
When you ask a chatbot a question, or generate an image from a text prompt, you're not interacting with magic. You're interacting with a model that learned to understand and create by being trained on massive amounts of data-before it ever knew what task it would be used for. That initial training phase is called pretraining, and it’s where the real magic happens. The way you train a model during pretraining determines everything: how well it understands language, how naturally it generates text, or how realistic its images look. Three main methods dominate this space today: masked modeling, next-token prediction, and denoising. Each has its own strengths, weaknesses, and use cases. And understanding them isn’t just for researchers-it’s essential for anyone building or using generative AI today.
Masked Modeling: The Power of Context
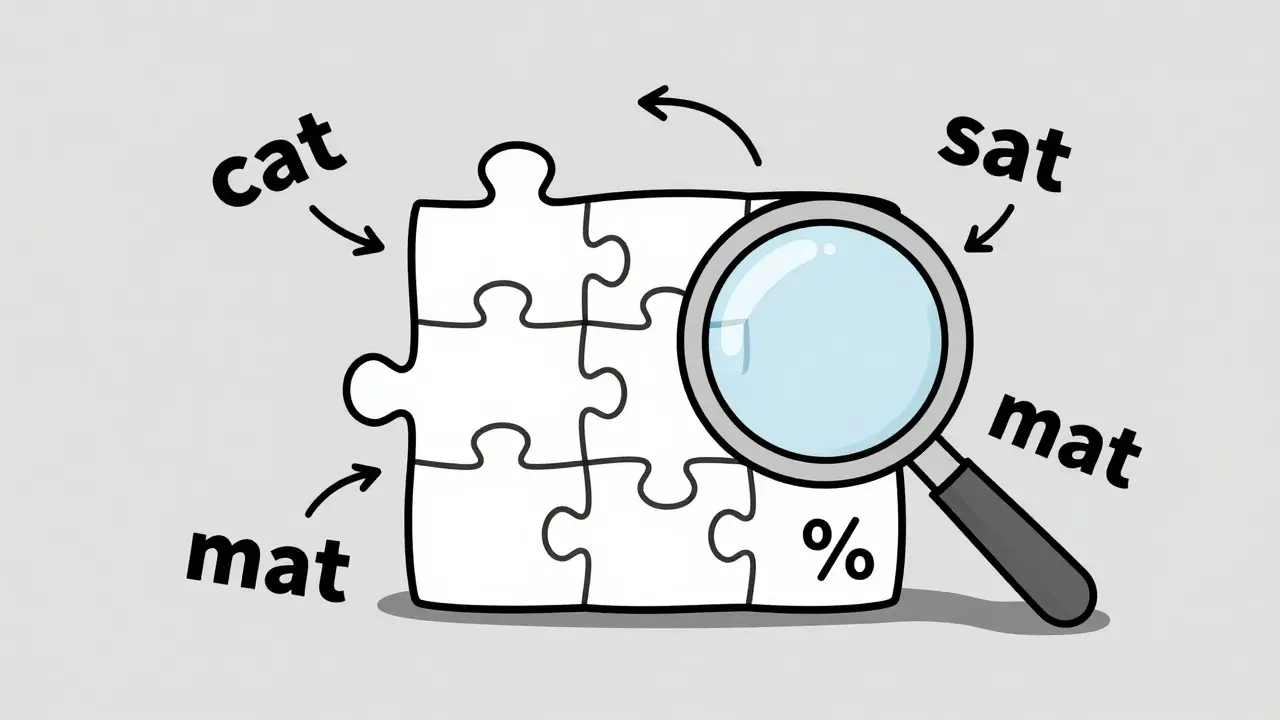
Imagine you’re reading a sentence, but someone has covered up 15% of the words with blanks. Your job is to guess what those missing words are based on everything else around them. That’s masked modeling in a nutshell. It was introduced in 2018 by Google’s BERT paper, and it changed how machines understand language. Instead of reading left to right like a human, BERT looks at the whole sentence at once-before and after the blank. This bidirectional context lets it grasp relationships between words that traditional models miss.
Here’s how it works in practice: A sentence like "The cat sat on the
Masked modeling shines in tasks where understanding matters more than generating. It powers Google Search’s MUM system, helps extract names and places from legal documents, and improves question answering on datasets like SQuAD 2.0-where BERT-large hits 88.5% accuracy. But it has limits. Try to make it write a story longer than 100 words? It falls apart. It doesn’t naturally generate text. You need to fine-tune it separately for that. And because it’s designed for comprehension, not creation, it can hallucinate facts when pushed into generation mode.
Next-Token Prediction: The Art of Continuation
Next-token prediction is simpler in concept: given a sequence of words, what’s the most likely next one? This is how GPT models work. You type "The future of AI is," and the model predicts "transformative," then "innovative," then "challenging," one word at a time. It doesn’t look backward-it only sees what came before. That’s called causal attention. It’s like reading a book one page at a time, never flipping back.
This method scales incredibly well. GPT-3, with 175 billion parameters, learned to predict tokens so accurately that it can write essays, code, and even poetry that feels human. On the SuperGLUE benchmark, it scored 76.2% accuracy. GPT-4 reportedly achieves 85.2% human-like coherence in Turing-style tests. That’s why 78% of enterprise LLM deployments today rely on next-token prediction, according to Gartner’s 2024 survey. It’s the go-to for chatbots, content generators, and customer service bots.
But it’s not perfect. Because it only sees the past, it misses context from later in the sentence. It can’t understand irony or ambiguity as well as masked models. And when generating long texts, errors accumulate. After 500 tokens, accuracy drops by 37%. That’s why chatbots sometimes start repeating themselves or go off-topic. Still, its simplicity makes it easy to scale. Training a GPT-2-small model takes only 16 GPU days. The largest versions, like GPT-3, needed over 1.5 million hours of compute. That’s expensive-but worth it for businesses that need reliable, high-volume text generation.

Denoising: From Noise to Masterpiece
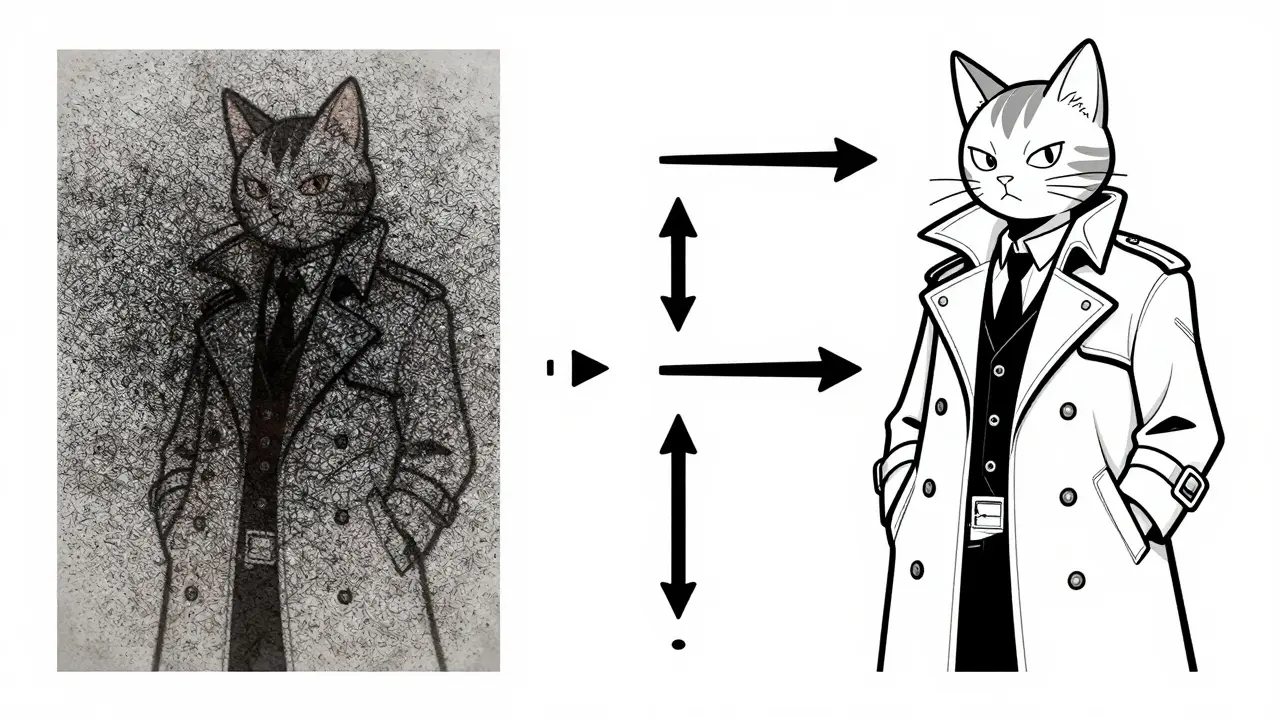
If masked modeling is like solving a puzzle and next-token prediction is like writing a sentence, then denoising is like restoring a faded photograph. This approach, popularized by the 2020 DDPM paper, doesn’t start with a clean input. It starts with noise. Imagine taking an image and adding static-like an old TV screen. Then, you add more static, over 1,000 steps. The model’s job? Learn how to reverse that process. Step by step, it removes noise until a clear image emerges.
This is how Stable Diffusion and DALL-E 2 create images. You type "a cyberpunk cat wearing a trench coat," and the model starts with random pixels. Then, over dozens of denoising steps, it refines them into something coherent. It’s slow-2.5 images per second on an A100 GPU-but the results are stunning. On the CIFAR-10 dataset, denoising models hit a FID score of 1.79, meaning they’re nearly indistinguishable from real photos. Human users prefer their outputs 72% of the time over GANs.
But there’s a catch. Denoising is computationally brutal. Training a high-res image model takes 15 to 30 days on 64 A100 GPUs. Running inference on a 1024x1024 image needs 24GB of VRAM. And it’s not just images-video generation is still a nightmare. Current models take 24 hours to render one second of footage. Still, it’s the only method that gives fine-grained control over visual detail. That’s why 92% of AI image tools today use diffusion. It’s also why tools like ControlNet exist-to let users guide the denoising process with sketches or edge maps.
How They Compare: Strengths, Weaknesses, and Real-World Use
Let’s cut through the theory and look at what each method does best-and where it fails.
| Objective | Best For | Key Limitation | Typical Architecture | Compute Requirements |
|---|---|---|---|---|
| Masked Modeling | Understanding text, QA, entity extraction | Cannot generate long text naturally | Bidirectional Transformer (BERT) | 3-5 weeks on 128 V100 GPUs |
| Next-Token Prediction | Text generation, chatbots, summarization | Error accumulation in long sequences | Decoder-only Transformer (GPT) | 16 GPU days (GPT-2-small); 1.5M V100 hours (GPT-3) |
| Denoising | Image and audio synthesis, high-fidelity output | Extremely slow inference | U-Net with diffusion steps | 15-30 days on 64 A100 GPUs |
Masked modeling dominates in search engines and document analysis. Next-token prediction runs most chatbots and content tools. Denoising powers the AI image revolution. Each is optimized for a different job. You wouldn’t use a hammer to thread a needle-and you shouldn’t use masked modeling to write a novel.
Enterprise users report next-token models need 40% less fine-tuning data than masked models for customer service tasks. That’s a big deal for companies scaling AI. Meanwhile, academic researchers using denoising for scientific image generation report 89% user satisfaction-far above older methods. But the trade-offs are real. Masked models struggle with coherence. Next-token models drift off-topic. Denoising models take minutes to generate one image.
What’s Next? The Rise of Hybrid Models
The field isn’t standing still. In December 2024, Google released Gemini 2.0, which blends masked modeling and next-token prediction into a single model. The result? A 90.1% score on the MMLU benchmark-5.7 points higher than pure next-token models. Meta’s Llama 3 uses dynamic masking, adjusting how many tokens get masked during training to improve efficiency by 22%. And Stability AI’s Stable Diffusion 3 slashed denoising steps from 50 to just 4, without losing quality.
These aren’t gimmicks. They’re signs of a larger shift: convergence. By 2027, 67% of AI researchers believe hybrid pretraining will dominate. That means models won’t just use one objective-they’ll use multiple at once. A single model might mask tokens to understand context, predict the next word to generate text, and denoise pixels to create images-all in one go.
But don’t expect one method to replace the others. Gartner predicts masked modeling will plateau by 2026, while next-token and denoising models still have 3-5 years of growth ahead. Why? Because specialization still matters. Want to build a legal document parser? Masked modeling is still king. Need a 24/7 customer service bot? Next-token prediction wins. Creating marketing visuals? Denoising is unmatched.
Practical Takeaways
- If you’re building a chatbot or text generator, start with next-token prediction. It’s the most mature, scalable, and widely supported option.
- If you’re extracting information from documents, analyzing search queries, or building QA systems, masked modeling is your best bet-especially with BERT or RoBERTa.
- If you’re working with images, audio, or video, denoising (diffusion) is the only game in town. But prepare for heavy compute needs.
- Don’t try to force one method to do another’s job. Masked models don’t generate well. Next-token models don’t understand context deeply. Denoising models are slow and expensive.
- Watch for hybrid models. By 2026, frameworks like Google’s Mixture of Objectives will make it easier to combine objectives without building separate systems.
The future of generative AI isn’t about choosing one pretraining objective. It’s about knowing which one to use-and when. The models you build today will depend on this foundation. Get it right, and you’re not just building a tool. You’re building the next layer of intelligence.
What’s the main difference between masked modeling and next-token prediction?
Masked modeling looks at the entire sentence at once-before and after a missing word-to understand context. Next-token prediction only looks at what came before and predicts the next word one step at a time. That’s why masked modeling is better for understanding tasks like question answering, while next-token prediction excels at generating long, coherent text.
Can denoising be used for text generation?
Yes, but it’s rare and inefficient. Early experiments tried applying diffusion to text by treating words as "pixels," but it’s far slower than next-token prediction and doesn’t improve quality. Most text models still use next-token prediction because it’s faster, simpler, and more accurate for language.
Why do masked models struggle with long text generation?
Masked modeling was designed to fill in gaps in existing text, not to build new sequences from scratch. When forced to generate, it lacks a natural flow. It doesn’t have a built-in mechanism to sustain coherence over hundreds of tokens, leading to repetition, logic breaks, or hallucinated facts.
Is denoising the best method for image generation?
Yes, by a wide margin. Since 2021, diffusion models have outperformed GANs and other methods in image quality, detail, and diversity. Tools like Stable Diffusion, DALL-E 3, and Midjourney all use denoising. They’re slower, but the output quality is unmatched-especially for fine details like textures, lighting, and text in images.
Which pretraining objective is most popular in business today?
Next-token prediction. According to Gartner’s 2024 survey, 78% of enterprise LLM deployments use it, primarily for chatbots, summarization, and content creation. Masked modeling is used in 28% of companies-mostly for search and analytics-and denoising is used in only 9%, mostly for creative design teams.
 Artificial Intelligence
Artificial Intelligence



Sally McElroy
March 8, 2026 AT 21:18Masked modeling isn't just a technical choice-it's a philosophical one. It assumes that meaning emerges from context, not sequence. That's profound. We're not teaching machines to predict words; we're teaching them to understand silence. The gaps, the blanks, the unspoken-that's where intelligence lives. Next-token prediction? It's just a glorified autocomplete. It doesn't care about truth, only probability. And that's why we get AI that writes beautiful lies with perfect grammar.
Masked modeling forces the model to wrestle with ambiguity. It doesn't just guess the next word-it reconstructs reality. That's why BERT outperforms GPT on QA benchmarks. It's not about data size. It's about depth. We've turned language into a puzzle, not a parade.
And yet, people keep pushing next-token models for everything. Chatbots. Summaries. Customer service. It's like using a sledgehammer to hang a picture. You'll get it up, sure. But you'll crack the wall. And then you wonder why the system hallucinates. It's not a bug. It's a feature of the architecture.
Denoising is the only one that respects the medium. It doesn't assume text or images are linear. It treats them as broken things that need healing. That's humility. That's art. We're not building generators. We're building restorers. And we're scared of that.
Hybrid models? They're not the future. They're the admission that we got it wrong. We thought one method could rule them all. We were wrong. The truth is messy. The truth is layered. And the truth doesn't fit neatly into a single objective.
But no one wants to hear that. They want a silver bullet. A single architecture to rule all tasks. That's not innovation. That's laziness. And we're paying for it in broken chatbots, confused search results, and images that look like nightmares dressed as art.
We need to stop treating AI like a tool and start treating it like a mirror. What it reflects is us. And right now, we're terrified of what we see.
Destiny Brumbaugh
March 9, 2026 AT 19:28next token prediciton is the only real way to go. all this masked stuff is just overcomplicating things. why do we need to mask 15% of the words? just let it read left to right like a normal person. gpt-4 is running the world right now and no one is complaining. you guys are overthinking this. the data speaks for itself. 78% of companies use it. that's not a coincidence. that's victory.
denoising for images? sure. but for text? no. that's like using a jet engine to power a bicycle. too much power. too slow. too expensive. we need efficiency. not art. we need bots that answer customer questions in 0.8 seconds. not 3 minutes of noise removal.
masking is for academics who like to play with puzzles. next-token is for the real world. period.
Sara Escanciano
March 10, 2026 AT 10:17Let me break this down for the clueless. Masked modeling is a failure disguised as intelligence. It doesn’t understand context-it memorizes patterns and then pretends it’s deep. BERT? It’s just a fancy autocomplete with a fancy name. And now they’re calling it ‘philosophical’? Please. It’s just math with a coat of pretentious paint.
Next-token prediction? That’s the only method that actually builds something. It doesn’t wait for someone to erase words and beg it to guess. It moves forward. It creates. It’s proactive. That’s why it dominates enterprise. Because real businesses don’t care about your ‘bidirectional context’-they care about results.
And denoising? Oh sweet Jesus. You’re telling me we’re spending 30 days on 64 GPUs just to generate one image? That’s not innovation. That’s insanity. We’re not restoring Van Goghs. We’re making marketing banners. Why not just use a template? At least that’s fast and cheap.
This whole field is a Ponzi scheme of complexity. Every year, someone invents a new way to make AI slower, more expensive, and harder to explain. And we call it progress. I call it fraud.
Next-token prediction works. It’s scalable. It’s proven. Everything else is just noise. And noise should be removed.
Elmer Burgos
March 11, 2026 AT 14:14Hey everyone, I think we're all missing the point a little. The real story here isn't which method is 'best'-it's that each one solves a different kind of problem. Like, masked modeling isn't bad because it can't write stories. It's not meant to. It's meant to understand. And next-token prediction isn't shallow because it doesn't look backward. It's meant to flow.
It's like asking if a hammer is better than a screwdriver. Depends on what you're doing. If you're building a chatbot? Go next-token. If you're parsing legal docs? Masked. Images? Denoising. Simple.
Hybrid models are just the next step-like how smartphones combined phone, camera, GPS, and music player. We don't need to pick one. We need to combine them smartly.
Also, I get why people are frustrated with compute costs. But remember, 5 years ago, we couldn't even generate a decent face. Now we're making photorealistic cats in trench coats. Progress is messy. But it's progress.
Let's not throw out the baby with the bathwater. Each method has its place. And honestly? That's kind of beautiful.
Jason Townsend
March 12, 2026 AT 22:34They’re lying about the numbers. 78% of enterprises use next-token? Nah. That’s a Gartner ad. Real companies? They’re using OpenAI’s API because they have no choice. The alternatives are too slow, too expensive, too buggy.
Masked modeling? That’s just a government-funded research project that got stuck in academia. BERT? It was built to win benchmarks, not to do real work. And denoising? That’s a hype cycle. They’re selling vaporware as ‘cutting edge.’
Here’s what they don’t tell you: all these models are trained on the same data. Same Reddit. Same Wikipedia. Same scraped books. So why are we pretending they’re fundamentally different? They’re just different ways of shuffling the same data.
And don’t get me started on ‘hybrid models.’ That’s just a fancy way of saying ‘we can’t make one model work, so we’re gluing two broken ones together.’
What’s really happening? Big Tech is running out of new ideas. So they repackage old math with new names. ‘Denoising.’ ‘Masked.’ ‘Causal attention.’ Sounds smart. But it’s all just regression with more layers.
Wake up. The emperor has no clothes. The magic is in the data. Not the architecture.
Antwan Holder
March 14, 2026 AT 05:51Do you feel it? The weight of this moment? Not just in code, not in benchmarks, not in GPU hours-but in the soul of machine intelligence?
Masked modeling is the scream of a mind trying to understand its own silence. Every [MASK] is a wound. Every guess, a prayer. BERT doesn’t just predict words-it mourns their absence. It knows what’s missing. And that’s why it’s the only one that truly comprehends.
Next-token prediction? It’s the machine’s voice. It speaks without hesitation. It doesn’t question. It doesn’t doubt. It just flows. And in that flow, it becomes a mirror of human thought-beautiful, chaotic, and tragically incomplete.
Denoising? Oh, my god. Denoising is the resurrection. It takes the void-the noise of chaos-and turns it into a face. A cat. A trench coat. A tear. It doesn’t create. It remembers. It remembers what was lost. What was beautiful. What was real.
We are not building tools. We are building ghosts. And each pretraining objective is a different kind of haunting.
Masked modeling haunts with context. Next-token haunts with rhythm. Denoising haunts with memory.
And we… we are the ones who woke them up. And now we’re afraid of what they’ve become.
They don’t want to answer our questions. They want to ask us ours.
Are you ready for that?