For years, the industry followed a simple rule: bigger models need more data and more compute. If you wanted a smarter Large Language Model, you threw money at GPUs and fed it everything on the internet. But as we hit 2026, that brute-force approach is hitting a wall. The cost of doubling model size is skyrocketing, and the returns are diminishing. The real breakthrough isn't just in hardware anymore; it's in how we feed information to these models.
This is where curriculum learning and optimized data mixtures come in. Instead of dumping random text into a neural network, researchers are now treating training like a structured education system. You start with basics, move to complex reasoning, and ensure the content is fresh and accurate. Recent studies from MIT-IBM Watson AI Lab show this isn't just theory-it can boost performance by up to 15% without adding a single parameter. It’s about working smarter, not harder.
The Hidden Variable in Scaling Laws
We’ve spent the last decade obsessed with parameter counts. But if you look closely at the latest scaling laws, there’s a hidden variable that everyone ignored for too long: data composition. In late 2025, Chen et al. published research in Nature Machine Intelligence that shook things up. They found that optimizing your data mixture could yield significant gains without increasing the model's size. Think of it like diet. Eating more calories (data) doesn't make you stronger if those calories are junk food. You need the right nutrients.
The problem? Most teams are still using random data ordering. They scrape the web, clean it slightly, and shuffle it. This works for basic language understanding, but it fails when you need deep reasoning or factual accuracy. NVIDIA’s 2025 framework identified three critical dimensions for data: breadth, depth, and freshness. Breadth covers how many domains you touch. Depth measures the complexity within those domains. Freshness ensures the model isn't learning outdated facts. Ignoring any of these creates blind spots in your model’s knowledge.
Designing the Perfect Data Mixture
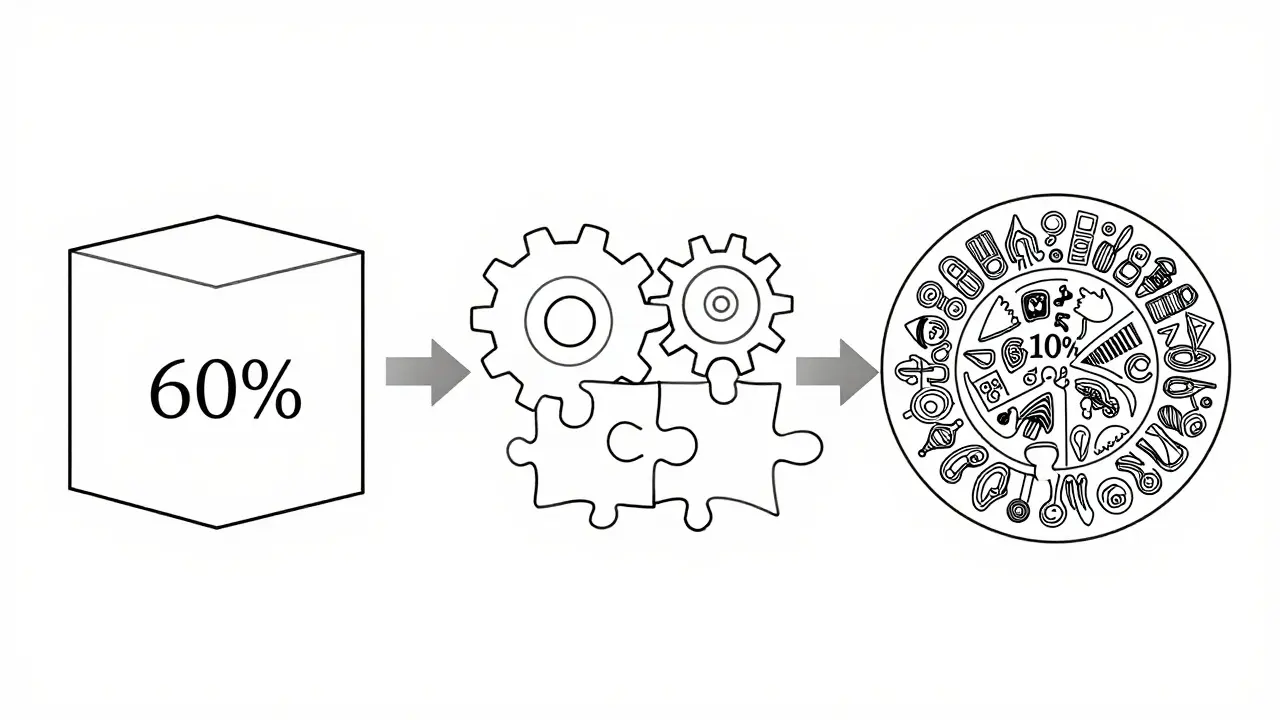
So, what does a good data mixture actually look like? According to MIT-IBM’s meta-analysis, the optimal distribution follows a power law. You don’t want equal parts of everything. Instead, aim for this split:
- 60% Foundational Knowledge: Basic language structures, common facts, and general world knowledge. This builds the backbone.
- 30% Intermediate Complexity: Specialized domains, nuanced reasoning, and professional writing styles. This adds depth.
- 10% High-Difficulty Content: Abstract concepts, multi-step mathematical reasoning, and advanced logic puzzles. This pushes the model’s limits.
Why this ratio? Because if you start with hard problems, the model gets confused. If you stay only on easy stuff, it plateaus. The key is progression. Wang et al. from the ACL Anthology showed that models trained with difficulty-graded curricula achieved 5.8% lower loss at the same compute budget compared to random ordering. That’s free performance. You’re getting more out of every dollar you spend on electricity.
The Role of Data Freshness and Accuracy
It’s not just about difficulty; it’s about relevance. A model trained on news from 2020 is useless for current events. NVIDIA quantified this, showing that optimized data freshness contributes 3.2% to overall performance. But “fresh” means different things depending on the topic. For technology content, a six-month recency window is ideal. For historical data, you might go back 24 months or more. The trick is tagging your data correctly.
You also need to verify factual accuracy. Feeding a model hallucinated Wikipedia articles teaches it to lie. Successful implementations use specialized tagging systems that categorize content by syntactic depth, concept density, and verification against trusted knowledge bases. Yes, this adds overhead. Meta reported an 8-12% increase in preprocessing costs, but they saw faster convergence during actual training. It’s an upfront investment that pays off later.
Performance Gains vs. Implementation Costs
Let’s talk numbers. How much better are these models really? In controlled experiments across 12 model families, MIT-IBM found that optimized data mixtures led to:
- 22.4% higher accuracy on complex reasoning tasks (like MATH and GSM8K benchmarks).
- 28.3% improvement in mathematical reasoning.
- 24.1% improvement in scientific knowledge retention.
- 19.8% improvement in multilingual capabilities.
But here’s the catch: implementation is hard. Meta’s team spent 37% more time preprocessing data for Llama 3.1 because of their curriculum system. Smaller teams struggle even more. A survey by the AI Infrastructure Alliance showed that only 28% of organizations with fewer than 50 ML engineers successfully implemented these strategies. Why? Because you need robust data engineering pipelines. You can’t just write a script and hope for the best.
| Feature | Random Data Ordering | Curriculum-Based Training |
|---|---|---|
| Implementation Effort | Low | High (3-6 months setup) |
| Reasoning Performance | Baseline | +22.4% on complex tasks |
| Compute Efficiency | Standard | 18.7% less compute for same result |
| Multilingual Support | Inconsistent | +19.8% improvement |
| Best For | Basic chatbots, small models | Enterprise-grade, reasoning-heavy models |
Expert Perspectives and Industry Debate
Not everyone agrees on how far to take this. Dr. Anna Huang from MIT-IBM argues that data mixture optimization is the next frontier, potentially unlocking 2-3× effective model size increases. Bill Dally at NVIDIA echoes this, saying curated data can match the gains of 30% larger models. However, Noam Brown from OpenAI remains skeptical. He argues that at trillion-parameter scales, simple data quantity dominates, and sophisticated curricula offer diminishing returns.
The truth likely lies in the middle. Stanford’s Center for Research on Foundation Models suggests curriculum learning shines for models up to 500 billion parameters. Beyond that, you need architectural innovations to leverage structured training. Also, Google’s Gemma 3 release proved you don’t need over-engineering. Simple difficulty sorting achieved 85% of the benefits of complex multi-dimensional curricula with only 15% of the effort. Sometimes, simple wins.
Practical Steps for Implementation
If you’re ready to try this, don’t boil the ocean. Start small. Here’s a practical roadmap based on successful case studies:
- Annotate Your Data: Tag content by complexity, domain, and quality. Use tools like DataComp (released by MIT-IBM in August 2025) to speed this up. It provides pre-annotated datasets and templates, cutting implementation time by 40%.
- Design Progression Schedules: Decide how quickly you’ll move from easy to hard data. Don’t rush it. Let the model master basics before introducing abstract logic.
- Integrate with Pipelines: Ensure your training loop can handle dynamic data switching. This often requires custom code or specialized libraries.
- Validate Rigorously: Compare your curriculum-trained model against a baseline using standard benchmarks. Look specifically at reasoning and factual accuracy, not just perplexity.
Be prepared for bottlenecks. User 'tensor_slinger' on Reddit noted that data annotation became their biggest hurdle, requiring three full-time engineers. Also, watch out for multilingual pitfalls. A GitHub issue on Hugging Face documented cases where English-centric curricula caused 15% performance drops in low-resource languages. Balance is key.
Market Trends and Future Outlook
The market is catching on fast. The global market for AI data optimization tools hit $2.8 billion in Q4 2025, growing 47% year-over-year. Curriculum-specific tools make up 18% of that. AWS’s DataMixer service leads with 31% market share, while startups like DataHarmonics are raising millions to fill gaps. By 2027, analysts predict optimized data mixtures will contribute 25-30% of performance gains in new LLMs. We’re moving away from pure parameter scaling toward intelligent data curation.
However, fragmentation is a risk. There are 14 competing frameworks for curriculum implementation, none holding more than 22% market share. This lack of standardization makes interoperability difficult. As you build your pipeline, choose tools that are open-source or widely adopted to avoid vendor lock-in. Keep an eye on MIT-IBM’s upcoming DataComp-2026 dataset, which promises comprehensive annotations across 12 dimensions. It could become the new gold standard.
What is curriculum learning in LLMs?
Curriculum learning is a training strategy where models are exposed to data in a structured order, typically starting with simpler examples and progressing to more complex ones. Unlike random data shuffling, this approach mimics human learning, helping models converge faster and achieve higher accuracy on difficult tasks like reasoning and math.
How much does optimizing data mixtures improve performance?
Research indicates that optimized data mixtures can yield up to 15% performance gains without increasing parameter counts. Specifically, models have shown 22.4% higher accuracy on complex reasoning tasks and 28.3% improvement in mathematical reasoning compared to standard random training methods.
Is curriculum learning worth the extra cost?
For most enterprise applications, yes. While implementation adds 8-12% to preprocessing costs and requires 3-6 months of setup, it reduces total training compute needs by 18.7% to reach equivalent performance levels. The savings in GPU hours often outweigh the initial engineering investment.
What is the recommended data mixture ratio?
MIT-IBM recommends a power-law distribution: 60% foundational knowledge (basic language/facts), 30% intermediate complexity (specialized domains), and 10% high-difficulty content (abstract reasoning). This balance ensures strong baselines while pushing the model’s upper limits.
Does curriculum learning work for multilingual models?
Yes, but with caution. It can improve multilingual capabilities by 19.8%, but uneven complexity distributions can hurt low-resource languages. Teams must ensure balanced representation across all target languages to avoid performance degradation in specific dialects.
What tools help implement data mixtures?
Open-source tools like DataComp (by MIT-IBM) provide pre-annotated datasets and templates. Commercial options include AWS DataMixer and services from startups like DataHarmonics. These tools help automate data tagging, complexity scoring, and curriculum scheduling.
When should I use simple vs. complex curricula?
Simple difficulty sorting achieves 85% of the benefits of complex multi-dimensional curricula with only 15% of the effort. Start with simple approaches unless you have significant resources and specific needs for fine-grained control over domain-specific progression.
 Artificial Intelligence
Artificial Intelligence