
Tag: retrieval-augmented generation

Choosing the right embedding model for your enterprise RAG pipeline isn't about benchmarks - it's about speed, security, and domain-specific accuracy. Learn what actually works in production and how to avoid costly mistakes.
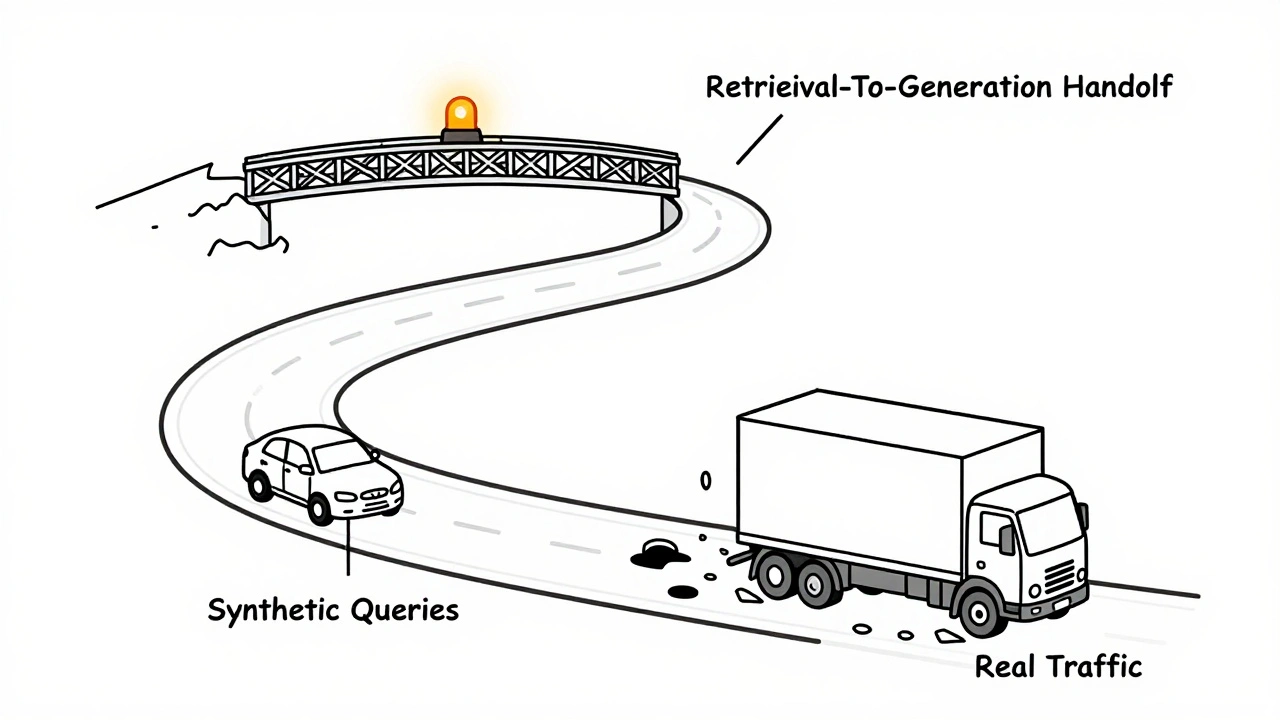
Testing RAG pipelines requires both synthetic queries and real traffic monitoring. Learn how to measure retrieval, generation, cost, and latency-and turn production failures into better tests.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Lower-Cost Tokens in Generative AI: Economics That Unlock New Use Cases
May, 20 2026

Community and Ethics for Generative AI: How Transparency and Stakeholder Engagement Shape Responsible Use
Mar, 22 2026
Multi-Tenancy in Vibe-Coded SaaS: Isolation, Auth, and Cost Controls
Feb, 16 2026

Human Oversight in Generative AI: Review Workflows and Escalation Policies That Actually Work
Mar, 24 2026

Secure Branch Protection for Vibe-Coded Repositories: A 2026 Guide
May, 14 2026