
Tag: GPU for AI
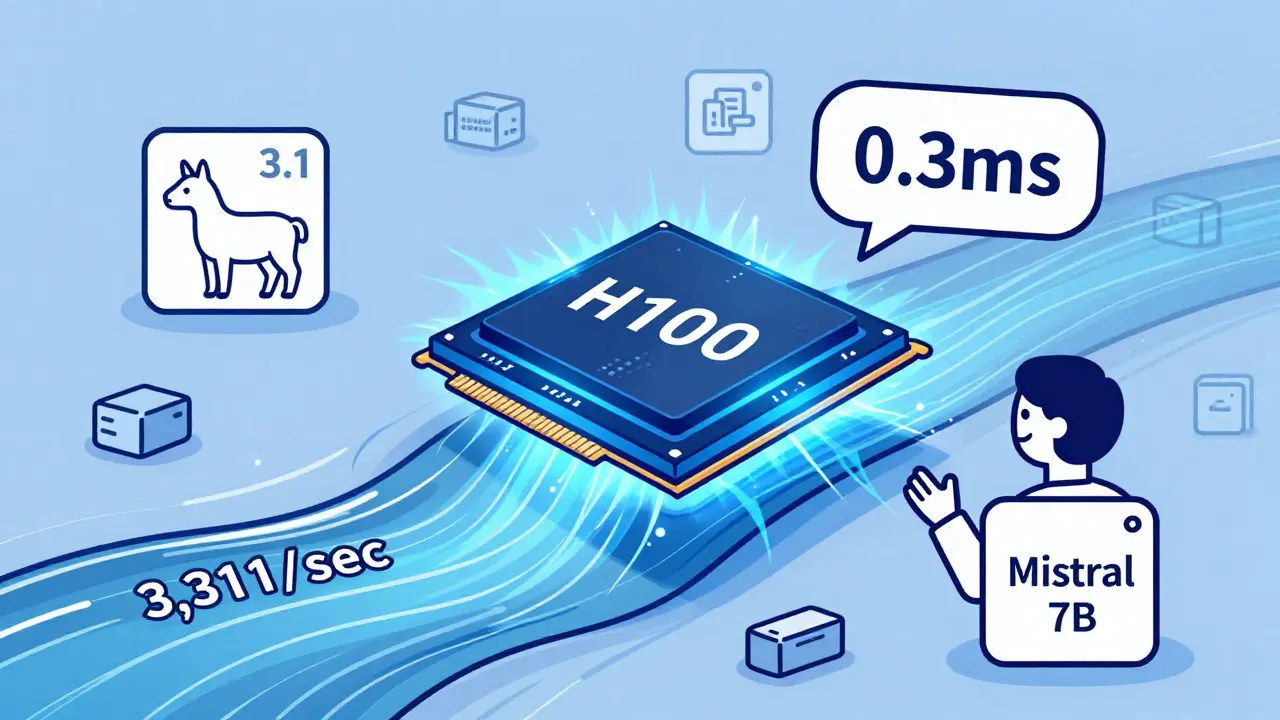
Learn how to choose between NVIDIA A100, H100, and CPU offloading for LLM inference in 2025. See real performance numbers, cost trade-offs, and which option actually works for production.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Fintech Experiments with Vibe Coding: Mock Data, Compliance, and Guardrails
Jan, 23 2026
Prompt Length vs Output Quality: Why Shorter Prompts Often Win in LLMs
May, 3 2026

Communicating Governance Without Killing Velocity: Dos and Don'ts for Platform Teams
Jun, 18 2026
Disaster Recovery for Large Language Model Infrastructure: Backups and Failover
Dec, 7 2025
Why Transformers Replaced RNNs: Parallelization and Long-Range Dependencies in LLMs
May, 4 2026