
Tag: LLM containerization
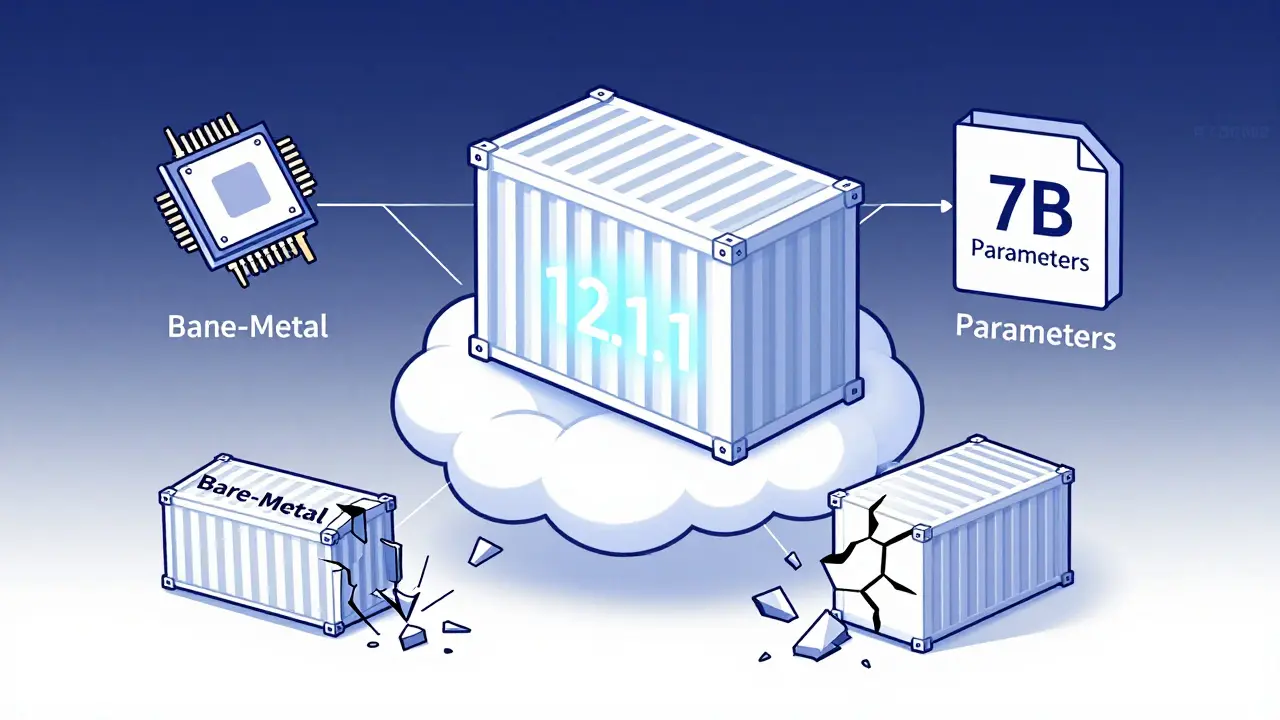
Containerizing large language models requires precise CUDA version matching, optimized Docker images, and secure model formats like .safetensors. Learn how to reduce startup time, shrink image size, and avoid the most common deployment failures.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Enterprise Adoption, Governance, and Risk Management for Vibe Coding
Dec, 16 2025
Human-in-the-Loop Review Workflows for Fine-Tuned LLMs: A Practical Guide
Jun, 15 2026

Safety in Multimodal Generative AI: How Content Filters Block Harmful Images and Audio
Feb, 15 2026
How Next-Gen LLMs Actually Follow Instructions: From RLHF to AutoIF
May, 16 2026

Schema-Constrained Prompts: Forcing JSON and Structured Outputs from LLMs
May, 25 2026