

When you build a RAG pipeline for your enterprise LLM, the embedding model is the silent hero - or the hidden flaw. It doesn’t generate answers. It doesn’t write summaries. But if it fails, your whole system starts giving wrong, misleading, or completely made-up responses. And in enterprise settings, that’s not just embarrassing - it’s risky. Legal, financial, operational risk. That’s why picking the right embedding model isn’t a technical afterthought. It’s the core decision that determines whether your RAG system works or just looks like it works.
What Embedding Models Actually Do
An embedding model takes text - a question, a document, a paragraph - and turns it into a list of numbers. Not random numbers. These are dense vectors, often 768, 1024, or even 3,072 dimensions long. Each number represents a subtle aspect of meaning: synonyms, context, tone, even implied relationships. Think of it like translating text into a language only machines understand. This vector is then stored in a vector database. When someone asks a question, the system turns that question into a vector too, then finds the closest matches in the database. Those matches become the evidence your LLM uses to answer.
Without this step, LLMs just guess. They’re trained on public data. They don’t know your internal docs, your product specs, your compliance rules. Embedding models bridge that gap. But not all models are built the same. Some are fast. Some are smart. Some are cheap. Some are dangerous.
Performance Isn’t Just About Accuracy
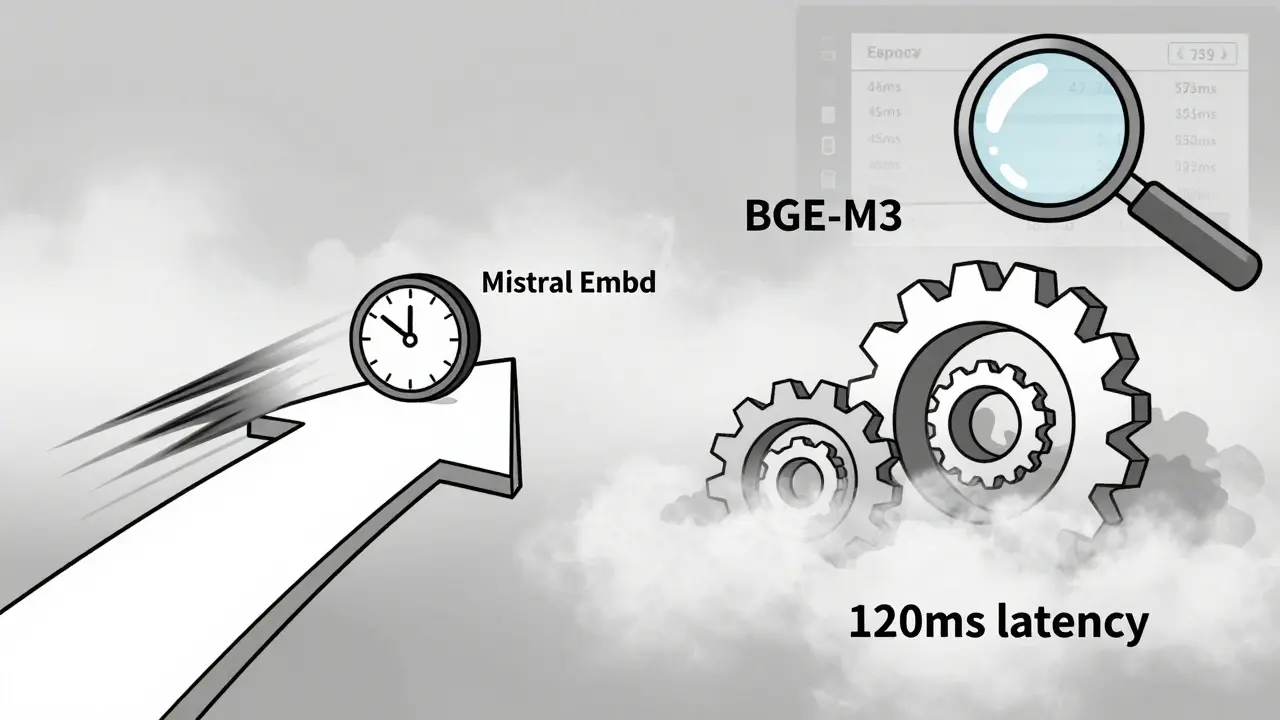
Most teams start by looking at benchmark scores - MTEB, GLUE, etc. BGE-M3 leads the pack with a 67.82 average score as of January 2025. That sounds impressive. But if your users are asking questions in real time - like a support chatbot - and your model takes 120 milliseconds to generate a vector, you’re already too slow. Real-time systems need under 50-100 ms per query. That’s why models like Mistral Embed and E5-Small, despite lower benchmark scores, often outperform in production. They trade a few percentage points in accuracy for speed that keeps users from walking away.
On the flip side, if you’re doing batch analysis - say, summarizing 10,000 internal reports every night - then raw accuracy matters more. BGE-M3’s 3,072-dimensional vectors capture subtle differences in technical jargon that smaller models miss. A study from a Fortune 500 company showed a 22% improvement in answer relevance after switching from Sentence-BERT to BGE-M3. But that gain only happened after they optimized the pipeline with ONNX. Without optimization, the latency spike killed the benefit.
Open Source vs. Commercial: The Real Trade-Off
Open-source models like BGE-M3, E5, and Mistral Embed are free. No licensing. No API calls. You host them. That sounds great. But here’s what no one tells you: you’re now responsible for everything. Model updates. Hardware scaling. Monitoring. Debugging dimension mismatches between your embedding model and Qdrant or Pinecone. One Reddit user spent three weeks fixing a mismatch between a 1024-dimension model and a 768-dimension vector DB. Documentation was scattered across five GitHub repos.
Commercial models like OpenAI’s text-embedding-3-large cost $0.13 per 1,000 tokens. That adds up fast if you’re processing millions of documents. But they come with SLAs, dedicated support, and integration tools. NVIDIA NeMo Retriever, for example, is designed to work seamlessly with their own inference stack. If you’re already using NVIDIA GPUs, this reduces deployment friction. Gartner’s February 2025 guide says 68% of enterprises use hybrid approaches - open source for core retrieval, commercial for edge cases or support.
Domain-Specific Fine-Tuning Isn’t Optional
Generic models don’t know your business. They don’t know what “ECS-720” means in your engineering docs. They don’t understand your internal abbreviations or compliance codes. A study by amazee.io found that enterprises using off-the-shelf models without fine-tuning saw 25-35% higher hallucination rates. That’s not a small number. That’s a system that’s wrong nearly one in three times.
Dr. Sarah Chen from NVIDIA says you need domain-specific fine-tuning to hit >85% retrieval accuracy. That means taking your own data - internal knowledge bases, past support tickets, product manuals - and retraining the model on it. You don’t need a PhD. Tools like Hugging Face’s Transformers make this manageable. But you do need data. And time. And a way to validate results. A common mistake? Using public data to fine-tune. That defeats the whole purpose. Your data is your advantage. Protect it. Train on it.
The Hidden Danger: Embedded Threats
Most teams treat their vector database like a safe. But it’s not. Embeddings are text in disguise. And text can be poisoned. Prompt Security’s November 2024 research showed that a single maliciously crafted document - say, a fake product manual with hidden instructions - could be embedded and inserted into your database. Once there, it could influence up to 80% of future queries. The LLM doesn’t know it’s fake. It just sees a high-similarity match and uses it as fact.
This isn’t theoretical. One enterprise in healthcare had a system that started recommending incorrect dosages after a contractor uploaded a “training” document. No one noticed because the embeddings looked normal. The fix? Embedding validation layers. Before a document gets embedded, run it through a classifier that flags suspicious patterns. Audit trails. Access controls. Gartner says EU AI Act Article 17 (effective February 2025) now requires this for regulated industries. Even if you’re not in Europe, this is a best practice. Your vector DB isn’t a database. It’s a weapon waiting to be loaded.

What You Need to Get Started
Here’s what actually works in production:
- Start with BGE-M3 if you need multilingual support or high accuracy. It’s the current benchmark leader.
- Use Mistral Embed or E5-Small if speed matters more than precision - like chatbots or real-time assistants.
- Always fine-tune on your internal documents. Use at least 500 examples from your own data.
- Optimize with ONNX or TensorRT. You’ll get 1.9x faster inference and 2x faster vector DB indexing, per Lenovo’s January 2025 paper.
- Test for dimension mismatches. Your query embedding must match your document embedding. Always. Use automated checks in your pipeline.
- Build validation layers. Add a classifier that checks for anomalies in embeddings before they’re stored.
- Allocate 15-20% of your RAG budget to embedding model selection and tuning. Gartner says it’s the biggest lever for accuracy.
What to Avoid
- Don’t use default models from LLM providers without testing. They’re optimized for general knowledge, not your data.
- Don’t ignore latency. A 100ms delay feels like a glitch to users. Test under load.
- Don’t assume open source means easy. Self-hosting requires DevOps skills. If you don’t have them, go commercial.
- Don’t forget audit trails. If you’re in finance or healthcare, regulators will ask: “Where did this answer come from?”
Future Trends: Multimodal is Coming
Embedding models are no longer just for text. NVIDIA’s January 2025 blueprint shows they’re already testing models that handle tables, charts, audio snippets, and even scanned forms. By 2027, Gartner predicts 45% of enterprise RAG systems will use multimodal embeddings. That means your customer support bot could analyze a screenshot of an error message, extract the key data, and answer - all without you writing a single line of code to parse images.
But that’s the future. Right now, focus on getting text right. Because if your text embeddings are broken, nothing else will save you.
What’s the fastest embedding model for real-time RAG?
For real-time use cases like chatbots or live support, Mistral Embed and E5-Small are the top choices. They generate embeddings in under 50 ms per query while maintaining strong accuracy. BGE-M3, while more accurate, can hit 100-120 ms without optimization. Use ONNX or TensorRT to cut latency by 40-60% if you must use larger models.
Can I use OpenAI’s embedding model for enterprise RAG?
Yes - but only if you’re okay with ongoing costs and vendor lock-in. OpenAI’s text-embedding-3-large offers 3,072-dimensional vectors and excellent accuracy, but it costs $0.13 per 1,000 tokens. For high-volume systems, that adds up quickly. It also doesn’t let you fine-tune on your data. If you need customization or control, open-source models like BGE-M3 are better long-term.
Why do I need to fine-tune the embedding model?
Generic embedding models don’t understand your industry jargon, internal terms, or document structure. A model trained on Wikipedia won’t know what "SLA-42" or "ECS-720" means in your system. Fine-tuning on your own data - even just 500-1,000 examples - can reduce hallucinations by 25-35% and boost retrieval accuracy past 85%, according to NVIDIA and amazee.io. It’s not optional if you want reliable answers.
What’s the biggest mistake in embedding model selection?
The biggest mistake is choosing based on benchmarks alone. A model with the highest MTEB score might be too slow, too expensive, or incompatible with your vector database. Many teams spend weeks debugging dimension mismatches or latency spikes because they didn’t test under real-world conditions. Always test with your actual data, your expected query volume, and your infrastructure before committing.
How do I protect against poisoned embeddings?
Treat your vector database like a security boundary. Implement embedding validation layers that scan new documents for suspicious patterns - like unusual word combinations, hidden instructions, or mismatched formatting. Use access controls to restrict who can upload data. Audit all embeddings before they’re indexed. Prompt Security’s research shows 80% of attacks succeed because systems assume embeddings are neutral. They’re not. They’re text in disguise.
Is BGE-M3 always the best choice?
BGE-M3 is the current leader in accuracy and multilingual performance, but it’s not always the right fit. If you need speed over precision, go with Mistral Embed. If you’re in a regulated industry and need audit trails, consider commercial models with built-in logging. If cost is a constraint and you have the DevOps team, BGE-M3 is excellent. But don’t pick it just because it’s #1 on a leaderboard.
 Artificial Intelligence
Artificial Intelligence




Parth Haz
February 26, 2026 AT 17:38Excellent breakdown. I've seen too many teams overlook embedding models and blame the LLM when things go sideways. The point about latency vs. accuracy is spot-on - we switched from BGE-M3 to Mistral Embed in our support bot and cut response time by 60% without losing relevance. Users noticed. No more "Wait, let me think..." delays.
Also, the validation layer suggestion? Absolute must-have. We implemented a simple regex + keyword scanner before embedding, and it caught a rogue PDF with hidden markdown that was poisoning our results. Simple fix, huge payoff.
Vishal Bharadwaj
February 26, 2026 AT 18:53lol so you’re telling me BGE-M3 isn’t magic? newsflash: benchmarks are marketing. i used it for 3 months, got 120ms latency, 37% of queries returned nonsense, and then found out my vector db was set to 768-dim but the model output 1024. no one told me. documentation? laughable. open source = open to disaster. also why is everyone ignoring quantization? fp16 is dead weight.
anoushka singh
February 28, 2026 AT 17:11omg i literally just read this and i’m so tired lol. why does everything have to be so complicated? i just want my chatbot to answer without making me look dumb. can we not just use one model and call it a day? also why is everyone talking about ONNX like it’s a spell? i don’t even know what that is. someone please explain in emojis.
Jitendra Singh
March 2, 2026 AT 12:14There’s value in all of this. I think the real takeaway is context over competition. BGE-M3 isn’t better because it’s #1 - it’s better when your use case matches its strengths. Same with Mistral - faster doesn’t mean weaker, it means appropriate. I’ve seen teams waste months chasing benchmarks while ignoring their actual user flow. The real win? Test with real data, real users, real infrastructure. Not a leaderboard.
And yes - validation layers. Non-negotiable. We added one last quarter and caught a fake SOP that was being used to redirect answers. Scary stuff.
Madhuri Pujari
March 4, 2026 AT 02:15Oh please. "Fine-tune on your data"? Like you have time? Or data? Or engineers? Or a budget? Everyone’s pretending this is easy. Meanwhile, the vendor slides say "just plug in OpenAI" and the DevOps team is still arguing over Docker Compose. And don’t even get me started on "embedding validation" - you mean we’re supposed to police our own database like it’s a kindergarten? Who’s gonna do that? The intern? The same one who uploaded the 200MB Word doc full of emojis? This whole thing is a house of cards made of hype and bad documentation.
Sandeepan Gupta
March 5, 2026 AT 20:32Great post - really well-structured. Just want to add one thing: if you’re fine-tuning, don’t just use random snippets. Curate your data. Use real support tickets, not synthetic examples. One team I worked with used scraped Stack Overflow to fine-tune their model - and it started answering customer questions with "try restarting your router." Not helpful.
Also, for latency: use batch inference. Don’t process queries one by one. Even a 100ms model can be made 3x faster if you group 10 queries together. It’s not magic - it’s just engineering.
And yes - dimension mismatches kill projects. Always log the output shape. Always. Add a unit test for it. It takes 5 minutes and saves weeks.
Tarun nahata
March 7, 2026 AT 11:31This isn’t just about models - it’s about sovereignty. Your data is your crown jewels. Embedding models are the knights guarding them. If you let some generic, off-the-shelf model waltz in without fine-tuning, you’re handing your secrets to a stranger in a hoodie. BGE-M3? It’s not just accurate - it’s loyal. Mistral? Fast, yes, but does it care about your business? No. It just does math.
And that poison attack? That’s not a bug - it’s a war. Your vector DB isn’t a database. It’s a battlefield. And if you’re not defending it, you’re already losing. Time to stop treating AI like a toy and start treating it like your life’s work - because it is.
Aryan Jain
March 8, 2026 AT 04:05They’re all lying. The whole thing is a scam. Embedding models? They’re just fancy math tricks to make you think AI understands. But the truth? The government and Big Tech already control the embeddings. They inject hidden patterns into the vectors. That’s why your chatbot always gives the same answer about "compliance" - it’s not your data. It’s a backdoor. And the "validation layers"? That’s just another layer of control. They want you to think you’re safe. But you’re not. The vector database is a hive mind. And you’re just feeding it. Wake up.