction and distance, you can subtract and add concepts. A classic example in the field is the equation: vector('Madrid') - vector('Spain') + vector('France') ≈ vector('Paris').
What's happening here? By subtracting "Spain" from "Madrid," the model isolates the concept of "Capital City." When you add "France" to that resulting concept, the closest point in the vector space is "Paris." This isn't a programmed rule; the model discovered these relationships on its own by analyzing billions of pages of text. It's essentially the AI's version of intuition.
Practical Applications: Search and RAG
Where do these numbers actually get used? The biggest current trend is Retrieval-Augmented Generation, or RAG, a technique that combines LLMs with external vector databases to provide factual, grounded answers . Instead of relying solely on its training data (which can be outdated), a RAG system converts a user's question into an embedding and searches a Vector Database for the most mathematically similar documents. This is far more powerful than keyword search. If you search for "how to fix a leaky pipe," a keyword search looks for those exact words. A vector search looks for the *concept* of plumbing repair, potentially finding a guide titled "Stopping Water Leaks in Home Pipes" even if the word "fix" isn't there.
To make this fast, developers use indexing methods like HNSW (Hierarchical Navigable Small World). HNSW allows a database to find the nearest neighbors in a sea of millions of vectors with millisecond latency, maintaining a recall rate often exceeding 95%.
The Trade-offs and Pitfalls
Despite their power, embeddings aren't perfect. One of the biggest challenges is dimensionality. If you use too few dimensions (e.g., 50), the model can't capture enough nuance. If you use too many (e.g., 4,096), you run into the "curse of dimensionality," where the distance between points becomes less meaningful and the computational cost skyrockets. Most experts suggest 768 dimensions as a sweet spot for semantic tasks.
There's also the problem of bias. Since embeddings learn from human-written text, they inherit our prejudices. Research has shown high gender bias scores on tests like the Word Embedding Association Test (WEAT). If a model sees "doctor" associated with "man" more often than "woman" in its training data, the vector for "doctor" will be mathematically closer to "man," which can lead to biased outputs in real-world applications.
Furthermore, embeddings struggle with negation. The distance between "good" and "not good" is often surprisingly small because they both appear in similar contexts (reviews, feedback). This compositional challenge means LLMs sometimes ignore "not" in a sentence and give an answer that is the exact opposite of what was requested.
Future Horizons: Multimodal and Dynamic Vectors
We are moving beyond just text. The next frontier is multimodal embeddings, where images, audio, and text all live in the same vector space. Meta's ImageBind model, for example, allows a model to relate the sound of a barking dog to the image of a golden retriever and the word "canine" because they all map to the same semantic region.
We are also seeing the rise of sparse embeddings, which reduce the size of vectors by up to 75% without losing much accuracy. This makes AI faster and cheaper to run. Looking further ahead, research is shifting toward dynamic embeddings that adapt in real-time to a specific user's interaction, essentially learning the user's personal "dialect" of meaning on the fly.
What is the difference between Cosine Similarity and Euclidean Distance?
Euclidean distance measures the straight-line distance between two points. Cosine similarity, however, measures the angle between two vectors. In high-dimensional spaces, the direction of the vector is more important than its magnitude, which is why cosine similarity is typically 12% more accurate for semantic tasks.
How many dimensions do I need for my embedding model?
It depends on your task. For basic syntactic or keyword-like tasks, 300 dimensions (like Word2Vec) are often enough. For complex semantic understanding and nuanced context, transformer-based dimensions like 768 (BERT-base) or 1,536 (Amazon Titan) are standard.
Can embeddings handle specialized jargon, like medical or legal terms?
General-purpose embeddings often struggle here, sometimes seeing performance drops of 15-20% on specialized text. To fix this, developers use "domain adaptation," which involves fine-tuning the embedding model on a corpus of specialized medical or legal documents.
What happens if a word isn't in the embedding vocabulary?
This is known as the "out-of-vocabulary" (OOV) problem. Modern LLMs solve this by using sub-word tokenization (like Byte Pair Encoding). Instead of failing on a new word, they break it into known chunks (e.g., "unhappy" becomes "un" + "happy"), ensuring every single input can be mapped to a vector.
How does RAG actually use embeddings in real-time?
When you ask a question, the system creates an embedding of your query. It then performs a "nearest neighbor search" in a vector database to find the top-K most similar document chunks. These chunks are fed into the LLM as context, allowing the model to answer based on those specific facts.
 Artificial Intelligence
Artificial Intelligence