
Tag: CUDA for LLMs
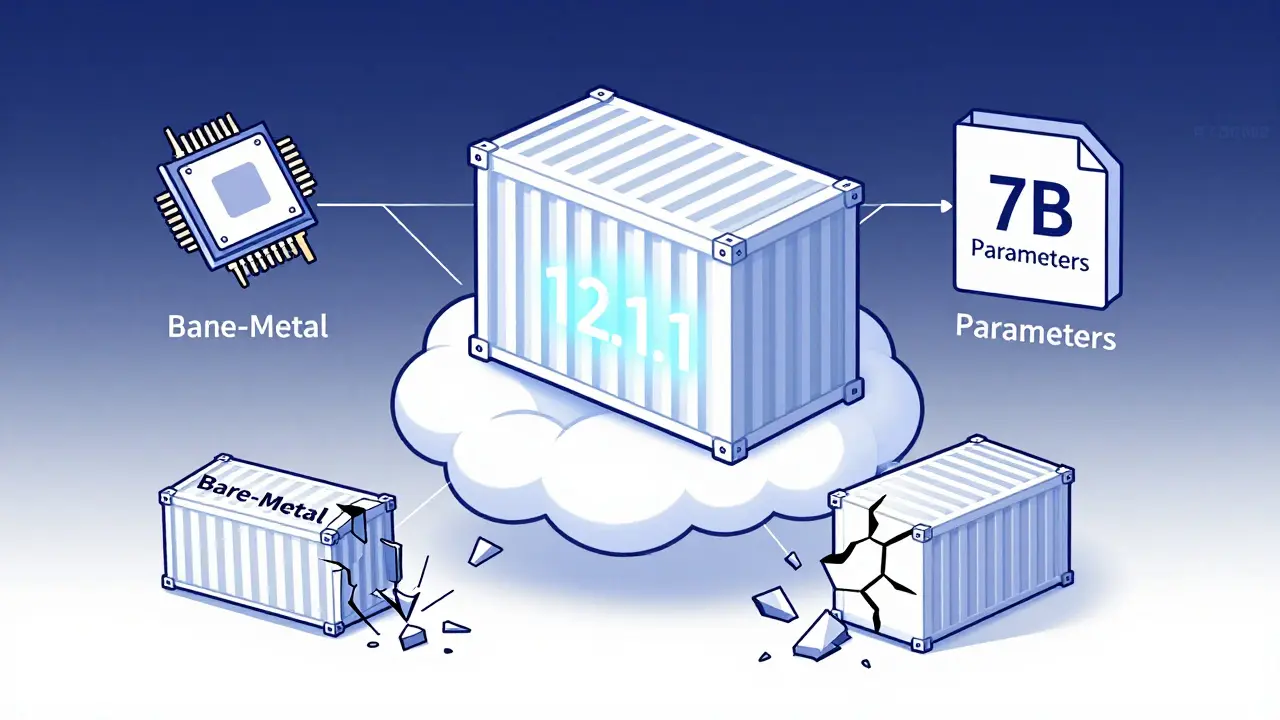
Containerizing large language models requires precise CUDA version matching, optimized Docker images, and secure model formats like .safetensors. Learn how to reduce startup time, shrink image size, and avoid the most common deployment failures.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Why Large Language Models Excel: Transfer, Generalization, and Emergent Abilities Explained
Jun, 13 2026
Practical Applications of Generative AI: A 2026 Industry Guide
Mar, 30 2026
Search Enhancement Using Large Language Models: Semantic Understanding at Scale
Apr, 26 2026

Understanding Per-Token Pricing for Large Language Model APIs: A Cost Guide
May, 2 2026

Mixture-of-Experts (MoE) in LLMs: Balancing Cost, Speed, and Quality
Jun, 11 2026