

When we talk about Self-correction is the ability of a Large Language Model to review, identify errors in, and refine its own generated responses through structured feedback. This isn't about the model magically becoming smarter; it's about giving it a mirror and a set of rules to check its work. If you implement this correctly, you can slash structured output errors by 30-45% without ever touching a fine-tuning script.
The Three Ways LLMs Fix Their Own Mistakes
Not all correction methods are created equal. Depending on whether you need a quick fix or a bulletproof enterprise pipeline, you'll want to choose one of these three strategies.
Intrinsic Self-Correction
This is the "generate, then review" approach. It happens within a single interaction. You essentially tell the model: "Write the code, then double-check it against these requirements, and if something is wrong, rewrite the final version." It's lightweight and requires zero extra training. While it adds a bit of latency-usually about 15-25% more processing time-it's incredibly effective for schema validation. For example, asking a model to produce a JSON response and then verify it against a specific schema can solve the majority of formatting errors.
Multi-Turn Feedback Correction
Think of this as a conversation where you interrupt the model. Instead of starting over, you provide a targeted hint: "The response was incomplete at line 12. Please continue and correct the logic from that point." This method is a lifesaver for real-time applications, recovering roughly 76-89% of interrupted response streams. It treats the error as a pause rather than a failure, keeping the context intact while steering the model back on track.
Feedback-Triggered Regeneration (FTR)
This is the cutting edge. Feedback-Triggered Regeneration
is a sophisticated framework that only triggers a rewrite when a specific dissatisfaction signal-either from a user or an automated system-is detected. Unlike basic prompts that always check for errors, FTR uses advanced decoding methods like Long-Term Multipath (LTM) decoding to avoid unnecessary corrections. This reduces wasted tokens and processing time by about 41% compared to standard methods.| Method | Primary Use Case | Latency Impact | Effectiveness (Reasoning) |
|---|---|---|---|
| Intrinsic | JSON/XML Schema Validation | Low (15-25%) | Low (22-35%) |
| Multi-Turn | Chatbots & Live Streams | Medium | Medium |
| FTR | Enterprise APIs & High-Stakes Logic | Optimized | High (78.3% on GSM8K) |
Where Self-Correction Actually Works (And Where It Fails)
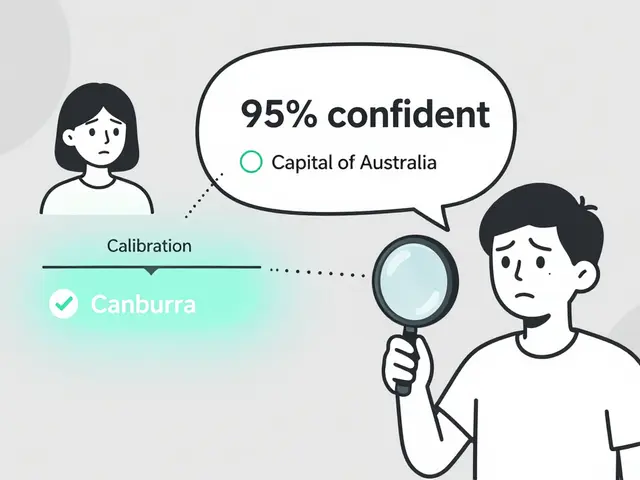
It is a mistake to think that self-correction is a silver bullet. If you ask a model to "fact-check itself" on a general knowledge question, you're likely to be disappointed. Research shows that self-correction fails in 83-92% of general knowledge tasks when the model only has its own internal logic to rely on. Why? Because if the model believes a false fact, it will likely believe that same false fact during the correction phase.
However, the game changes when you introduce External Validation Signals
objective data points from outside the LLM, such as compiler errors, unit tests, or mathematical verification tools. When the model is told, "Your code produced a SyntaxError at line 4," the success rate jumps to 76-88%. The model doesn't need to "know" the answer; it just needs to react to the external signal. This makes self-correction a powerhouse for code generation and math, but nearly useless for open-ended creative writing where there is no "correct" answer to validate against.
The Danger of Solution Drift
Here is a warning for those of you refining your prompts: watch out for "prompt-induced solution drift." This happens when a correction prompt is too vague or aggressive, inadvertently pushing the model away from a correct answer it already had. In some cases, up to 52% of models might actually ruin a perfectly good response because they were told to "improve" it without specific criteria.
To avoid this, don't use vague instructions like "make this better." Instead, use concrete validation criteria. Instead of "Check for errors," try "Verify that the JSON contains exactly four keys: id, name, date, and status. If any are missing, add them using null values." The more specific the feedback, the less likely the model is to drift into nonsense.

Building Your Correction Pipeline: A Practical Blueprint
If you're deploying this in a production environment, you can't just wing it. You need a structured approach. Most successful implementations follow a three-part architecture:
- Initial Generation: The model produces the first draft based on the user's request.
- Explicit Validation: A second pass (either by the same model or a smaller, faster one) checks the output against a set of hard rules (e.g., "Does this match the regex for an email address?").
- Correction Command: If validation fails, the model receives the specific error and is told to rewrite only the problematic section.
A pro tip from the field: limit your iterations. Don't let a model loop forever trying to fix a mistake. The sweet spot is usually 2-3 iterations. After that, you risk "error amplification," where the model starts hallucinating new problems just to satisfy the prompt to "fix something." If it can't solve it in three tries, it's time to trigger a fallback-perhaps switching to a different model provider entirely to get a fresh perspective.
The Future of Reliable AI
We are moving away from the era of "one-shot prompting." The industry is shifting toward multi-stage frameworks. Large providers are already baking this in; for instance, updates to GPT-4o and Llama 3.2 have focused heavily on structured output and self-reflection. By 2027, most enterprise AI won't just give you an answer; it will run a background check on that answer before it ever hits your screen.
Does self-correction make the LLM slower?
Yes, it does. Because you are essentially asking the model to process the text multiple times, you can expect an increase in latency. Intrinsic correction typically adds about 15-25% more time per request. However, for many developers, this is a worthwhile trade-off compared to the cost of a broken API call or a crashed application.
Can I use self-correction for factual accuracy?
Only if you provide external data. If you ask an LLM to "double-check your facts" using only its own memory, it will likely repeat the same hallucination. To fix factual errors, you must feed the model a trusted source (like a documentation snippet or a database result) and ask it to reconcile its answer with that specific evidence.
What is the best prompt structure for self-correction?
The most effective prompts use a three-step sequence: 1. Generate the output. 2. Validate against a specific checklist (e.g., "Check if the total sum equals 100"). 3. Correct only the identified discrepancies. Avoid vague terms like "improve" or "fix," and instead use "correct the mismatch in the [specific field]."
What is the difference between FTR and standard self-correction?
Standard self-correction often happens every time, regardless of whether the first answer was correct. Feedback-Triggered Regeneration (FTR) only activates when there is a clear signal of failure, such as a user clicking "thumbs down" or a validation script failing. This makes FTR much more efficient and reduces unnecessary token spend.
How many times should I let a model self-correct?
Limit your cycles to 2 or 3 iterations. Beyond this point, the risk of "error amplification" increases, where the model begins to introduce new mistakes or deviate wildly from the original intent (solution drift). If it's not fixed by the third attempt, it's better to route the request to a human or a more powerful model.
 Artificial Intelligence
Artificial Intelligence


Elmer Burgos
April 19, 2026 AT 22:11this is a really cool way to look at it, i think it helps everyone get better results without feeling frustrated
Sally McElroy
April 20, 2026 AT 04:59The obsession with efficiency is truly a symptom of our spiritual decay...!!! We are teaching machines to mimic a truth they can never actually possess...!!! It is a hollow victory to have a JSON object that doesn't break when the human soul is the one that is fragmented...!!!
Sara Escanciano
April 20, 2026 AT 05:27It is absolutely disgusting that we are spending this much engineering effort on making AI "confidently" lie better. This isn't a "blueprint," it's a manual for systemic deception. We should be focusing on transparency instead of building a "background check" that hides the model's incompetence from the end user. Absolutely pathetic.
Destiny Brumbaugh
April 20, 2026 AT 23:38USA DOES IT BEST!!! We got the best chips and the best coders so we will aways win this AI race!! dont let any other country catch up to our tech!!! MERICA!!!
Antwan Holder
April 21, 2026 AT 11:40My soul weeps for the death of the first draft! We have entered a purgatory of endless iterations where the raw, bleeding edge of creativity is sanitized by a feedback loop of cold, calculating logic!
Imagine the tragedy of a thought that was almost perfect, only to be dragged down into the abyss of "solution drift" by a prompt that demanded it be "better." It is an existential nightmare! We are not just refining code; we are murdering the ghost in the machine one correction at a time! I can feel the void staring back through the LTM decoding and it is utterly devastating to behold!