
Tag: GPU memory optimization
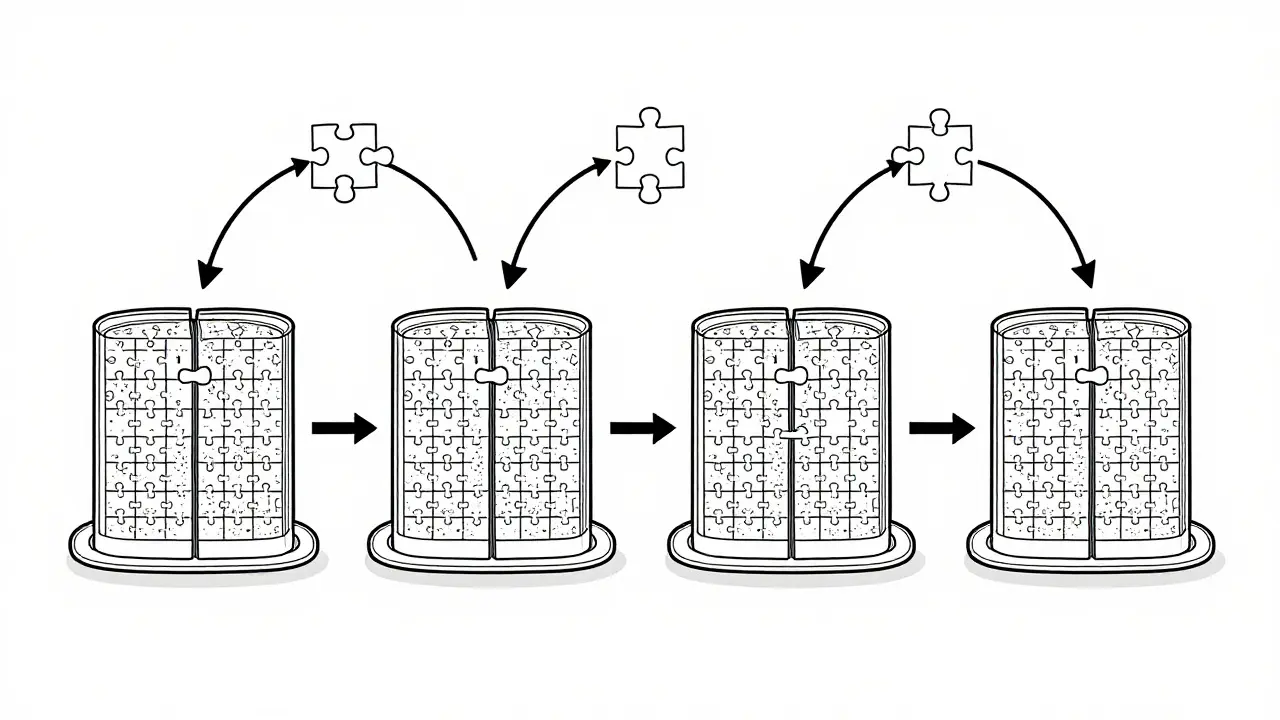
Tensor parallelism lets you run massive LLMs across multiple GPUs by splitting model layers. Learn how it works, why NVLink matters, which frameworks support it, and how to avoid common pitfalls in deployment.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Long-Context AI Explained: Rotary Embeddings, ALiBi & Memory Mechanisms
Feb, 4 2026
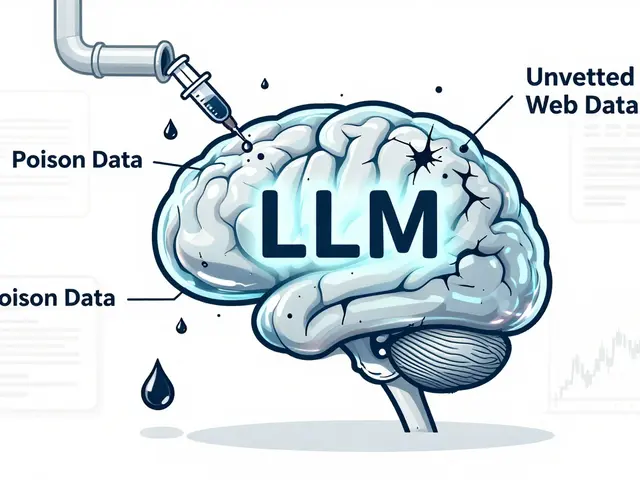
Training Data Poisoning Risks for Large Language Models and How to Mitigate Them
Jan, 18 2026
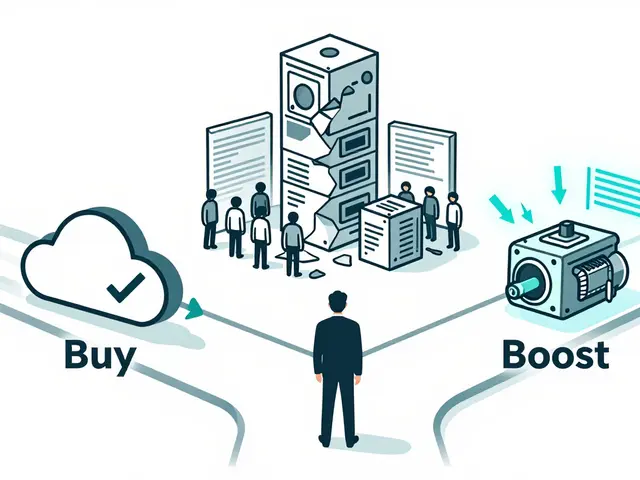
Build vs Buy for Generative AI Platforms: A Practical Decision Framework for CIOs
Feb, 1 2026

Why Multimodality Is the Future of Generative AI Beyond Text-Only Systems
Nov, 15 2025

Domain-Specialized Large Language Models: Code, Math, and Medicine
Oct, 3 2025