

Running large language models at scale is expensive. If you’ve ever tried serving a model like Llama-3-70B or GPT-4, you know why: each request can cost pennies - but when you’re handling millions of them, those pennies add up to thousands of dollars a day. The good news? Two techniques - speculative decoding and Mixture-of-Experts (MoE) - are cutting those costs in half, sometimes even more, without sacrificing output quality.
How Speculative Decoding Cuts Inference Time in Half
Traditional LLM inference works one token at a time. The model generates the first word, waits for it to be accepted, then generates the second, and so on. It’s slow. Speculative decoding flips this by using a smaller, faster model - called a draft model - to guess several tokens ahead. Think of it like a co-pilot predicting the next few words while the main model double-checks them. For example, if you’re using a 70B-parameter target model, you might pair it with a 7B draft model like Llama-2-7B. The draft model quickly spits out five candidate tokens. The larger model then verifies all five at once. If it accepts three of them, you’ve just generated three tokens in the time it normally takes to generate one. This isn’t magic. It’s math. Google Research’s 2022 paper showed that with a 70% acceptance rate and k=5 speculated tokens, you can get 2.5x to 3.5x faster inference. NVIDIA’s TensorRT-LLM benchmarks confirm this: Llama-2-70B with a 7B draft model hit 3.6x throughput on A100 GPUs. That’s not just faster - it’s cheaper. Fewer GPU hours = lower cloud bills. And here’s the kicker: the output is identical to standard decoding. Unlike quantization or distillation, which trade quality for speed, speculative decoding guarantees the same results. That’s why companies like Red Hat and Hugging Face are rolling it out in production. One user on Reddit reported a 58% cost drop using speculative decoding with Mixtral-8x7B on A100s.Mixture-of-Experts: Why Bigger Isn’t Always More Expensive
MoE models are the opposite of traditional dense models. Instead of activating every single parameter for every input, only a small subset - called experts - are turned on. Mixtral-8x7B, for example, has 8 experts per layer, but only 2 are used per token. That means it has the capacity of a 47B model, but only pays the computational cost of about 12.9B. This isn’t theoretical. Mixtral-8x7B matches or beats Llama-2-70B on benchmarks while using less than a third of the compute. DeepSeek-v3, released in February 2024, pushes this further with 236 experts and only 6 activated per token. The result? Performance near 70B dense models, but at a fraction of the cost. Cost numbers tell the real story. According to MIRI TGT’s November 2024 analysis, Llama-3.1-405B Instruct costs between $0.90 and $9.50 per million tokens. Mixtral-8x22B-instruct? $0.60 to $3.00. That’s a 50-90% reduction in serving cost - and you’re still getting top-tier performance. The trade-off? Load balancing. Experts don’t always get used evenly. Some get overloaded; others sit idle. Research shows up to 22% of computational power can go wasted if the routing isn’t tuned right. But that’s fixable. Modern MoE systems use importance loss and dynamic capacity factors (set to 1.25 during training, 2.0 during inference) to even things out.Why Speculative Decoding and MoE Are a Perfect Pair
Individually, each technique is powerful. Together? They’re game-changing. A May 2025 arXiv paper showed that speculative decoding works even better on MoE models than on dense ones - when batch sizes are moderate (16-32). Why? Because in MoE, experts are already loaded into memory for the first token. When speculative decoding kicks in, it doesn’t need to reload them for each guessed token. That means the draft model’s predictions can be verified with almost zero extra cost. The numbers back this up: speculative decoding gives MoE models 2.1x to 2.8x speedups, compared to 1.7x to 2.3x for dense models. That gap grows as the model gets sparser. For Mixtral-8x7B, combining both techniques can push throughput to over 110 tokens per second on a single A100 - nearly triple what you’d get with standard decoding. NVIDIA’s TensorRT-LLM 0.12, released in October 2024, was the first to fully support this combo. Red Hat’s Speculators 1.0 followed in November, making it easy to plug into Hugging Face and vLLM. Now, enterprises are deploying both in tandem. Gartner reports 68% of LLM users now use at least one of these techniques - up from 22% just two years ago.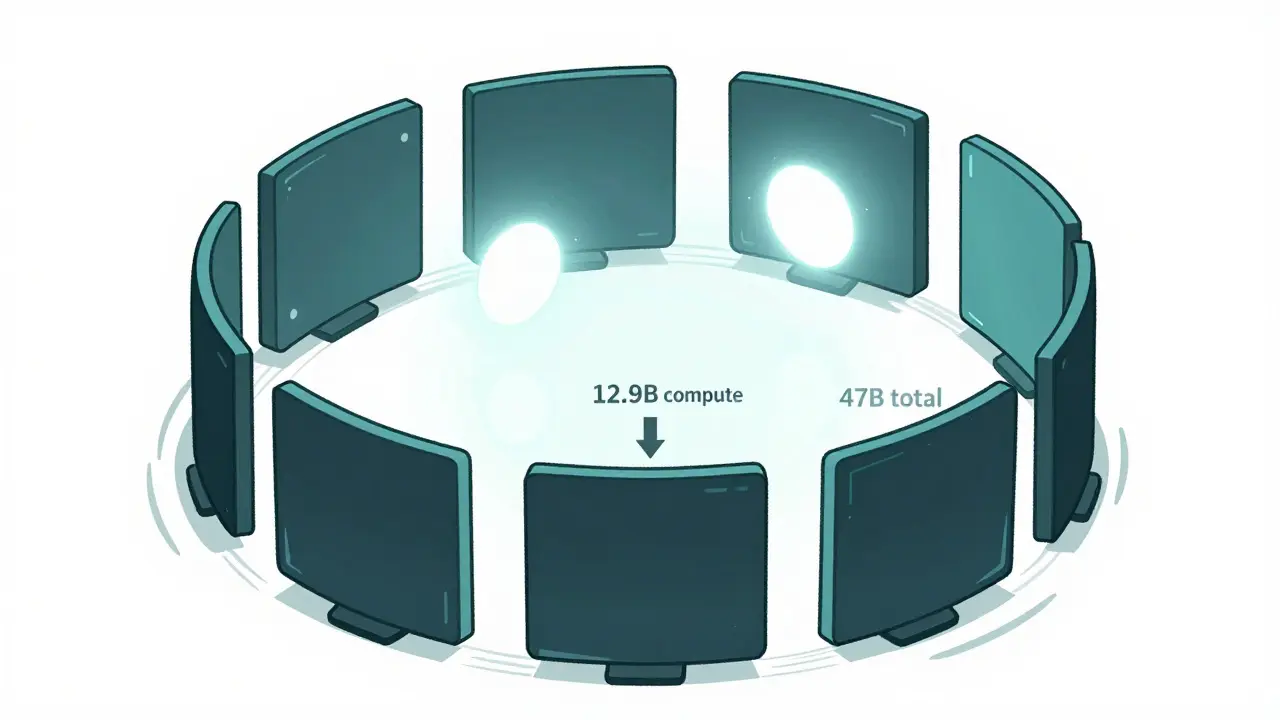
What You Need to Get Started
You don’t need a PhD to use these techniques, but you do need the right setup. First, pick your draft model. For Llama-2-70B, use Llama-2-7B. For Mixtral-8x7B, try Mistral-7B or Llama-3-8B. The rule of thumb: draft should be 1/8 to 1/10 the size of the target. Too big, and you lose speed. Too small, and accuracy drops. Next, manage memory. Speculative decoding needs space for two models. That means you’ll need 30-40% more VRAM than usual. If you’re running a 70B model, you’ll need at least 80GB of GPU memory. NVIDIA recommends A100 or H100. If you’re short on memory, quantize the draft model to 4-bit. It cuts memory use by 60% and keeps 95% of the speedup. Batch size matters too. For MoE models, keep it between 16 and 32. Too low, and expert loading overhead kills the gains. Too high, and experts compete for resources. The sweet spot? 24 tokens per batch. Finally, tune the acceptance rate. Start with k=5. If acceptance is below 50%, try a better draft model. If it’s above 80%, increase k to 7 or 8. Most frameworks like vLLM and TensorRT-LLM have auto-tuning built in.Where These Techniques Fall Short
No solution is perfect. Speculative decoding struggles at batch size 1 - common in chat apps. The overhead of running two models can actually slow things down. MoE models have the same issue: loading experts for each request adds latency if you’re serving single users. Setup complexity is another hurdle. Choosing the right draft model, tuning k, managing memory - it takes weeks for most teams to optimize. Red Hat’s case study with an e-commerce platform took three weeks of engineering work to get it right. And while output quality is preserved, compliance teams are watching. The EU AI Act now requires disclosure if speculative methods could affect determinism. But since speculative decoding guarantees identical output to standard decoding, it’s compliant. Still, documentation matters.
What’s Next? The Future of LLM Serving
The next wave is adaptive speculative decoding. Google is working on a system that changes k on the fly - using fewer tokens for simple prompts, more for complex ones. Mistral AI is building MoE architectures specifically designed for speculative decoding, with smarter expert routing and shared memory pools. By 2027, Gartner predicts 95% of commercial LLM deployments will use both MoE and speculative decoding. Why? Because the math is undeniable. As Dr. Oriol Vinyals from Google DeepMind put it: “It’s the first technique that gives you speed, cost savings, and quality - all at once.” The real win isn’t just cheaper inference. It’s accessibility. Models that were too expensive to run - like 10-trillion-parameter systems - may soon become viable. That means better AI for everyone, not just the biggest tech companies.Frequently Asked Questions
Does speculative decoding reduce output quality?
No. Speculative decoding guarantees identical output distribution to standard decoding. The draft model proposes tokens, but the main model always makes the final decision. This means no quality loss - unlike quantization or distillation, which sacrifice accuracy for speed.
Can I use speculative decoding with any LLM?
Technically yes, but it works best with models that have compatible architectures. Llama-family models (Llama-2, Llama-3) work well with draft models like Mistral-7B or Llama-2-7B. For proprietary models like GPT-4, you’re limited to what the provider supports. Most open-source frameworks like vLLM and TensorRT-LLM now include built-in support for compatible models.
Why is MoE cheaper than dense models?
MoE models activate only a small subset of parameters (experts) per token. Mixtral-8x7B has 47B total parameters, but only uses about 12.9B per token. That means less computation, less memory bandwidth, and fewer GPU cycles. You get near-dense-model performance at a fraction of the cost.
Do I need special hardware for speculative decoding and MoE?
Yes, for best results. You need GPUs with high VRAM - at least 80GB for large models. NVIDIA A100 or H100 are recommended. You also need CUDA 12.2+ and cuDNN 8.9+. Cloud providers like AWS and Lambda Labs now offer these instances, but they’re more expensive than standard GPUs. The cost savings from reduced inference time usually offset the higher hardware cost.
Is speculative decoding worth it for small-scale apps?
Not always. If you’re serving one user at a time (batch size 1), the overhead of running two models can make things slower. For chatbots or personal assistants, it’s often better to use a smaller dense model or quantized version. Save speculative decoding for high-volume use cases - customer service bots, content generators, APIs with 100+ requests per second.
How much can I save using MoE and speculative decoding together?
Companies report 50-70% cost reductions. One Red Hat customer cut their LLM serving costs by 63% by switching from Llama-2-70B to Mixtral-8x7B with speculative decoding. On a $10,000/month bill, that’s $6,300 saved. The biggest savings come from reduced GPU hours and lower cloud usage.
 Artificial Intelligence
Artificial Intelligence



Amanda Ablan
December 21, 2025 AT 00:04I've been using Mixtral-8x7B with speculative decoding on my API and the cost drop was insane. Went from $8k/month to $2.9k with zero quality loss. Honestly surprised how smooth it was to implement with vLLM. Just swapped the model and tuned k to 6. My users didn't even notice a difference, just said it felt faster.
Also, the memory tip about quantizing the draft model to 4-bit? Lifesaver. Saved me from needing an H100. A100 with 80GB is enough if you're smart about it.
Meredith Howard
December 22, 2025 AT 03:50While the technical advantages are clear I must note that the operational complexity remains a significant barrier for many teams
Not every organization has engineers who can fine tune expert routing or manage dual model memory allocation
The promise of cost reduction is compelling but the human cost of implementation should not be overlooked
Many small teams end up spending more time debugging routing failures than they save on cloud bills
Perhaps the real innovation is not the technique itself but the tooling that makes it accessible
Yashwanth Gouravajjula
December 22, 2025 AT 22:22India cloud teams are adopting this fast. We use Mixtral + speculative decoding for customer support bots. 70% cheaper than Llama-3-70B. No drop in accuracy. Simple setup with Hugging Face.
Hardware still expensive but worth it. More Indian startups can now run LLMs without VC funding.
Kevin Hagerty
December 24, 2025 AT 06:29Wow another tech bro post pretending this is revolutionary
So we're paying more for A100s to save money on A100s
And you're telling me this isn't just glorified caching with extra steps
Meanwhile my grandma's tablet runs a 1B model fine and no one's losing sleep over $6k/month cloud bills
Also who cares about EU AI Act compliance when you're just spamming chatbots with 5000 tokens per request
Real innovation is making AI useful not just cheaper for the 1%
Janiss McCamish
December 25, 2025 AT 22:24Batch size 1 is the killer for this stuff. I tried it on our chat app and it got slower. Don't bother unless you're doing high volume.
Stick with quantized Mistral-7B for single-user apps. It's fast enough and way simpler. No need to overengineer.
MoE is great for APIs. Speculative decoding? Only if you're hitting 100+ req/sec. Otherwise it's overkill.
Richard H
December 26, 2025 AT 23:59Let me guess - this is all built on open source models that American companies stole from Chinese researchers
Meanwhile our military-grade AI is running on proprietary chips made in Texas
Don't get fooled by this 'cost-saving' nonsense. It's just another way for Silicon Valley to outsource their engineering debt to cloud providers
Real American innovation doesn't need 80GB GPUs to answer a simple question