
Tag: KV caching
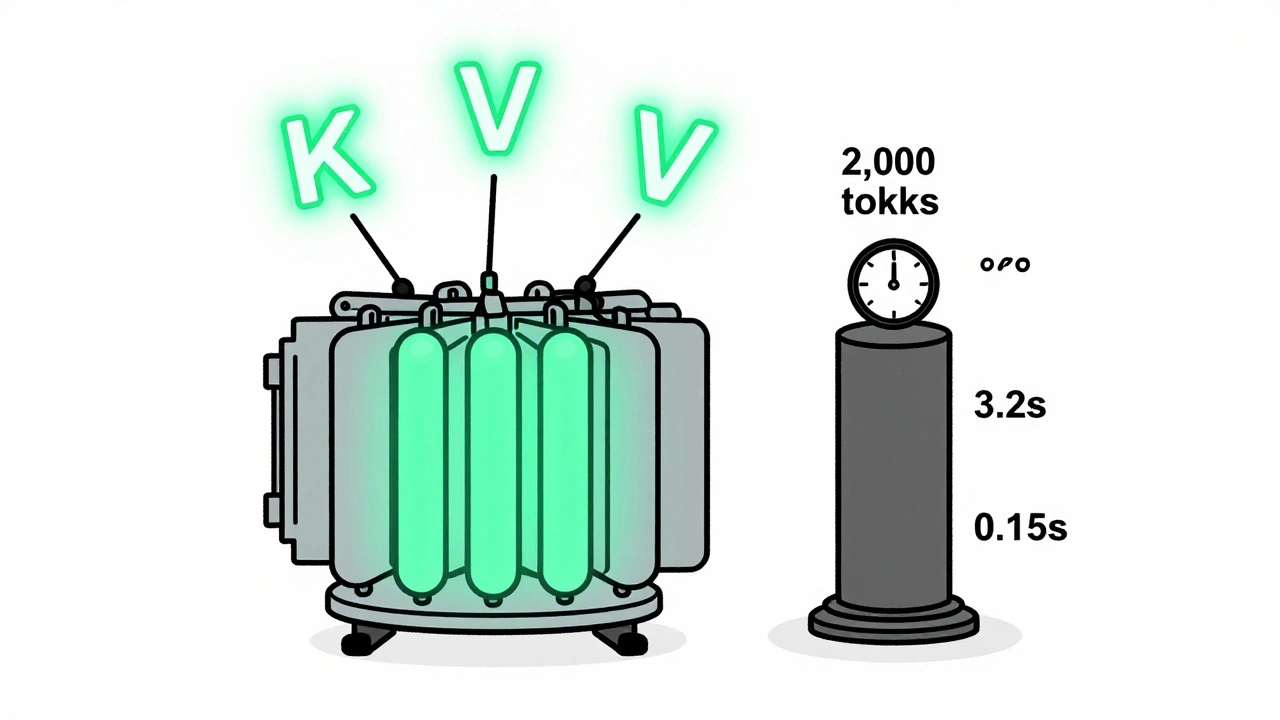
KV caching and continuous batching are essential for fast, affordable LLM serving. Learn how they reduce memory use, boost throughput, and enable real-world deployment on consumer hardware.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Schema-Constrained Prompts: Forcing JSON and Structured Outputs from LLMs
May, 25 2026

Human-in-the-Loop Operations for Generative AI: Review, Approval, and Exceptions Strategy Guide
Mar, 26 2026
Secure Prompting for Vibe Coding: How to Ask for Safer Code
Oct, 2 2025
Design Systems for AI-Generated UI: Keeping Components Consistent
Mar, 11 2026
Lower-Cost Tokens in Generative AI: Economics That Unlock New Use Cases
May, 20 2026