
Tag: LLM serving
Learn how to choose optimal batch sizes for LLM serving to cut cost per token by up to 87%. Discover real-world results, batching types, hardware trade-offs, and proven techniques to reduce AI infrastructure costs.
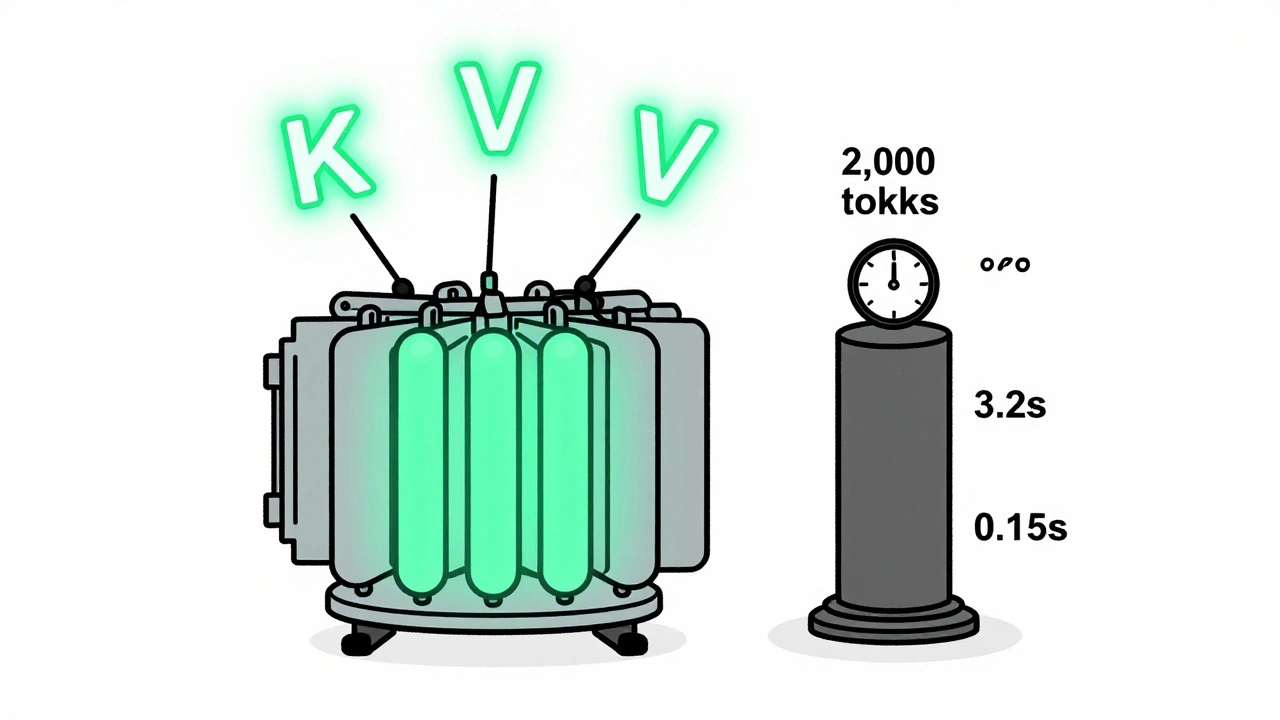
KV caching and continuous batching are essential for fast, affordable LLM serving. Learn how they reduce memory use, boost throughput, and enable real-world deployment on consumer hardware.
Categories
 Artificial Intelligence
Artificial Intelligence
Archives
Recent-posts
Combining Pruning and Quantization for Maximum LLM Speedups
Mar, 3 2026

How Domain Experts Turn Spreadsheets into Applications with Vibe Coding
Feb, 18 2026
State Management Choices in AI-Generated Frontends: Pitfalls and Fixes
Mar, 12 2026

Testing Vibe-Coded Architectures: A Guide to Unit, Contract, and E2E Strategies
Jun, 1 2026
Practical Applications of Generative AI: A 2026 Industry Guide
Mar, 30 2026