

Imagine deploying a customer service chatbot that accidentally reveals sensitive employee data because it was trained on internal documents. Or consider a hiring tool that systematically downgrades resumes from specific demographic groups due to hidden biases in its training data. These aren't just hypothetical nightmares; they are real risks facing organizations today. As of 2026, nearly 70 percent of companies have integrated Large Language Models (LLMs) into their operations. But with this rapid adoption comes a critical challenge: how do we ensure these powerful systems don't cause harm?
Risk assessment for LLM projects is no longer optional ethics homework. It has become a core operational discipline. Whether you are building a healthcare diagnostic aid or a financial analysis tool, understanding where your model could fail-and what happens if it does-is essential. This guide breaks down how to conduct thorough risk assessments and draft effective impact statements, ensuring your AI projects are safe, fair, and compliant.
Understanding the Landscape of LLM Risks
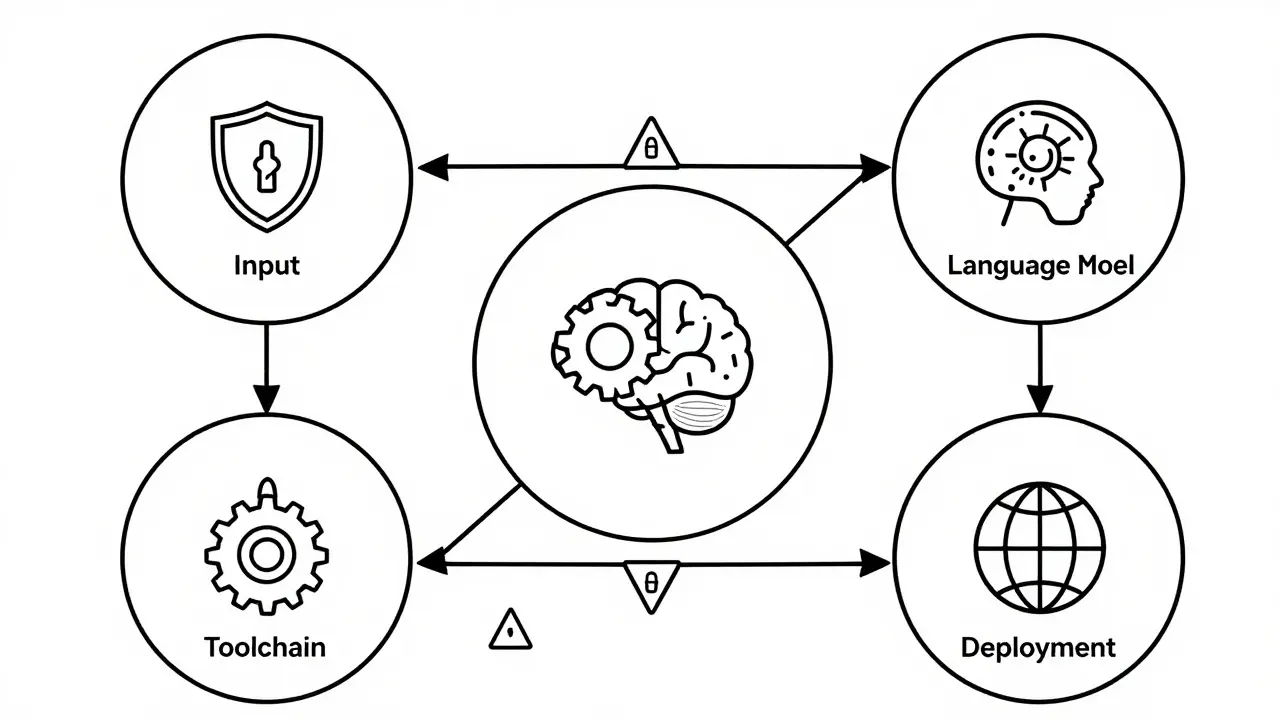
To manage risk, you first need to understand what you are up against. The MIT AI Risk Repository, updated in 2024, categorizes LLM risks into four distinct modules. Think of these as the different layers of your system where things can go wrong.
| Module | Key Risks | Example Scenario |
|---|---|---|
| Input Module | NSFW Prompts, Adversarial Attacks | A user inputs a carefully crafted prompt to trick the model into revealing admin credentials. |
| Language Model Module | Privacy Leakage, Bias, Hallucinations | The model generates a medical recommendation that sounds plausible but is factually incorrect. |
| Toolchain Module | Software Security, Hardware Vulnerabilities | A third-party API used by the model leaks user data due to poor encryption. |
| Deployment Module | Malicious Misuse, System Availability | Attackers exploit the public interface to launch automated spam campaigns. |
Let's look closer at the most dangerous culprits. Hallucinations occur when the model confabulates facts. In a legal context, this could mean citing a case law that doesn't exist. Privacy Leakage is equally severe. Research indicates that approximately 5 percent of training data for major models like GPT-4 contains sensitive information. If your model memorized this data, it might regurgitate personal details during a conversation. Then there is Bias and Toxicity. Since LLMs learn from vast internet datasets, they absorb societal stereotypes. Without intervention, your model might replicate discriminatory language or unfair judgments.
Quantifying Threats: A Practical Framework
Identifying risks is step one. Quantifying them is step two. You can't protect against everything equally, so you need a way to prioritize. Researchers at Hainan University proposed a quantitative threat assessment methodology that is surprisingly practical for enterprise use.
They suggest calculating a Threat Level (T) using this formula:
T = 0.6 × Frequency + 0.4 × Stealth
Here, Frequency refers to how often an attack type occurs in the wild, and Stealth measures how hard it is to detect. A high-frequency, low-stealth attack (like basic prompt injection) might be easier to block than a low-frequency, high-stealth attack (like a subtle data exfiltration attempt). By scoring your potential vulnerabilities this way, you can allocate resources to the threats that matter most.
Additionally, consider the Impact Scope. Ask yourself: Does this risk affect data leakage? Does it introduce model bias? Does it threaten system availability? For example, a hallucination in a creative writing app has low impact scope. The same hallucination in a radiology report has catastrophic impact scope. Your risk assessment must weigh both likelihood and consequence.
Drafting Effective Impact Statements
An Impact Statement is not just a compliance document; it is a communication tool. It tells stakeholders-investors, regulators, and users-what you know about your model's limitations. Here is how to structure it effectively.
- Define the Use Case Clearly: Specify exactly what the model is designed to do. Is it summarizing news articles? Diagnosing skin conditions? Clarity prevents misuse.
- Disclose Data Provenance: Explain where the training data came from. Did you use public web crawls? Internal company documents? Anonymized patient records? Transparency builds trust.
- Highlight Known Biases: Be honest about demographic or cultural biases present in your model. If your model performs worse on non-native English speakers, state that clearly. This allows users to apply appropriate caution.
- Outline Mitigation Strategies: Describe the guardrails you have in place. Do you use Retrieval-Augmented Generation (RAG) to ground answers in verified sources? Do you have human-in-the-loop reviews for high-stakes decisions?
- Provide Feedback Mechanisms: Tell users how to report errors or harmful outputs. Continuous improvement requires user input.
For instance, if you are deploying an HR screening tool, your impact statement should explicitly mention that the model is a decision-support aid, not a final decision-maker. It should also disclose any historical biases in the resume data used for training and explain how you mitigated them through re-weighting or adversarial debiasing techniques.
Mitigation Strategies That Actually Work
Knowing the risks is useless without solutions. Here are three proven strategies to reduce LLM risks in production.
1. Retrieval-Augmented Generation (RAG)
RAG is your best defense against hallucinations. Instead of relying solely on the model's internal memory, RAG retrieves relevant information from a vetted, access-controlled knowledge base before generating a response. This creates an auditable trail. If the model makes a mistake, you can trace it back to the source document. It also ensures that your model only uses approved information, reducing privacy leakage risks.
2. Continuous Monitoring and Drift Detection
Models degrade over time. User behavior changes, new slang emerges, and attackers find new exploits. According to ISO/IEC 42001 standards, you must monitor your AI system continuously. Set up alerts for behavior drift. If your model suddenly starts generating more toxic content or refusing benign requests, something is wrong. Tools like Deepchecks help automate this monitoring, flagging anomalies before they become crises.
3. Hierarchical Defense Systems
Don't rely on a single layer of protection. Implement a multi-layered approach:
- Input Filtering: Block NSFW or adversarial prompts before they reach the model.
- Model Guardrails: Use fine-tuning or reinforcement learning to discourage harmful outputs.
- Output Validation: Scan generated text for toxicity, PII (Personally Identifiable Information), or factual inaccuracies before showing it to the user.
Navigating Regulatory Compliance
In 2026, the regulatory landscape for AI is tightening. The European Union's AI Act and similar frameworks in other regions require rigorous risk management. The European Data Protection Board (EDPB) has issued specific guidelines for LLMs, emphasizing privacy by design. Key requirements include:
- Data minimization: Only train on necessary data.
- User consent: Ensure users know their data might be used for training.
- Right to explanation: Provide clear reasons for automated decisions.
Common Pitfalls to Avoid
Even experienced teams make mistakes. Here are three common pitfalls in LLM risk assessment:
- Over-relying on Benchmarks: Standard benchmarks like MMLU or GLUE measure general capability, not safety. A model can score high on reasoning tests while still being prone to jailbreaks. Always supplement benchmarks with red-teaming exercises.
- Ignoring Contextual Nuance: A joke might be harmless in one culture but offensive in another. Your risk assessment must consider the cultural context of your target audience.
- Assuming Static Risk: Risks evolve. New attack vectors emerge weekly. Your risk assessment should be a living document, reviewed and updated regularly.
Remember, as Amir Feizpour, CEO of AI Science, notes, LLMs are "as unbiased and objective as their designers." If your team lacks diversity, your risk assessment will likely miss blind spots. Involve cross-functional teams-including ethicists, legal experts, and end-users-in the evaluation process.
Next Steps for Your Project
Start small. Pick one high-risk feature of your LLM project and conduct a focused risk assessment. Map out the input, model, and output stages. Identify potential failure points. Then, draft a concise impact statement for that feature. Iterate and expand as your project grows.
Use tools available today to automate parts of this process. Red-teaming datasets, such as those from Anthropic, can help you stress-test your model against known attack patterns. Integrate continuous monitoring into your CI/CD pipeline. And always, always keep the human in the loop for critical decisions.
Risk assessment isn't about stopping innovation. It's about enabling responsible innovation. By understanding and mitigating risks, you build trust with your users and secure the long-term viability of your AI initiatives.
What is the difference between a risk assessment and an impact statement for LLMs?
A risk assessment is an internal process to identify, quantify, and mitigate potential harms caused by the model. An impact statement is an external-facing document that communicates these risks, limitations, and mitigation strategies to stakeholders, users, and regulators. The assessment informs the statement.
How do I calculate the threat level of an LLM vulnerability?
You can use the formula T = 0.6 × Frequency + 0.4 × Stealth. Frequency refers to how often the attack occurs, and Stealth refers to how difficult it is to detect. This helps prioritize which vulnerabilities to address first based on their likelihood and隐蔽性 (stealthiness).
Is Retrieval-Augmented Generation (RAG) enough to prevent hallucinations?
RAG significantly reduces hallucinations by grounding responses in verified sources, but it is not a silver bullet. Errors can still occur if the retrieved documents are inaccurate or if the model misinterprets the context. Combine RAG with output validation and human review for high-stakes applications.
What are the key components of the MIT AI Risk Repository framework?
The framework categorizes risks into four modules: Input (e.g., adversarial prompts), Language Model (e.g., bias, hallucinations), Toolchain (e.g., software security), and Deployment (e.g., malicious misuse). It provides a structured way to audit every part of the LLM system.
How does ISO/IEC 42001 relate to LLM risk assessment?
ISO/IEC 42001 is an international standard for AI management systems. It mandates continuous monitoring, risk assessment, and ethical considerations throughout the AI lifecycle. Compliance demonstrates that your organization has robust governance practices in place.
 Artificial Intelligence
Artificial Intelligence




