The era of bragging rights for having the biggest model is over. In 2026, the conversation around Large Language Models is artificial intelligence systems trained on vast amounts of text data to understand and generate human language with high accuracy and context awareness has shifted from raw scale to practical utility. We are no longer just watching demos; we are integrating these models into the core infrastructure of businesses, governments, and platforms. The question is no longer "Can it write a poem?" but rather "Can it reliably execute a complex workflow without hallucinating facts or leaking private data?" This shift marks a fundamental transformation in natural language processing (NLP), driven by stricter regulations, enterprise pressure for efficiency, and the maturation of autonomous agents.
Moving Beyond Text: Multimodal Intelligence
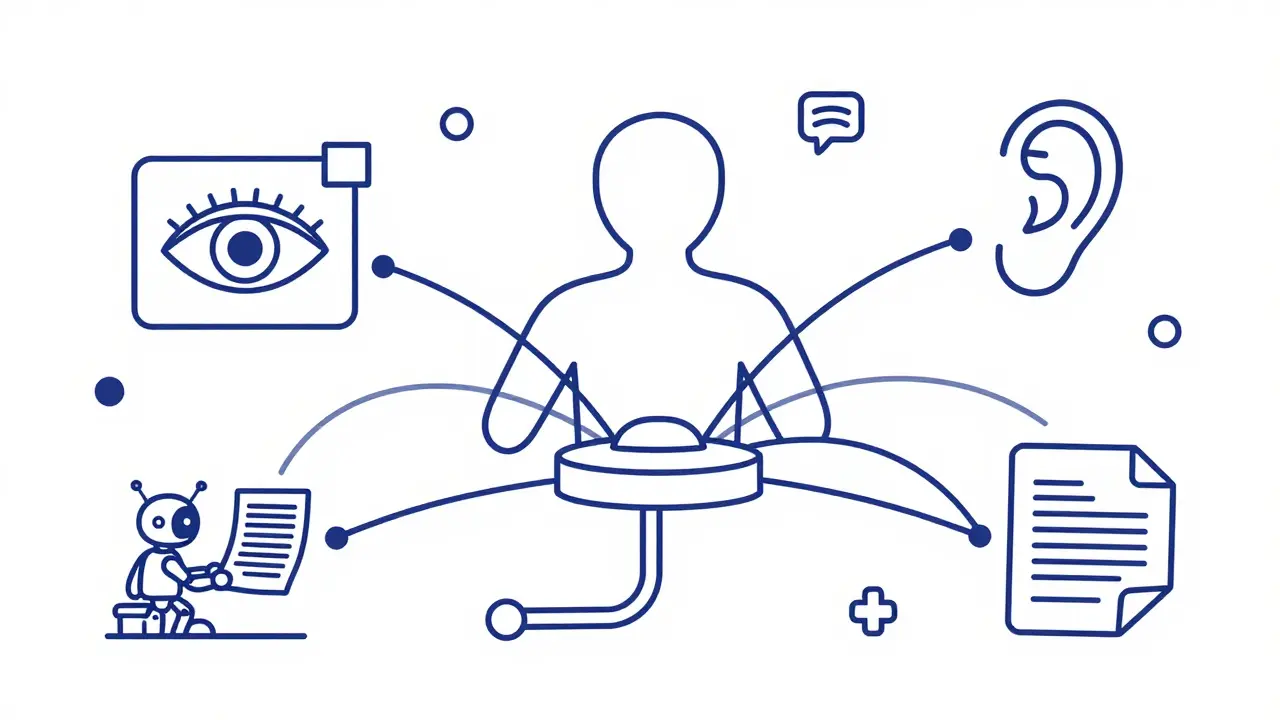
Text-only processing is becoming an artificial constraint. The defining architectural pivot for 2026 is the rise of Large Multimodal Models that integrate text, images, audio, video, and sensor data into a single unified processing framework for comprehensive analysis. These models don't just read documents; they analyze recorded lectures, extract critical slide content, and generate study guides autonomously. Imagine a system that can watch a two-hour technical webinar, listen to the speaker's tone, read the slides, and answer specific questions about the code snippets shown-all in one go. This capability responds to the explosive proliferation of visual and audio content across digital ecosystems. If your model can't handle video or audio natively, it is missing out on a massive chunk of available information.
The Rise of Agentic AI
We are moving past conversational interfaces toward functional automation. Agentic AI is autonomous artificial intelligence systems that leverage large language models to plan, decide, and execute complex tasks within defined operational boundaries has emerged as the paramount trend for deployment strategies in 2026. These systems don't wait for you to type the next prompt. They undertake autonomous task execution, planning, and decision-making. For example, an agentic system might not just summarize a sales report; it could identify a drop in revenue, cross-reference customer support tickets, draft a retention email campaign, and schedule meetings with key accounts-all while keeping you in the loop. This shift has profound implications for customer service, software development, and operational management, turning LLMs from tools into coworkers.
Efficiency Through Mixture-of-Experts
Computing power is expensive, and activating every parameter in a dense model for every query is wasteful. Enter Mixture-of-Experts Architecture, which routes queries through specialized sub-networks rather than activating all model parameters uniformly, optimizing cost-performance trade-offs. Instead of using the entire brain for every thought, MoE systems route queries through specialized "expert" networks. Mistral Large 2 is a prime example, delivering efficient inference at competitive operational costs compared to dense transformer alternatives. This innovation addresses the persistent challenge of balancing computational requirements against performance in resource-constrained environments. It allows organizations to run powerful models without burning through their cloud budgets unnecessarily.
Context Windows and Chain-of-Thought Reasoning
Memory matters. Context window expansion is reshaping what LLMs can do. While earlier models struggled with long documents, next-generation architectures promise context windows extending to 200,000 tokens or beyond. This enables comprehensive analysis of entire knowledge bases or code repositories within a single inference pass. But capacity alone isn't enough. Chain-of-Thought Reasoning is a technique where models decompose complex problems into intermediate reasoning steps before generating a final answer, improving accuracy in logical tasks represents a fundamental departure from single-step inference. By breaking down complex problems into intermediate steps, models improve performance on mathematical problem-solving and logical inference. OpenAI has highlighted this as a core component of GPT-5's design, aiming to reduce factual mistakes and improve alignment with human intent. Transparent, step-by-step reasoning makes the model's logic interpretable, which is crucial for high-stakes applications like legal or medical analysis.
Grounding Truth with RAG and Fine-Tuning
Hallucinations remain the Achilles' heel of generative AI. To combat this, organizations are increasingly relying on Retrieval-Augmented Generation, a system that combines large language models with external knowledge bases to ground outputs in verifiable, real-time information sources. RAG systems allow LLMs to access external databases and web resources, ensuring answers are based on facts, not training data guesses. MIT researchers emphasize RAG's critical importance for reducing factual inaccuracies. Complementing this, parameter-efficient fine-tuning techniques like LoRA and QLoRA enable domain specialization with minimal computational overhead. You don't need to retrain a whole model to make it understand your company's jargon; you can fine-tune it efficiently. This democratizes model customization, allowing smaller teams to build specialized tools without massive infrastructure budgets.
Open-Weight vs. Closed-Weight Ecosystems
The distinction between open-weight and closed-weight models has crystallized as a defining structural fault line. While commercial APIs are dominated by closed models from giants like OpenAI and Google, open-weight alternatives now substantially outnumber them in quantity. Crucially, the performance gap has narrowed significantly-from about a year in 2024 to roughly six months in 2025. Current trajectories suggest open-weight models will soon match or surpass closed alternatives, especially for sovereign deployments where data control is paramount. Companies concerned about privacy and regulatory compliance are increasingly looking to open-weight options that can be hosted on-premise, ensuring proprietary data never leaves their internal infrastructure.
Edge Deployment and Domain Specialization
Cloud dependency introduces latency and privacy risks. Edge deployment models address this by running LLM capabilities on-device, eliminating data transmission to external servers and reducing inference latency to sub-second ranges. This is vital for industries with strict data sovereignty laws. Simultaneously, domain-specific model specialization has accelerated. Generalist architectures often underperform on specialized tasks. Healthcare, legal, and financial domains now employ customized model variants trained specifically for their terminology and regulatory requirements. This reflects the maturation of the field: we are moving away from one-size-fits-all solutions toward targeted, optimized tools.
| Trend | Primary Benefit | Key Challenge | Example Implementation |
|---|---|---|---|
| Multimodal Integration | Comprehensive data analysis | High computational cost | GPT-5 native video/audio processing |
| Agentic AI | Autonomous workflow execution | Risk of unintended actions | Autonomous customer service bots |
| Mixture-of-Experts | Cost-effective inference | Complex routing logic | Mistral Large 2 |
| Retrieval-Augmented Generation | Reduced hallucinations | Latency from retrieval steps | Enterprise knowledge base assistants |
| Edge Deployment | Data privacy and low latency | Limited hardware resources | On-device mobile AI assistants |
The Path Forward: Self-Optimization and Bias Mitigation
Natural language processing in 2026 is trending toward increased autonomy in model behavior. Systems are becoming capable of self-optimization and continuous learning from user feedback without manual intervention. Static models rapidly become suboptimal as domains evolve. Additionally, bias mitigation remains a critical research domain. Practitioners are exploring how internal neuron activations reveal embedded biases and developing pruning techniques to create more resilient, fair models. As we integrate these systems deeper into society, ensuring they are not just smart, but also safe and unbiased, becomes the ultimate test of our engineering maturity.
What is the biggest change in LLMs for 2026?
The biggest change is the shift from experimental deployments to core digital infrastructure integration. Models are now focused on practical utility, domain-specific optimization, and autonomous task execution (Agentic AI) rather than just raw scale or creative generation.
How does Mixture-of-Experts (MoE) improve efficiency?
MoE improves efficiency by routing queries through specialized sub-networks instead of activating all parameters in the model. This reduces computational costs and speeds up inference while maintaining high performance.
Why is Retrieval-Augmented Generation (RAG) important?
RAG is crucial for reducing hallucinations. It grounds the model's outputs in verifiable, real-time information from external knowledge bases, ensuring accuracy and reliability for enterprise applications.
What is the difference between open-weight and closed-weight models?
Closed-weight models are proprietary and accessed via API, while open-weight models have publicly available parameters. In 2026, the performance gap between them has narrowed significantly, making open-weight models attractive for privacy-focused, on-premise deployments.
How do context windows affect LLM performance?
Larger context windows, such as the 200,000 tokens promised by next-gen models, allow LLMs to process entire documents or codebases in a single pass. This enables better comprehension of long-range dependencies and more accurate synthesis of complex information.
What role does Chain-of-Thought reasoning play?
Chain-of-Thought reasoning helps models break down complex problems into intermediate steps. This improves accuracy in logical and mathematical tasks and makes the model's decision-making process more transparent and interpretable.
Is Agentic AI safe for enterprise use?
Agentic AI offers significant automation benefits but requires careful implementation. Enterprises must define clear operational boundaries and safety protocols to prevent unintended actions, ensuring agents operate within acceptable risk limits.
How does edge deployment benefit users?
Edge deployment runs models on local devices, offering lower latency, enhanced privacy, and compliance with data sovereignty laws by keeping sensitive data off external cloud servers.
 Artificial Intelligence
Artificial Intelligence