Here is the hard truth about deploying large language models in business: you cannot automate your way to perfection. No matter how sophisticated your fine-tuning process or how massive your training dataset, there is a ceiling-usually around 80% to 85% accuracy-where pure automation stops delivering reliable results. The final stretch of precision requires something algorithms still struggle with: human judgment. This is where Human-in-the-Loop (HITL) review workflows become not just a safety net, but the engine that drives true enterprise-grade performance.
If you are building AI systems for healthcare, finance, or legal services, accepting a model's output without scrutiny is a liability you can't afford. HITL integrates human expertise directly into the decision-making pipeline, creating a hybrid system where machines handle volume and humans handle nuance. It transforms raw model outputs into trusted, auditable business actions.
What is Human-in-the-Loop (HITL) in the context of LLMs?
Human-in-the-Loop (HITL) is a workflow architecture where human experts intervene at critical stages of an AI system's operation to validate, correct, or approve outputs. Unlike fully automated systems, HITL ensures that high-stakes decisions are reviewed by people, combining machine speed with human accountability.
Why Your Fine-Tuned Model Still Needs Humans
You might wonder why fine-tuning isn't enough. You spent weeks curating data, adjusting hyperparameters, and running training jobs. The model looks great on test sets. So why add humans? Because test sets are static; real-world usage is chaotic. Hallucinations, subtle context shifts, and edge cases emerge only after deployment.
HITL addresses this by treating human feedback as a continuous improvement signal rather than a one-time fix. When a subject matter expert corrects a model's error, that correction doesn't just fix one instance-it becomes labeled training data for the next iteration. This creates a virtuous cycle: the model improves, human reviewers spend less time on obvious errors, and they can focus on complex, high-value judgments.
OneShot is an API-based platform that operationalizes this concept by routing failed LLM outputs to trained humans. In beta deployments, OneShot demonstrates how flagged outputs are sent to human batches who tweak prompts or provide context until the correct output emerges. These tweaks are stored as structured data, enabling faster future deployments with better guarantees. This proves that HITL is not a bottleneck; it is a data generation engine.The Four Tiers of Validation: Building a Scalable Workflow
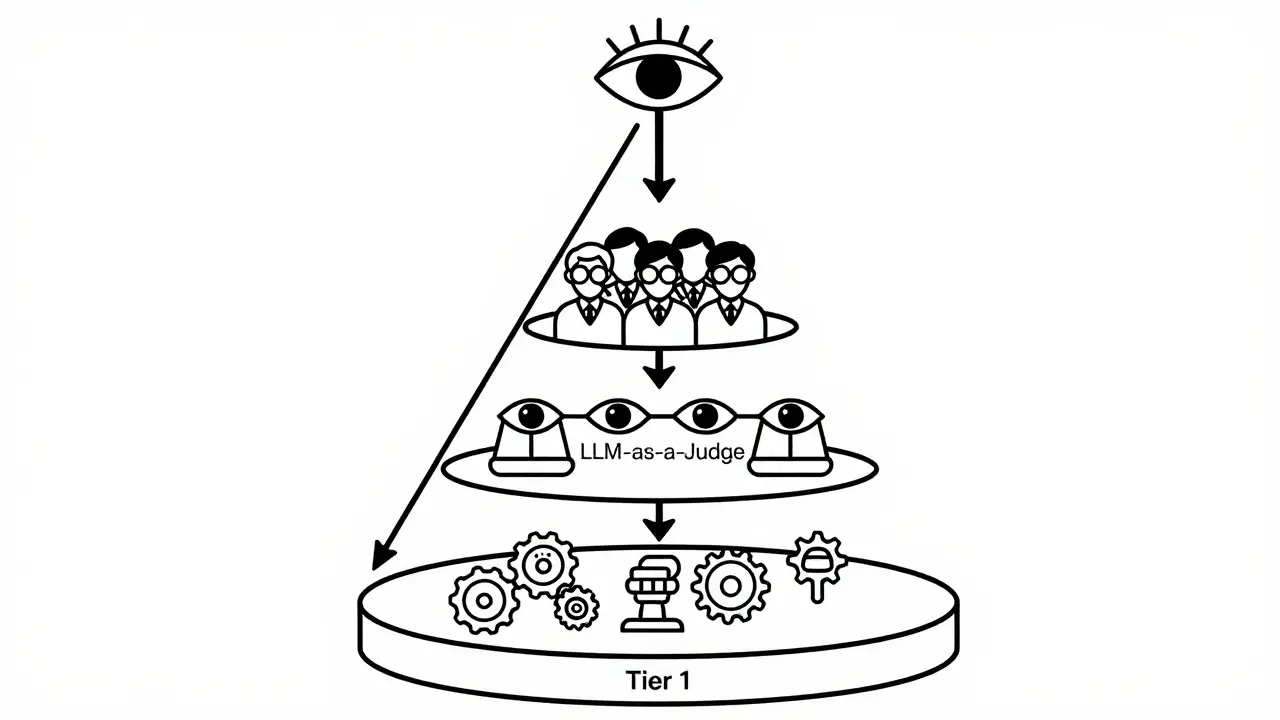
Reviewing every single output is expensive and slow. To make HITL viable at scale, you need a tiered approach. Not all errors are created equal, and not all tasks require a senior lawyer or doctor. Kili Technology recommends a hierarchy that sequences interventions from fastest to most intensive:
- Tier 1: Automated Checks. Use cheap, fast filters first. Validate formatting rules, screen for policy keywords, run unit tests for code, and verify citation presence. If the output fails here, reject it immediately without human eyes.
- Tier 2: LLM-as-a-Judge. For scalable scoring, use another LLM to evaluate the output against a rubric. Perform pairwise comparisons for A/B testing and tag risks. This catches many issues before they reach a human.
- Tier 3: HITL Review. Reserve human experts for high-risk cases. Subject matter experts approve, correct, and assign severity classifications. This is where accountability lives.
- Tier 4: HOTL Monitoring. For remaining outputs, use Human-on-the-Loop (HOTL) approaches. This involves sampling audits, drift monitoring, and incident response protocols. Humans oversee the system rather than reviewing every line.
This structure solves the scalability paradox. You get comprehensive accuracy for critical tasks while maintaining speed for routine ones. The key is defining clear "risk triggers" that route work to the appropriate tier.
HITL vs. HOTL: Choosing the Right Pattern
Understanding the difference between HITL and HOTL is crucial for designing your architecture. They represent different trade-offs between control and cost.
| Feature | Human-in-the-Loop (HITL) | Human-on-the-Loop (HOTL) |
|---|---|---|
| Intervention Frequency | Every output or specific high-stakes steps | Only when uncertainty is high or risk triggers fire |
| Primary Goal | Maximum accuracy and accountability | Scalability and efficiency |
| Cost Profile | Higher due to consistent human labor | Lower, reserved for exceptions |
| Best For | Legal docs, financial advice, clinical support | Email drafting, summaries, general copilot apps |
| Feedback Loop | Direct corrections feed training data | Drift detection and periodic audits |
Use HITL when the downside of an error is severe-think legal exposure, financial loss, or safety risks. If you wouldn't accept a junior employee's work without review, don't accept the model's output without review either. Use HOTL for lower-stakes applications like internal email summarization, where occasional minor errors are acceptable if caught by a quick audit.
Designing the Feedback Loop: From Correction to Training
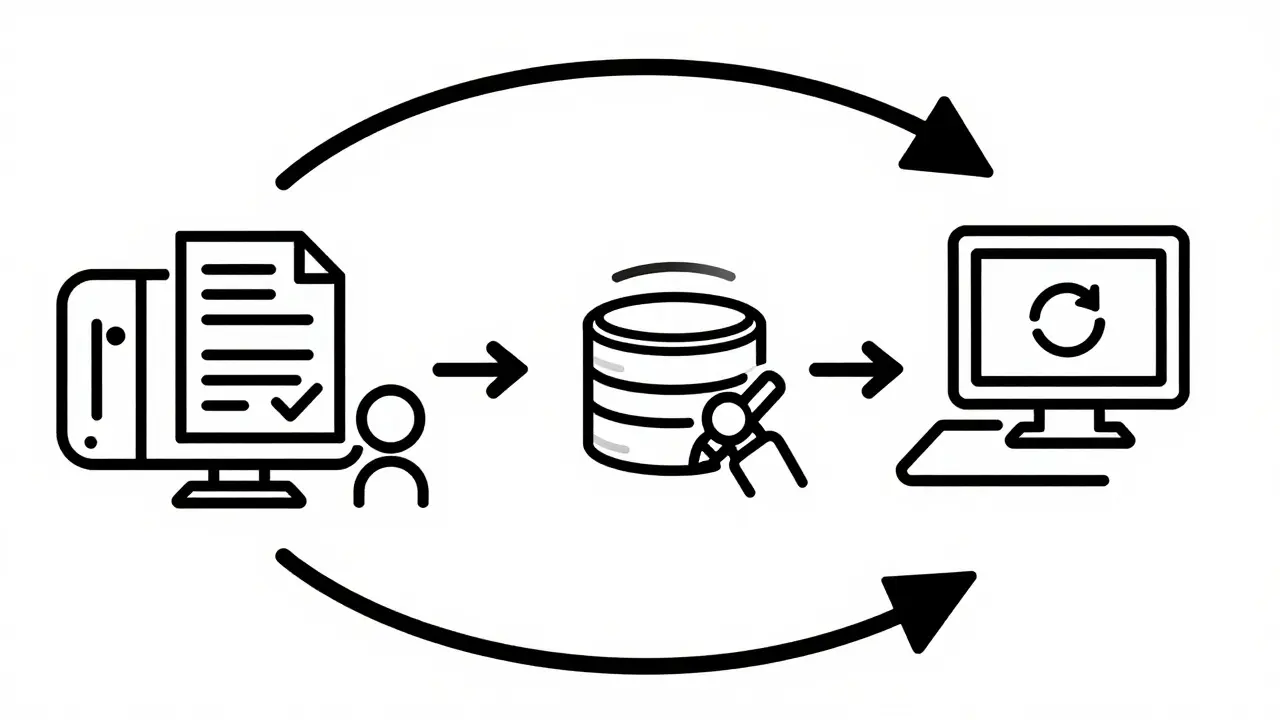
The magic of HITL lies in what happens after the human finishes their task. If corrections are discarded, you've just built a manual quality assurance team, not an AI system. You must close the loop.
Implement a pipeline where corrected outputs and reviewer notes are automatically transformed into evaluation datasets. This requires robust MLOps (Machine Learning Operations) integration. Track audit logs comprehensively, including reviewer identity, timestamp, guideline version, and the reasoning behind changes. This traceability is non-negotiable for compliance.
Consider the "correction gate" pattern. Here, experts edit model outputs, and these edits become direct feedback signals. Over time, you accumulate thousands of documented tweaks. As seen in OneShot’s deployment model, this dataset enables faster subsequent deployments because the model has already "learned" from past human interventions. You are essentially distilling human expertise into model weights.
Active Learning vs. HITL: Don't Confuse Them
A common mistake is conflating HITL with Active Learning. While both involve humans labeling data, their goals differ significantly.
- Active Learning is a training-phase strategy. The model identifies data points it is uncertain about and requests human labels specifically to improve its internal parameters efficiently. It prioritizes label efficiency.
- HITL is an operational-phase framework. Humans intervene in live workflows to review, validate, or override outputs. It prioritizes output reliability, transparency, and compliance during deployment.
You can use both. Active Learning helps you build a better initial model with fewer resources. HITL ensures that model behaves safely and correctly once it faces real users. Think of Active Learning as studying for the exam, and HITL as having a supervisor check your work on the job.
Implementation Checklist for Enterprise Teams
Ready to build your workflow? Start with these concrete steps to ensure success and avoid common pitfalls.
- Define Error Thresholds. Clearly specify what constitutes an "error" or "uncertainty." Is it a factual hallucination? A tone mismatch? A missing citation? Ambiguity here leads to inconsistent reviews.
- Establish Risk Triggers. Determine which topics or confidence scores warrant escalation. High-risk topics should always trigger HITL, regardless of model confidence.
- Standardize Reviewer Guidelines. Create detailed rubrics for reviewers. Consistency across reviewers is vital for generating clean training data. Use adjudication workflows where senior reviewers resolve disagreements between junior reviewers.
- Build Audit Trails. Ensure every human decision is logged. Include the original prompt, model output, human correction, and rationale. This supports compliance auditing and troubleshooting.
- Plan for Drift Detection. Monitor error rates over time. If human interventions spike unexpectedly, it indicates model drift or changing user behavior. Have rollback procedures ready.
- Incrementally Reduce Manual Review. If AI accuracy stabilizes above 95% in domain-specific tasks and human interventions fall below defined thresholds, gradually shift from HITL to HOTL. Never remove oversight entirely; reduce it strategically.
The Future: Distillation and Multi-Agent Systems
HITL is evolving beyond simple review gates. Emerging techniques include human-in-the-loop distillation, where HITL principles help compress knowledge from large state-of-the-art models into smaller, more efficient models. This makes AI cheaper to run and easier to control while retaining the nuance learned through human interaction.
Additionally, research into multi-agent LLM systems explores HITL capabilities in complex orchestration scenarios. Imagine multiple AI agents collaborating on a task, with humans stepping in only when consensus fails or ethical boundaries are approached. This represents the next frontier: scalable intelligence with embedded accountability.
How does HITL improve model accuracy over time?
HITL improves accuracy by converting human corrections into structured training data. When experts fix model errors, these fixes are fed back into the training pipeline. This allows the model to learn from its mistakes, reducing similar errors in future iterations and creating a continuous improvement cycle.
Is HITL too expensive for small businesses?
Not necessarily. By using a tiered validation approach, small businesses can reserve human review for only the highest-risk cases. Combining automated checks and LLM-as-a-judge filters reduces the volume of work requiring human attention, making HITL cost-effective even for limited budgets.
What industries benefit most from HITL?
Industries with high stakes for errors benefit most, including healthcare (clinical decision support), finance (investment recommendations), and law (document review). Any sector where regulatory compliance, safety, or significant financial loss is a concern should prioritize HITL workflows.
How do I know when to switch from HITL to HOTL?
Switch to HOTL when your model achieves stable accuracy above 95% in specific domains and human intervention rates drop below predefined thresholds. Maintain safety nets like drift monitoring and periodic audits to catch unexpected regressions without reviewing every output.
Can HITL help with regulatory compliance?
Yes. HITL provides essential audit trails, documenting who reviewed what, when, and why. This transparency helps meet regulatory requirements in high-risk sectors by proving that human oversight was applied to critical decisions, mitigating the "black box" problem of AI.
 Artificial Intelligence
Artificial Intelligence