
Tag: tensor parallelism
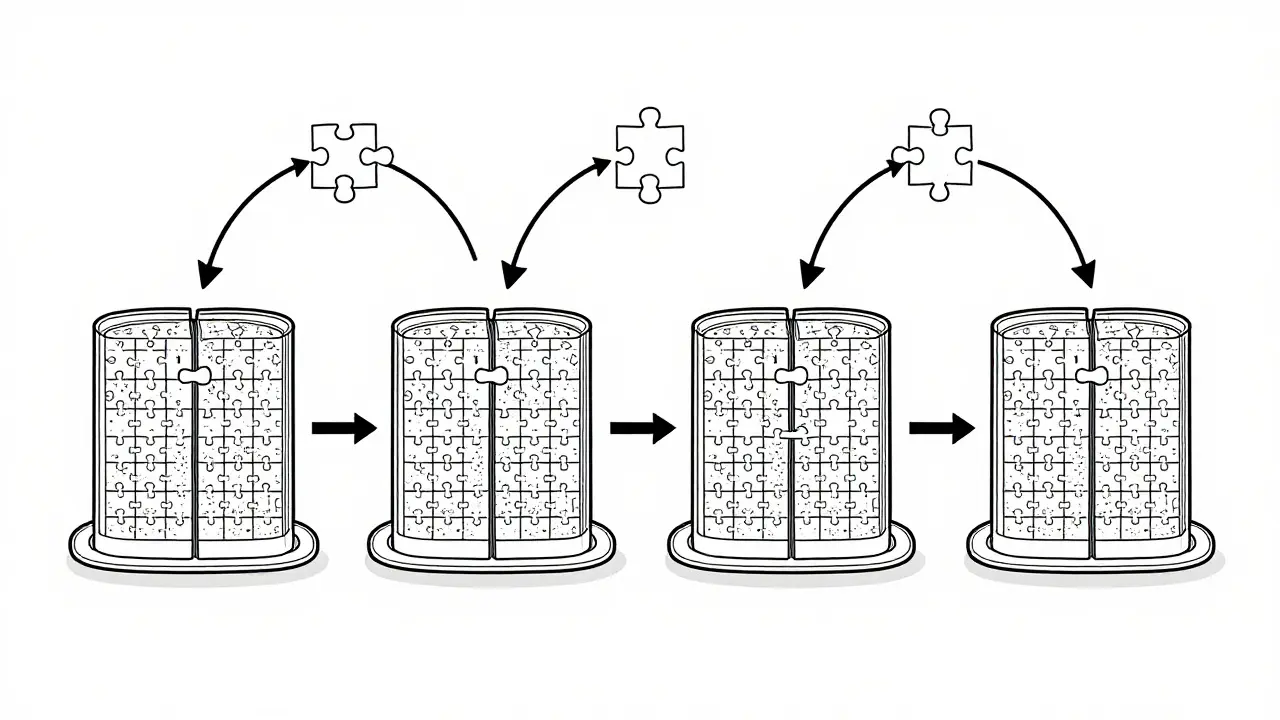
Tensor parallelism lets you run massive LLMs across multiple GPUs by splitting model layers. Learn how it works, why NVLink matters, which frameworks support it, and how to avoid common pitfalls in deployment.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts

Runtime Protections for Vibe-Coded Services: WAFs, RASP, and Rate Limits
May, 28 2026

Team Size Compression: How to Deliver More with Smaller, Leaner Teams
May, 8 2026
Generative AI Cost Models 2026: Build vs Buy, Token Pricing & Infrastructure
Jul, 7 2026

Contact Center ROI from Generative AI: Handle Time, CSAT, and First Contact Resolution
Jun, 14 2026
The Next Wave of Vibe Coding Tools: What's Missing Today
Mar, 20 2026