
Tag: transformer efficiency
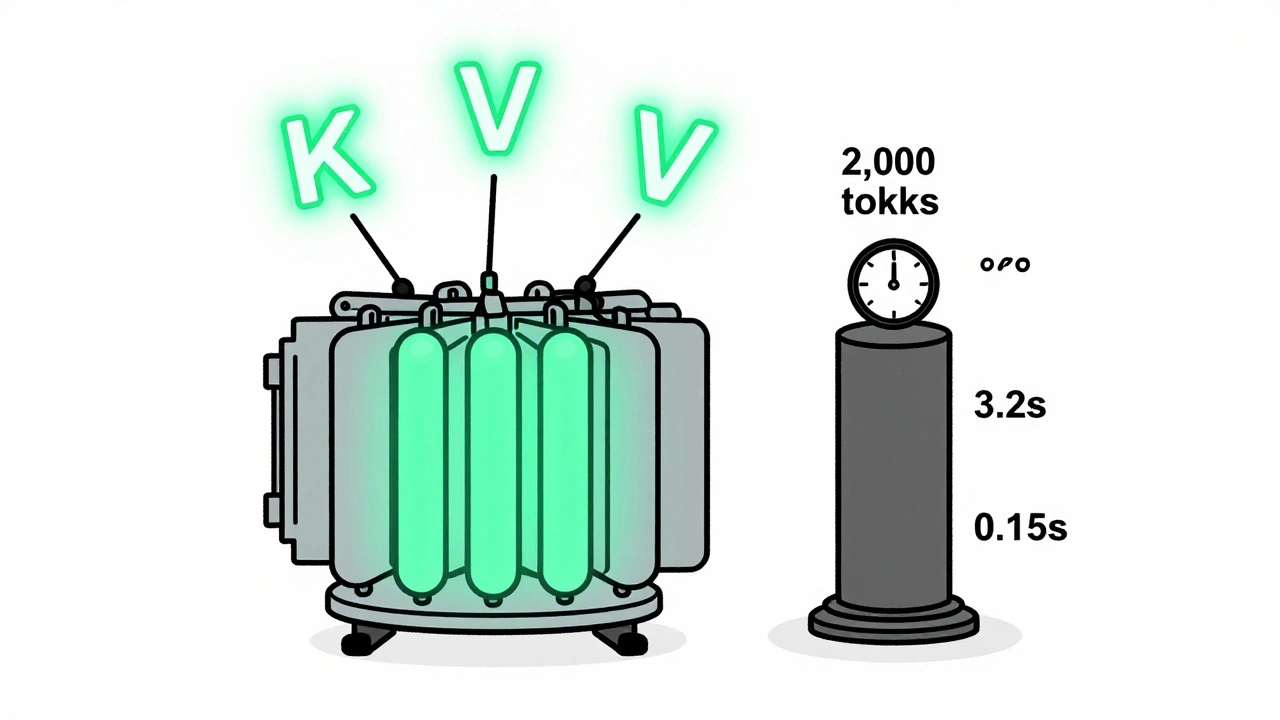
KV caching and continuous batching are essential for fast, affordable LLM serving. Learn how they reduce memory use, boost throughput, and enable real-world deployment on consumer hardware.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Hyperparameter Selection for Fine-Tuning Large Language Models Without Forgetting
Feb, 11 2026

Pattern Libraries for AI: How Reusable Templates Improve Vibe Coding
Jan, 8 2026

Dependency Injection in Vibe-Coded Backends: Testability and Modularity
May, 26 2026

Guarded Tool Access: Sandboxing External Actions in LLM Agents
Mar, 2 2026
Accessibility Regulations for Generative AI Products: WCAG and Assistive Features
Mar, 6 2026