

Imagine having the reasoning power of a massive AI right in your pocket, without needing an internet connection or worrying about your data leaving the device. For a long time, that sounded like science fiction. Models like GPT-4 or Llama v3-70B are behemoths; they have tens or hundreds of billions of parameters. Trying to cram those into a smartphone or an IoT sensor is like trying to fit a skyscraper into a shoebox. Even "small" models like Llama v3-8B or Phi-3 often demand more memory than most edge hardware can provide.
The solution isn't to build smaller, dumber models, but to make the big ones leaner. This is where LLM quantization and compression come in. By stripping away unnecessary precision and optimizing how the model stores data, we can run sophisticated AI locally. This doesn't just save space; it slashes latency and keeps your private data off the cloud entirely.
What Exactly is Quantization?
Quantization is essentially a rounding exercise for AI. Most LLMs are trained using high-precision floating-point numbers (like FP16 or FP32), which take up a lot of room. Quantization converts these numbers into lower-bit integers. Think of it as changing a detailed decimal like 3.14159 into a simple 3. It's a trade-off: you lose a tiny bit of accuracy, but you gain massive amounts of speed and memory efficiency.
According to research from Qualcomm AI Research, hitting a 3-bit weight precision is a "sweet spot" for many LLMs. It provides a scalable way to shrink models without making them lose their ability to reason or speak coherently. Depending on when you apply this process, you'll use one of two main paths:
- Quantization-Aware Training (QAT): Here, the model "learns" how to be quantized during the training process. Because it knows it will eventually be shrunk, it adapts its weights to maintain higher accuracy. It's the gold standard for quality, but it's computationally expensive.
- Post-Training Quantization (PTQ): This happens after the model is already trained. You take a pre-trained model and convert it to lower precision. It's much faster and requires less expertise, though you might see a bigger dip in accuracy.
Advanced Techniques for Better Accuracy
Basic rounding can sometimes break a model's logic. To fix this, developers are using more surgical techniques. One approach is using sequential mean squared error (MSE), which finds specific scales for quantization that minimize the difference between the original and the shrunk output. Then there's Knowledge Distillation, where a massive "teacher" model trains a smaller "student" model to mimic its behavior, effectively compressing the wisdom of the giant into the small.
One of the most exciting leaps is Vector Quantization (VQ). Traditional quantization looks at each parameter individually. VQ, and specifically a method called GPTVQ developed by Qualcomm, looks at groups of parameters together. By considering the joint distribution of weights rather than treating them as isolated numbers, GPTVQ can shrink a model significantly while keeping accuracy nearly identical to the original. It's a game-changer for making high-end AI feel natural on a mobile chip.
| Method | Implementation Timing | Accuracy Retainment | Resource Cost |
|---|---|---|---|
| QAT | During Training | Highest | Very High |
| PTQ | After Training | Moderate | Low |
| GPTVQ | Post-Training (Vectorized) | Very High | Moderate |
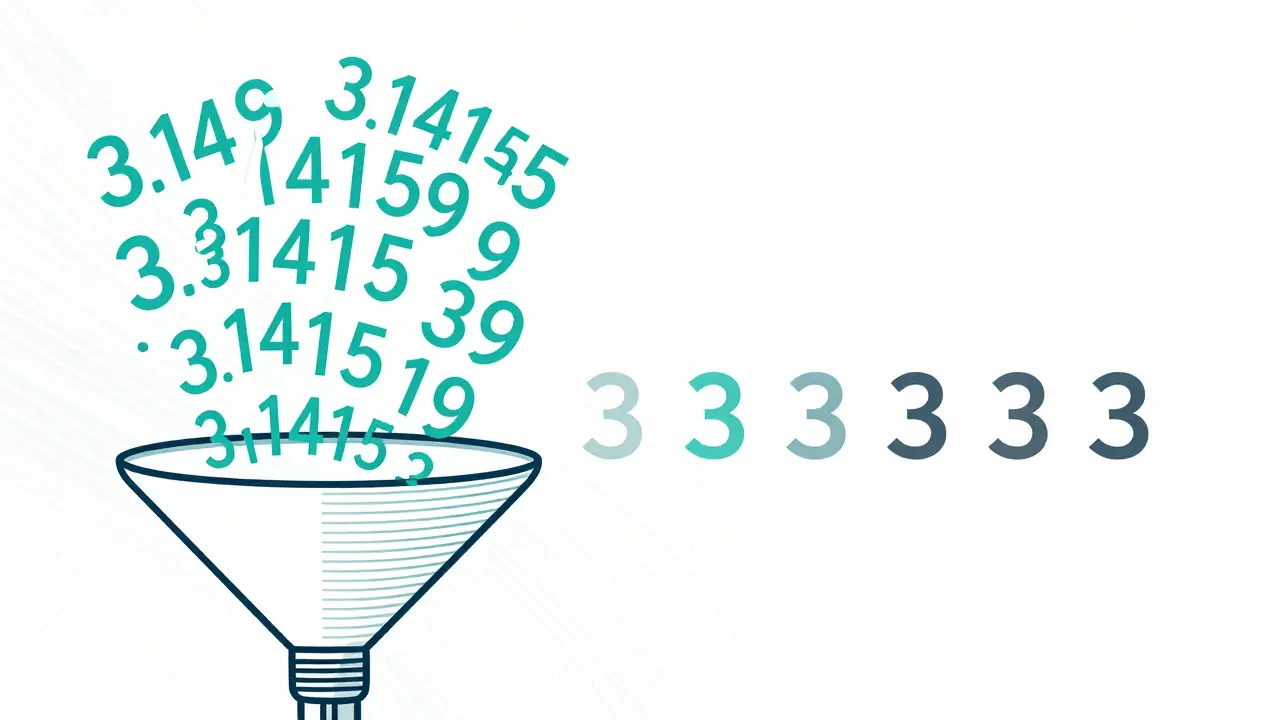
Formal Methods and Unified Frameworks
The cutting edge of compression is moving toward mathematical certainty. A recent framework called TOGGLE (Temporal Logic-Guided LLM Compression) introduces formal methods to the mix. Instead of just guessing which layers to shrink, TOGGLE uses Signal Temporal Logic (STL) to ensure the model still follows specific linguistic rules after compression. By using Bayesian optimization to test configurations across models like DeepSeek-V2 7B and Mistral 7B, TOGGLE has shown it can cut computational costs (FLOPs) by up to 3.3x and reduce model size by nearly 69% without needing a single round of retraining.
At the same time, we're seeing the rise of "all-in-one" tools. UniQL is a unified framework that blends post-training quantization with low-rank compression. What makes UniQL special is its adaptability; it can prune the model on the fly based on how much memory the device is currently using. This means if your phone is running low on RAM, the model can dynamically adjust its footprint to keep the app from crashing, balancing the "time-to-last-token" latency with overall accuracy.
Tools for Developers
You don't have to write these algorithms from scratch. The AI Model Efficiency Toolkit (AIMET), open-sourced by the Qualcomm Innovation Center, provides a set of tools specifically for quantization and compression. For those who want a more visual approach, the Qualcomm AI Hub allows developers to pick from over 100 pre-optimized models. In some cases, these optimizations lead to inference speeds up to 4 times faster than standard implementations.
One pro tip for those working with smaller models: don't ignore the embedding and head layers. In giant models, these are a small fraction of the total size. But in a model like Phi-3, these layers can take up a disproportionate amount of space. Focusing your compression efforts here can yield surprising results in memory savings.
Why the Edge Matters
Why go through all this trouble? Why not just use an API? Because the cloud has a "tax"-latency and privacy. When you send a prompt to a server, you're waiting for the data to travel, be processed, and travel back. On a local device, that trip is instant. More importantly, local processing means your sensitive data-your health records, your private journals, your company's secret sauce-never leaves your hardware.
Will quantization make my AI model noticeably dumber?
It can, but it depends on the method. Simple Post-Training Quantization (PTQ) might cause some degradation in complex reasoning. However, using advanced techniques like GPTVQ or Quantization-Aware Training (QAT) can keep the model's performance very close to the original floating-point version while drastically reducing its size.
What is the difference between pruning and quantization?
Quantization reduces the precision of the numbers (e.g., changing a 16-bit float to a 4-bit integer). Pruning, on the other hand, removes unnecessary connections or "weights" from the model entirely-essentially cutting out the parts of the neural network that don't contribute much to the final output.
Can I run a 70B parameter model on a phone?
Generally, no. Even with aggressive 3-bit quantization, a 70B model requires more RAM than most current smartphones possess. However, 7B to 13B models are now very viable on high-end edge devices thanks to frameworks like UniQL and tools like AIMET.
What is the benefit of using Signal Temporal Logic (STL) in compression?
STL allows developers to formally specify linguistic properties that the model must maintain. This means instead of just checking a general accuracy score, you can mathematically prove that the model still adheres to specific rules of language or logic after it has been compressed.
Is GPTVQ better than traditional quantization?
Yes, in many scenarios. Because GPTVQ uses vector quantization to handle groups of parameters together, it captures the relationships between weights more effectively. This allows it to achieve a much smaller model size without the steep drop in accuracy often seen in per-parameter quantization.
 Artificial Intelligence
Artificial Intelligence


Ben De Keersmaecker
April 30, 2026 AT 03:10The shift toward local inference is huge for privacy. Most people don't realize how much data leaks when using standard APIs, so having 7B models actually work on a handheld device is a game changer for security.
Tom Mikota
May 2, 2026 AT 02:57Oh sure, because nothing says "high performance" like rounding a decimal to the nearest whole number and hoping for the best... revolutionary!!!
Nick Rios
May 3, 2026 AT 00:55It is interesting to see the balance between accuracy and efficiency. While some might find the loss of precision concerning, the privacy gains are probably worth the trade-off for most average users.
Aaron Elliott
May 3, 2026 AT 10:21The preoccupation with mere "efficiency" betrays a fundamental misunderstanding of the ontological nature of intelligence. One must ponder whether a quantized model is truly "reasoning" or simply simulating a shadow of the original's cognitive architecture through a series of crude approximations. To reduce the complexity of a high-dimensional manifold to 3-bit integers is not optimization; it is an act of intellectual reductionism that ignores the emergent properties of large-scale neural networks. We are essentially sacrificing the soul of the machine for the convenience of a pocket-sized gadget, which is a profoundly banal exchange in the grander scheme of artificial evolution.
Amanda Harkins
May 4, 2026 AT 00:54basically we're just making the AI a bit dumber so it fits in our pockets. feels like a weird metaphor for how we treat knowledge in general these days.
Adrienne Temple
May 5, 2026 AT 12:14This is so cool! 🌟 I love how the GPTVQ thing works by looking at groups of numbers. It makes the whole concept feel a bit more friendly and less scary for people who aren't math experts! 😊
Sandy Dog
May 5, 2026 AT 14:29Omg can you even imagine the absolute chaos if these things just started crashing because the RAM ran out mid-sentence?? 😱 Like, I'm just trying to get a recipe for sourdough and my phone decides it's too tired to think because of some quantization error, it would literally be the end of the world as I know it!! 😭 I need a device that just WORKS without all this fancy terminology and a million different frameworks competing for my battery life, seriously!! ✨
Chris Heffron
May 5, 2026 AT 22:39The bit about embedding layers was actually quite useful. :)
Jeanie Watson
May 6, 2026 AT 23:35Too many tools. Just give me one that works.