

You type a prompt. An AI writes the code. You hit run. It works... mostly. This is vibe coding, defined as a development paradigm where developers use generative AI to produce functional code from high-level descriptions rather than writing line-by-line. It’s fast. It’s exciting. And if you aren’t careful with your testing strategy, it’s going to break your production environment in spectacular ways.
We are past the hype cycle of "AI writes everything." Now we are in the reality check phase. The code moves at lightning speed, but traditional testing methods are lagging behind. If you treat AI-generated code like human-written code, you’ll miss the unique errors that LLMs introduce. This guide breaks down how to actually test these architectures using unit, contract, and end-to-end (E2E) strategies that work for 2026.
The Reality of Testing AI-Generated Code
Let’s look at the numbers because they tell a scary story. According to a Q3 2025 benchmark by PropelCode.ai, teams using vibe coding build prototypes 3.7 times faster than traditional methods. That’s incredible velocity. But here’s the catch: conventional test suites caught only 41% of logic errors in vibe-coded apps compared to 78% in traditionally developed code.
Why? Because AI hallucinates logic. It doesn’t just make syntax errors; it makes *plausible* logical errors. It might write a function that looks perfect, handles the happy path beautifully, but fails silently when an edge case hits. In January 2025, Memberstack analyzed this shift and found that while 68% of teams use AI-assisted coding, only 22% have structured testing frameworks specifically for it. You cannot rely on luck. You need a multi-layered defense.
Unit Testing: Applying F.I.R.S.T. Principles to AI Output
Unit tests are your first line of defense. In traditional development, you might write them after the code. In vibe coding, you must define them *before* or *during* generation. The key is applying the F.I.R.S.T. principles: Fast, Independent, Repeatable, Self-Validating, and Timely.
SynapticLabs’ November 2025 guide revealed that 79% of AI-generated unit tests violated at least one of these principles without human refinement. The AI often creates slow tests that hit real databases or dependent services. Here is how to fix it:
- Prompt for TDD: Don’t just ask for code. Ask for Test-Driven Development. Use prompts like: “Write failing tests first to define expected behavior, then implement just enough code to pass.”
- Force Isolation: Explicitly instruct the AI to mock external dependencies. If your unit test calls an API, it’s not a unit test. It’s an integration test disguised as one.
- Check Coverage Gates: Implement quality gates in your CI/CD pipeline. SynapticLabs recommends a minimum of 85% line coverage and a maximum execution time of 5 seconds per module.
Dr. Sarah Chen, Principal Engineer at Google Cloud AI, noted in her 2025 presentation that “AI rarely produces perfect code on the first attempt.” The iterative loop-generate, test, refine-is where the quality comes from. Your unit tests are the filter that keeps bad code out.
Contract Testing: Bridging the Business Logic Gap
This is where most vibe-coded projects fail. Unit tests check if a function returns the right number. Contract tests check if two services talk to each other correctly. They validate the agreement between producer and consumer.
Here is the hard truth from Codecentric’s February 2025 field report: AI tools typically generate database connection tests (verifying INSERT statements), but they fail to validate business process contracts-like payment workflows or booking systems-in 83% of cases. The AI sees the technical structure but misses the business intent.
To fix this, you need explicit interface specifications. Emergent.sh’s April 2025 best practices suggest providing the AI with precise schemas before generating implementation code. Your prompt should look like this:
“Define all API contracts with precise request/response schemas. Ensure the ‘CheckoutService’ validates inventory availability before confirming payment. Generate Pact tests to enforce this contract.”
Without this, you get what Reddit user u/CodingWizard99 experienced in March 2025: “I missed a critical payment validation bug because the AI tests only checked database writes, not business logic.” He fixed it by adding explicit contract test prompts. You must do the same. Treat the API contract as the source of truth, not the implementation code.
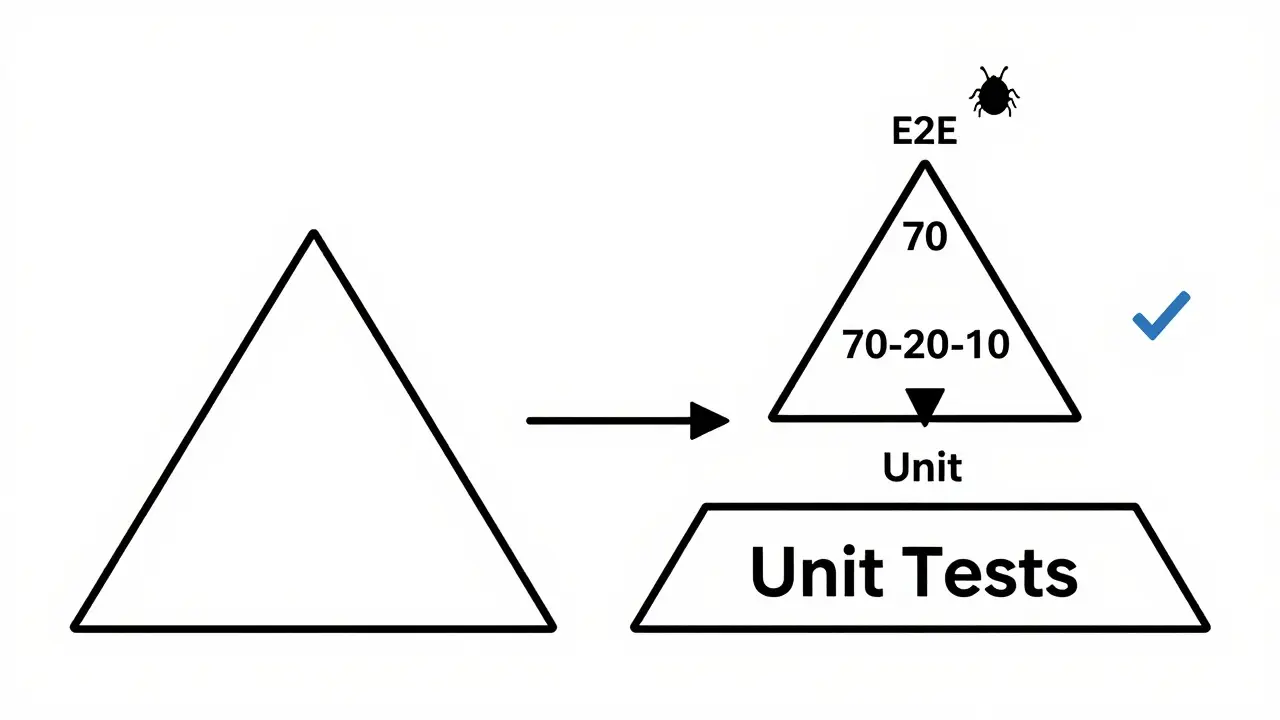
End-to-End (E2E) Testing: The Test Pyramid Shift
E2E tests simulate real user behavior. They are expensive and slow, so you shouldn’t have too many. But in vibe coding, the ratio changes. Traditional development often follows a 50-30-20 split (unit-integration-E2E). Successful vibe coding teams, according to SynapticLabs, maintain a 70-20-10 ratio.
Wait, why fewer E2E tests? Because the volume of code generated by AI is massive. If you write E2E tests for every tiny change, you’ll drown. Instead, focus E2E tests on critical user journeys:
- User registration and authentication flow.
- Core transaction paths (e.g., purchase, subscription).
- Data integrity checks across multiple services.
Use tools like Playwright or Cypress, but configure them to be resilient. AI-generated UI code can be fragile. One class name change breaks ten tests. Use semantic selectors (data-testid) instead of CSS classes in your E2E scripts. This decouples your tests from the styling details that AI might arbitrarily change during refactoring.
Comparison: Traditional vs. Vibe-Coded Testing
| Aspect | Traditional Testing | Vibe-Coded Architecture Testing |
|---|---|---|
| Primary Goal | Catch bugs in hand-written logic | Validate AI interpretation of requirements |
| Error Pattern | Syntax, typos, known edge cases | Plausible but incorrect business logic |
| Test Generation | Manual or semi-automated | AI-assisted with strict prompt engineering |
| Business Logic Coverage | High (developer understands context) | Low (AI misses nuance without explicit prompts) |
| Version Control Frequency | ~4.7 commits/session | ~12.3 commits/session (after every AI change) |
Notice the version control difference. Memberstack’s 2025 guide emphasizes rigorous Git hygiene. Commit after every AI-generated change. Why? Because if the AI introduces a subtle regression, you need to pinpoint exactly which prompt caused it. Without atomic commits, debugging becomes a nightmare.
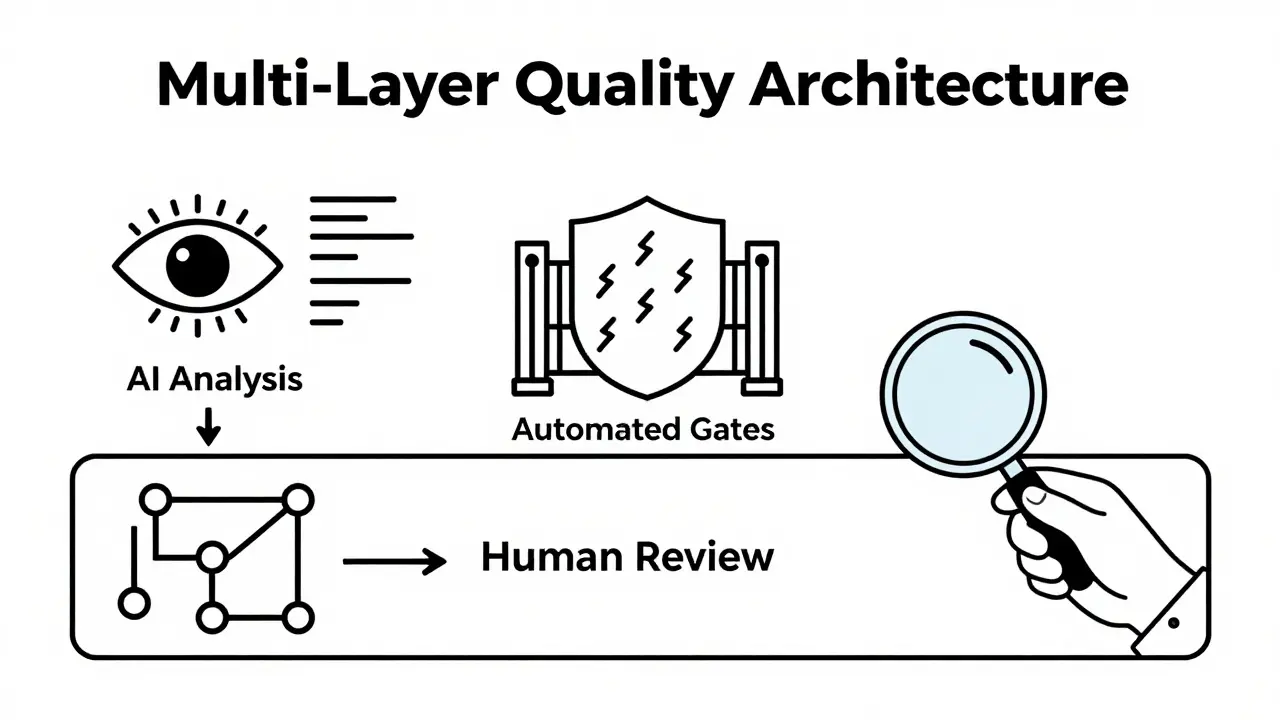
The Multi-Layer Quality Architecture
PropelCode.ai developed a framework in September 2025 that addresses these gaps. It’s called the Multi-Layer Quality Architecture. It doesn’t rely on one type of test. It uses three layers:
- Layer 1: AI-Powered Real-Time Analysis. Catches 63% of issues during code generation. This involves using AI assistants that critique their own output before you even accept it.
- Layer 2: Automated Quality Gates. Identifies 28% of issues during CI/CD. These are your unit and contract tests running automatically on every commit.
- Layer 3: Strategic Human Review. Addresses the remaining 9% of complex business logic issues. This is where you, the developer, step in to verify that the AI didn’t misinterpret a nuanced requirement.
This approach is far superior to traditional code reviews, which IEEE research shows catch only 26% of defects. The key is trusting but verifying. Never trust the AI blindly.
Practical Workflow for Developers
So, how do you implement this tomorrow? Here is a workflow validated across 142 teams in PropelCode.ai’s study:
- Define Outcome Specifications (2-4 hours): Before prompting, write down exactly what the feature should do. Include edge cases.
- Generate with Test Requirements (1-3 iterations): Prompt the AI to generate both code and tests simultaneously. Example: “Implement Feature X with complete business logic. Then, generate comprehensive unit tests covering all edge cases.”
- Immediate Validation (15-30 minutes): Run the tests locally. Check basic flows and edge cases.
- Specific Feedback: If tests fail, don’t say “fix it.” Say “the AI missed empty state validation. Add a test for null input.” Precision matters.
- Iterate with Refinement Prompts: Chain your prompts. First code, then unit tests, then contract tests. Don’t try to do it all in one go.
Emergent.sh documents a systematic debugging approach: copy-paste error messages directly into the AI tool, request multiple hypotheses, and test each fix in isolation. This reduced debugging time by 58% in their case studies.
Future Trends and Tools
The landscape is evolving rapidly. In January 2026, GitHub launched “Copilot Tests,” an assistant that analyzes code patterns and generates targeted test cases with 73% accuracy on business logic validation. This addresses the biggest gap identified in earlier reports.
Forrester predicts that by Q4 2027, specialized test generation prompts will become standardized, adopted by 85% of teams. We are moving toward “quality gates as code,” where test requirements are explicitly defined in development prompts. Early adopters report 42% fewer regression bugs using this method.
However, caution remains necessary. Dr. Andrew Ng predicts that vibe coding with robust testing will become standard for 70% of new development by 2028. But the IEEE Software journal warns that without addressing the business logic testing gap, we risk creating a generation of fragile applications. The ball is in your court. Build the tests, or build the debt.
What is vibe coding?
Vibe coding is a development approach where developers use generative AI to create functional code from high-level natural language prompts, shifting the role from code author to code curator and validator.
Why do traditional tests fail for AI-generated code?
Traditional tests often miss plausible logical errors introduced by AI. Studies show conventional suites catch only 41% of logic errors in vibe-coded apps versus 78% in traditional code, as AI may hallucinate correct-looking but functionally wrong implementations.
How important is contract testing in vibe coding?
Critical. AI often fails to validate business process contracts (like payment workflows) in 83% of cases. Explicitly defining API schemas and using contract testing tools like Pact ensures services communicate correctly despite AI's lack of business context.
What is the recommended test pyramid ratio for vibe coding?
Successful teams maintain a 70-20-10 ratio of unit-to-integration-to-E2E tests. This differs from the traditional 50-30-20 split, emphasizing more unit tests to handle the high volume of AI-generated code efficiently.
How often should I commit code when using vibe coding?
Very frequently. Best practices recommend committing after every AI-generated change, averaging 12.3 commits per session. This allows for precise debugging and rollback if an AI iteration introduces regressions.
What are F.I.R.S.T. principles in unit testing?
F.I.R.S.T. stands for Fast, Independent, Repeatable, Self-Validating, and Timely. These principles ensure unit tests are efficient and reliable, which is crucial since 79% of raw AI-generated tests violate at least one principle without human refinement.
Can AI tools generate their own tests effectively?
Partially. While AI can generate structural tests, it often misses business logic nuances. Newer tools like GitHub Copilot Tests (2026) improve accuracy to 73% for business logic, but human oversight and explicit prompt engineering remain essential for full coverage.
 Artificial Intelligence
Artificial Intelligence




