
Tag: LLM inference cost

Speculative decoding and Mixture-of-Experts (MoE) are cutting LLM serving costs by up to 70%. Learn how these techniques boost speed, reduce hardware needs, and make powerful AI models affordable at scale.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Customer Journey Personalization Using Generative AI: Real-Time Segmentation and Content
Mar, 17 2026

Vibe Coding for Full-Stack Apps: What to Expect from AI Implementations
Feb, 21 2026

Retrieval-Augmented Generation for Generative AI: Grounding Outputs in Verified Sources
Mar, 28 2026

Source Selection Policies for RAG: Balancing Relevance and Diversity
Apr, 20 2026
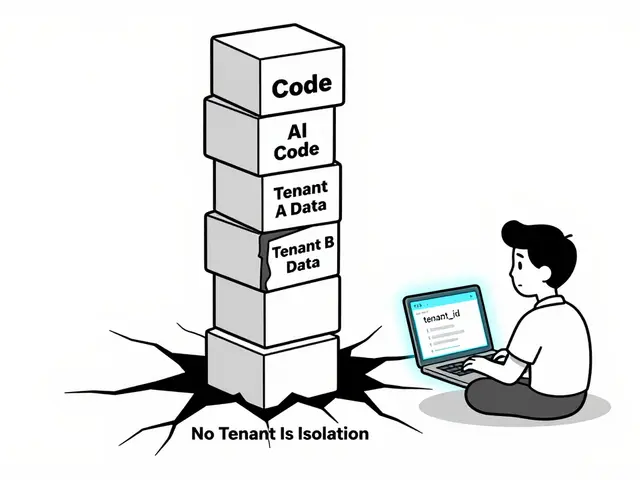
Multi-Tenancy in Vibe-Coded SaaS: Isolation, Auth, and Cost Controls
Feb, 16 2026